 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategically Robust Multi-Agent Reinforcement Learning with Linear Function Approximation
Mar 10, 2026Provably efficient and robust equilibrium computation in general-sum Markov games remains a core challenge in multi-agent reinforcement learning. Nash equilibrium is computationally intractable in general and brittle due to equilibrium multiplicity and sensitivity to approximation error. We study Risk-Sensitive Quantal Response Equilibrium (RQRE), which yields a unique, smooth solution under bounded rationality and risk sensitivity. We propose \texttt{RQRE-OVI}, an optimistic value iteration algorithm for computing RQRE with linear function approximation in large or continuous state spaces. Through finite-sample regret analysis, we establish convergence and explicitly characterize how sample complexity scales with rationality and risk-sensitivity parameters. The regret bounds reveal a quantitative tradeoff: increasing rationality tightens regret, while risk sensitivity induces regularization that enhances stability and robustness. This exposes a Pareto frontier between expected performance and robustness, with Nash recovered in the limit of perfect rationality and risk neutrality. We further show that the RQRE policy map is Lipschitz continuous in estimated payoffs, unlike Nash, and RQRE admits a distributionally robust optimization interpretation. Empirically, we demonstrate that \texttt{RQRE-OVI} achieves competitive performance under self-play while producing substantially more robust behavior under cross-play compared to Nash-based approaches. These results suggest \texttt{RQRE-OVI} offers a principled, scalable, and tunable path for equilibrium learning with improved robustness and generalization.
Training Generalizable Collaborative Agents via Strategic Risk Aversion
Feb 25, 2026Many emerging agentic paradigms require agents to collaborate with one another (or people) to achieve shared goals. Unfortunately, existing approaches to learning policies for such collaborative problems produce brittle solutions that fail when paired with new partners. We attribute these failures to a combination of free-riding during training and a lack of strategic robustness. To address these problems, we study the concept of strategic risk aversion and interpret it as a principled inductive bias for generalizable cooperation with unseen partners. While strategically risk-averse players are robust to deviations in their partner's behavior by design, we show that, in collaborative games, they also (1) can have better equilibrium outcomes than those at classical game-theoretic concepts like Nash, and (2) exhibit less or no free-riding. Inspired by these insights, we develop a multi-agent reinforcement learning (MARL) algorithm that integrates strategic risk aversion into standard policy optimization methods. Our empirical results across collaborative benchmarks (including an LLM collaboration task) validate our theory and demonstrate that our approach consistently achieves reliable collaboration with heterogeneous and previously unseen partners across collaborative tasks.
Provably Convergent Actor-Critic in Risk-averse MARL
Feb 12, 2026Learning stationary policies in infinite-horizon general-sum Markov games (MGs) remains a fundamental open problem in Multi-Agent Reinforcement Learning (MARL). While stationary strategies are preferred for their practicality, computing stationary forms of classic game-theoretic equilibria is computationally intractable -- a stark contrast to the comparative ease of solving single-agent RL or zero-sum games. To bridge this gap, we study Risk-averse Quantal response Equilibria (RQE), a solution concept rooted in behavioral game theory that incorporates risk aversion and bounded rationality. We demonstrate that RQE possesses strong regularity conditions that make it uniquely amenable to learning in MGs. We propose a novel two-timescale Actor-Critic algorithm characterized by a fast-timescale actor and a slow-timescale critic. Leveraging the regularity of RQE, we prove that this approach achieves global convergence with finite-sample guarantees. We empirically validate our algorithm in several environments to demonstrate superior convergence properties compared to risk-neutral baselines.
Distributionally Robust Cooperative Multi-Agent Reinforcement Learning via Robust Value Factorization
Feb 11, 2026Cooperative multi-agent reinforcement learning (MARL) commonly adopts centralized training with decentralized execution, where value-factorization methods enforce the individual-global-maximum (IGM) principle so that decentralized greedy actions recover the team-optimal joint action. However, the reliability of this recipe in real-world settings remains unreliable due to environmental uncertainties arising from the sim-to-real gap, model mismatch, and system noise. We address this gap by introducing Distributionally robust IGM (DrIGM), a principle that requires each agent's robust greedy action to align with the robust team-optimal joint action. We show that DrIGM holds for a novel definition of robust individual action values, which is compatible with decentralized greedy execution and yields a provable robustness guarantee for the whole system. Building on this foundation, we derive DrIGM-compliant robust variants of existing value-factorization architectures (e.g., VDN/QMIX/QTRAN) that (i) train on robust Q-targets, (ii) preserve scalability, and (iii) integrate seamlessly with existing codebases without bespoke per-agent reward shaping. Empirically, on high-fidelity SustainGym simulators and a StarCraft game environment, our methods consistently improve out-of-distribution performance. Code and data are available at https://github.com/crqu/robust-coMARL.
Learning to Steer Learners in Games
Feb 28, 2025We consider the problem of learning to exploit learning algorithms through repeated interactions in games. Specifically, we focus on the case of repeated two player, finite-action games, in which an optimizer aims to steer a no-regret learner to a Stackelberg equilibrium without knowledge of its payoffs. We first show that this is impossible if the optimizer only knows that the learner is using an algorithm from the general class of no-regret algorithms. This suggests that the optimizer requires more information about the learner's objectives or algorithm to successfully exploit them. Building on this intuition, we reduce the problem for the optimizer to that of recovering the learner's payoff structure. We demonstrate the effectiveness of this approach if the learner's algorithm is drawn from a smaller class by analyzing two examples: one where the learner uses an ascent algorithm, and another where the learner uses stochastic mirror ascent with known regularizer and step sizes.
Robust Gymnasium: A Unified Modular Benchmark for Robust Reinforcement Learning
Feb 27, 2025



Driven by inherent uncertainty and the sim-to-real gap, robust reinforcement learning (RL) seeks to improve resilience against the complexity and variability in agent-environment sequential interactions. Despite the existence of a large number of RL benchmarks, there is a lack of standardized benchmarks for robust RL. Current robust RL policies often focus on a specific type of uncertainty and are evaluated in distinct, one-off environments. In this work, we introduce Robust-Gymnasium, a unified modular benchmark designed for robust RL that supports a wide variety of disruptions across all key RL components-agents' observed state and reward, agents' actions, and the environment. Offering over sixty diverse task environments spanning control and robotics, safe RL, and multi-agent RL, it provides an open-source and user-friendly tool for the community to assess current methods and foster the development of robust RL algorithms. In addition, we benchmark existing standard and robust RL algorithms within this framework, uncovering significant deficiencies in each and offering new insights.
Can We Break the Curse of Multiagency in Robust Multi-Agent Reinforcement Learning?
Sep 30, 2024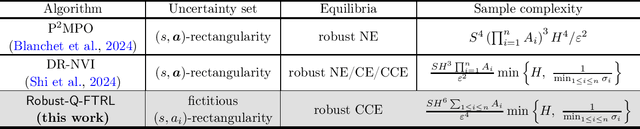
Standard multi-agent reinforcement learning (MARL) algorithms are vulnerable to sim-to-real gaps. To address this, distributionally robust Markov games (RMGs) have been proposed to enhance robustness in MARL by optimizing the worst-case performance when game dynamics shift within a prescribed uncertainty set. Solving RMGs remains under-explored, from problem formulation to the development of sample-efficient algorithms. A notorious yet open challenge is if RMGs can escape the curse of multiagency, where the sample complexity scales exponentially with the number of agents. In this work, we propose a natural class of RMGs where the uncertainty set of each agent is shaped by both the environment and other agents' strategies in a best-response manner. We first establish the well-posedness of these RMGs by proving the existence of game-theoretic solutions such as robust Nash equilibria and coarse correlated equilibria (CCE). Assuming access to a generative model, we then introduce a sample-efficient algorithm for learning the CCE whose sample complexity scales polynomially with all relevant parameters. To the best of our knowledge, this is the first algorithm to break the curse of multiagency for RMGs.
Last-Iterate Convergence of Payoff-Based Independent Learning in Zero-Sum Stochastic Games
Sep 02, 2024
In this paper, we consider two-player zero-sum matrix and stochastic games and develop learning dynamics that are payoff-based, convergent, rational, and symmetric between the two players. Specifically, the learning dynamics for matrix games are based on the smoothed best-response dynamics, while the learning dynamics for stochastic games build upon those for matrix games, with additional incorporation of the minimax value iteration. To our knowledge, our theoretical results present the first finite-sample analysis of such learning dynamics with last-iterate guarantees. In the matrix game setting, the results imply a sample complexity of $O(\epsilon^{-1})$ to find the Nash distribution and a sample complexity of $O(\epsilon^{-8})$ to find a Nash equilibrium. In the stochastic game setting, the results also imply a sample complexity of $O(\epsilon^{-8})$ to find a Nash equilibrium. To establish these results, the main challenge is to handle stochastic approximation algorithms with multiple sets of coupled and stochastic iterates that evolve on (possibly) different time scales. To overcome this challenge, we developed a coupled Lyapunov-based approach, which may be of independent interest to the broader community studying the convergence behavior of stochastic approximation algorithms.
Tractable Equilibrium Computation in Markov Games through Risk Aversion
Jun 20, 2024A significant roadblock to the development of principled multi-agent reinforcement learning is the fact that desired solution concepts like Nash equilibria may be intractable to compute. To overcome this obstacle, we take inspiration from behavioral economics and show that -- by imbuing agents with important features of human decision-making like risk aversion and bounded rationality -- a class of risk-averse quantal response equilibria (RQE) become tractable to compute in all $n$-player matrix and finite-horizon Markov games. In particular, we show that they emerge as the endpoint of no-regret learning in suitably adjusted versions of the games. Crucially, the class of computationally tractable RQE is independent of the underlying game structure and only depends on agents' degree of risk-aversion and bounded rationality. To validate the richness of this class of solution concepts we show that it captures peoples' patterns of play in a number of 2-player matrix games previously studied in experimental economics. Furthermore, we give a first analysis of the sample complexity of computing these equilibria in finite-horizon Markov games when one has access to a generative model and validate our findings on a simple multi-agent reinforcement learning benchmark.
Model-Free Robust $φ$-Divergence Reinforcement Learning Using Both Offline and Online Data
May 08, 2024
The robust $\phi$-regularized Markov Decision Process (RRMDP) framework focuses on designing control policies that are robust against parameter uncertainties due to mismatches between the simulator (nominal) model and real-world settings. This work makes two important contributions. First, we propose a model-free algorithm called Robust $\phi$-regularized fitted Q-iteration (RPQ) for learning an $\epsilon$-optimal robust policy that uses only the historical data collected by rolling out a behavior policy (with robust exploratory requirement) on the nominal model. To the best of our knowledge, we provide the first unified analysis for a class of $\phi$-divergences achieving robust optimal policies in high-dimensional systems with general function approximation. Second, we introduce the hybrid robust $\phi$-regularized reinforcement learning framework to learn an optimal robust policy using both historical data and online sampling. Towards this framework, we propose a model-free algorithm called Hybrid robust Total-variation-regularized Q-iteration (HyTQ: pronounced height-Q). To the best of our knowledge, we provide the first improved out-of-data-distribution assumption in large-scale problems with general function approximation under the hybrid robust $\phi$-regularized reinforcement learning framework. Finally, we provide theoretical guarantees on the performance of the learned policies of our algorithms on systems with arbitrary large state space.