 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAS-PromptBench: When Does Prompt Optimization Improve Multi-Agent LLM Systems?
Jun 22, 2026Multi-agent systems (MAS) offer a scalable path forward for agentic AI, comprising multiple LLM-based agents, each assigned a system prompt and a position within a workflow that governs inter-agent coordination and output aggregation. System prompts thus form a critical and accessible optimization surface: they specify agents' roles and behaviors, enabling system-level improvements without model finetuning. Although prompt optimization has shown substantial potential for single LLMs, extending it to MAS poses distinct challenges, notably an exponentially growing search space. It remains unclear whether, when, and by how much prompt optimization improves MAS performance, and how sensitive such gains are to system configuration. In this work, we systematically study system-prompt optimization across a broad range of MAS setups varying in task, workflow, communication protocol, and team size, benchmarking two prompt optimizers that naturally extend state-of-the-art single-agent methods. The results reveal its potential to unlock significant gains while exposing open challenges, characterizing when and how much prompt optimization helps across diverse MAS settings.
T2S-MPC: Time-Embedded Online Adaptive Model Predictive Control for Time-Varying Dynamics
May 24, 2026Recent advances in learning-based model predictive control (MPC) have leveraged neural networks for online model learning, achieving strong performance when nonstationary system dynamics deviate from nominal models. However, existing approaches primarily address specific or relatively structured forms of dynamical variation, leaving more general, unknown, and unpredictable time-varying dynamics insufficiently handled. To tackle this challenge, we propose T2S-MPC, a framework that adaptively learns a residual dynamics model online and integrates it with the nominal model within the MPC framework to enable fast-evolving online planning. To make the model time-aware, we explicitly encode temporal information through a structured time embedding and employ a two-timescale update scheme, allowing the controller to capture nonstationary dynamics while balancing rapid adaptation with stable learning. We evaluate the proposed method on a 2D quadrotor across stabilization and trajectory tracking tasks under diverse time-varying disturbances, including linear drifting and periodic perturbations. Experimental results show that T2S-MPC consistently outperforms classical MPC, neural MPC, and ablated variants in control performance, while also demonstrating strong robustness across a wide range of disturbance conditions without additional tuning. The source code is publicly available at https://github.com/Zeyuu0920/T2S_MPC
Taming the Curses of Multiagency in Robust Markov Games with Large State Space through Linear Function Approximation
May 04, 2026Multi-agent reinforcement learning (MARL) holds great potential but faces robustness challenges due to environmental uncertainty. To address this, distributionally robust Markov games (RMGs) optimize worst-case performance when the environment deviates from the nominal model within a uncertainty set. Beyond robustness, an equally urgent goal for MARL is data efficiency -- sampling from vast state and action spaces that grow exponentially with the number of agents potentially leads to the curse of multiagency. However, current provably data-efficient algorithms for RMGs are limited to tabular settings with finite state and action spaces, which are only computationally manageable for small-scale problems, leaving RMGs with large-scale (or infinite) state spaces largely unexplored. The only existing work beyond tabular settings focuses on linear function approximation (LFA) for a restrictive class of RMGs using vanish minimal value assumption and still suffers from sample complexity with the curse of multiagency. In this work, we focuses on general RMGs with LFA. For uncertainty sets defined by total variation distance, we develop provably data-efficient algorithms that break the curse of multiagency in both the generative model setting and a newly proposed online interactive setting. To our knowledge, our results are the first to break the curse of multiagency of sample complexity for RMGs with large (possibly infinite) state spaces, regardless of the uncertainty set construction.
Pushing Forward Pareto Frontiers of Proactive Agents with Behavioral Agentic Optimization
Feb 11, 2026Proactive large language model (LLM) agents aim to actively plan, query, and interact over multiple turns, enabling efficient task completion beyond passive instruction following and making them essential for real-world, user-centric applications. Agentic reinforcement learning (RL) has recently emerged as a promising solution for training such agents in multi-turn settings, allowing interaction strategies to be learned from feedback. However, existing pipelines face a critical challenge in balancing task performance with user engagement, as passive agents can not efficiently adapt to users' intentions while overuse of human feedback reduces their satisfaction. To address this trade-off, we propose BAO, an agentic RL framework that combines behavior enhancement to enrich proactive reasoning and information-gathering capabilities with behavior regularization to suppress inefficient or redundant interactions and align agent behavior with user expectations. We evaluate BAO on multiple tasks from the UserRL benchmark suite, and demonstrate that it substantially outperforms proactive agentic RL baselines while achieving comparable or even superior performance to commercial LLM agents, highlighting its effectiveness for training proactive, user-aligned LLM agents in complex multi-turn scenarios. Our website: https://proactive-agentic-rl.github.io/.
Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity
Feb 03, 2026LLM-based multi-agent systems (MAS) have emerged as a promising approach to tackle complex tasks that are difficult for individual LLMs. A natural strategy is to scale performance by increasing the number of agents; however, we find that such scaling exhibits strong diminishing returns in homogeneous settings, while introducing heterogeneity (e.g., different models, prompts, or tools) continues to yield substantial gains. This raises a fundamental question: what limits scaling, and why does diversity help? We present an information-theoretic framework showing that MAS performance is bounded by the intrinsic task uncertainty, not by agent count. We derive architecture-agnostic bounds demonstrating that improvements depend on how many effective channels the system accesses. Homogeneous agents saturate early because their outputs are strongly correlated, whereas heterogeneous agents contribute complementary evidence. We further introduce $K^*$, an effective channel count that quantifies the number of effective channels without ground-truth labels. Empirically, we show that heterogeneous configurations consistently outperform homogeneous scaling: 2 diverse agents can match or exceed the performance of 16 homogeneous agents. Our results provide principled guidelines for building efficient and robust MAS through diversity-aware design. Code and Dataset are available at the link: https://github.com/SafeRL-Lab/Agent-Scaling.
MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning
May 30, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a powerful paradigm for post-training large language models (LLMs), achieving state-of-the-art performance on tasks with structured, verifiable answers. Applying RLVR to Multimodal LLMs (MLLMs) presents significant opportunities but is complicated by the broader, heterogeneous nature of vision-language tasks that demand nuanced visual, logical, and spatial capabilities. As such, training MLLMs using RLVR on multiple datasets could be beneficial but creates challenges with conflicting objectives from interaction among diverse datasets, highlighting the need for optimal dataset mixture strategies to improve generalization and reasoning. We introduce a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. Specifically, (1) We developed a multimodal RLVR framework for multi-dataset post-training by curating a dataset that contains different verifiable vision-language problems and enabling multi-domain online RL learning with different verifiable rewards; (2) We proposed a data mixture strategy that learns to predict the RL fine-tuning outcome from the data mixture distribution, and consequently optimizes the best mixture. Comprehensive experiments showcase that multi-domain RLVR training, when combined with mixture prediction strategies, can significantly boost MLLM general reasoning capacities. Our best mixture improves the post-trained model's accuracy on out-of-distribution benchmarks by an average of 5.24% compared to the same model post-trained with uniform data mixture, and by a total of 20.74% compared to the pre-finetuning baseline.
KL-regularization Itself is Differentially Private in Bandits and RLHF
May 23, 2025Differential Privacy (DP) provides a rigorous framework for privacy, ensuring the outputs of data-driven algorithms remain statistically indistinguishable across datasets that differ in a single entry. While guaranteeing DP generally requires explicitly injecting noise either to the algorithm itself or to its outputs, the intrinsic randomness of existing algorithms presents an opportunity to achieve DP ``for free''. In this work, we explore the role of regularization in achieving DP across three different decision-making problems: multi-armed bandits, linear contextual bandits, and reinforcement learning from human feedback (RLHF), in offline data settings. We show that adding KL-regularization to the learning objective (a common approach in optimization algorithms) makes the action sampled from the resulting stochastic policy itself differentially private. This offers a new route to privacy guarantees without additional noise injection, while also preserving the inherent advantage of regularization in enhancing performance.
Robust Gymnasium: A Unified Modular Benchmark for Robust Reinforcement Learning
Feb 27, 2025



Driven by inherent uncertainty and the sim-to-real gap, robust reinforcement learning (RL) seeks to improve resilience against the complexity and variability in agent-environment sequential interactions. Despite the existence of a large number of RL benchmarks, there is a lack of standardized benchmarks for robust RL. Current robust RL policies often focus on a specific type of uncertainty and are evaluated in distinct, one-off environments. In this work, we introduce Robust-Gymnasium, a unified modular benchmark designed for robust RL that supports a wide variety of disruptions across all key RL components-agents' observed state and reward, agents' actions, and the environment. Offering over sixty diverse task environments spanning control and robotics, safe RL, and multi-agent RL, it provides an open-source and user-friendly tool for the community to assess current methods and foster the development of robust RL algorithms. In addition, we benchmark existing standard and robust RL algorithms within this framework, uncovering significant deficiencies in each and offering new insights.
Hybrid Transfer Reinforcement Learning: Provable Sample Efficiency from Shifted-Dynamics Data
Nov 06, 2024
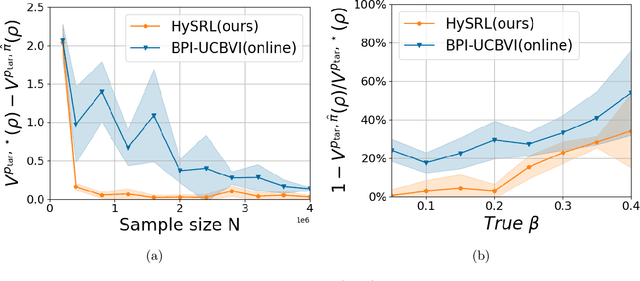
Online Reinforcement learning (RL) typically requires high-stakes online interaction data to learn a policy for a target task. This prompts interest in leveraging historical data to improve sample efficiency. The historical data may come from outdated or related source environments with different dynamics. It remains unclear how to effectively use such data in the target task to provably enhance learning and sample efficiency. To address this, we propose a hybrid transfer RL (HTRL) setting, where an agent learns in a target environment while accessing offline data from a source environment with shifted dynamics. We show that -- without information on the dynamics shift -- general shifted-dynamics data, even with subtle shifts, does not reduce sample complexity in the target environment. However, with prior information on the degree of the dynamics shift, we design HySRL, a transfer algorithm that achieves problem-dependent sample complexity and outperforms pure online RL. Finally, our experimental results demonstrate that HySRL surpasses state-of-the-art online RL baseline.
Can We Break the Curse of Multiagency in Robust Multi-Agent Reinforcement Learning?
Sep 30, 2024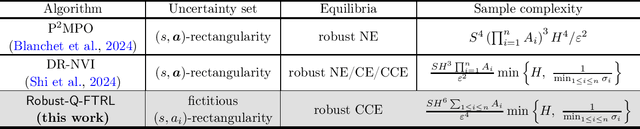
Standard multi-agent reinforcement learning (MARL) algorithms are vulnerable to sim-to-real gaps. To address this, distributionally robust Markov games (RMGs) have been proposed to enhance robustness in MARL by optimizing the worst-case performance when game dynamics shift within a prescribed uncertainty set. Solving RMGs remains under-explored, from problem formulation to the development of sample-efficient algorithms. A notorious yet open challenge is if RMGs can escape the curse of multiagency, where the sample complexity scales exponentially with the number of agents. In this work, we propose a natural class of RMGs where the uncertainty set of each agent is shaped by both the environment and other agents' strategies in a best-response manner. We first establish the well-posedness of these RMGs by proving the existence of game-theoretic solutions such as robust Nash equilibria and coarse correlated equilibria (CCE). Assuming access to a generative model, we then introduce a sample-efficient algorithm for learning the CCE whose sample complexity scales polynomially with all relevant parameters. To the best of our knowledge, this is the first algorithm to break the curse of multiagency for RMGs.