 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Exploitative Play with Untrusted Type Beliefs
Nov 12, 2024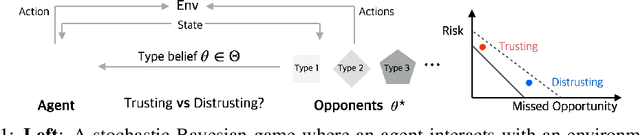

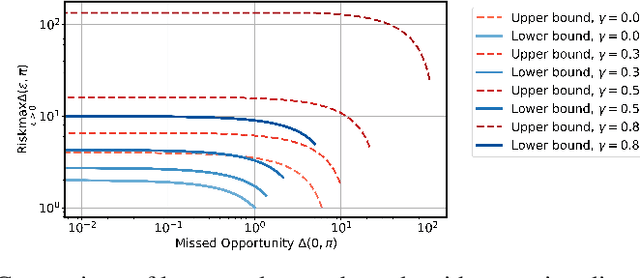

The combination of the Bayesian game and learning has a rich history, with the idea of controlling a single agent in a system composed of multiple agents with unknown behaviors given a set of types, each specifying a possible behavior for the other agents. The idea is to plan an agent's own actions with respect to those types which it believes are most likely to maximize the payoff. However, the type beliefs are often learned from past actions and likely to be incorrect. With this perspective in mind, we consider an agent in a game with type predictions of other components, and investigate the impact of incorrect beliefs to the agent's payoff. In particular, we formally define a tradeoff between risk and opportunity by comparing the payoff obtained against the optimal payoff, which is represented by a gap caused by trusting or distrusting the learned beliefs. Our main results characterize the tradeoff by establishing upper and lower bounds on the Pareto front for both normal-form and stochastic Bayesian games, with numerical results provided.
Rethinking Scaling Laws for Learning in Strategic Environments
Feb 21, 2024The deployment of ever-larger machine learning models reflects a growing consensus that the more expressive the model$\unicode{x2013}$and the more data one has access to$\unicode{x2013}$the more one can improve performance. As models get deployed in a variety of real world scenarios, they inevitably face strategic environments. In this work, we consider the natural question of how the interplay of models and strategic interactions affects scaling laws. We find that strategic interactions can break the conventional view of scaling laws$\unicode{x2013}$meaning that performance does not necessarily monotonically improve as models get larger and/ or more expressive (even with infinite data). We show the implications of this phenomenon in several contexts including strategic regression, strategic classification, and multi-agent reinforcement learning through examples of strategic environments in which$\unicode{x2013}$by simply restricting the expressivity of one's model or policy class$\unicode{x2013}$one can achieve strictly better equilibrium outcomes. Motivated by these examples, we then propose a new paradigm for model-selection in games wherein an agent seeks to choose amongst different model classes to use as their action set in a game.
Chasing Convex Bodies and Functions with Black-Box Advice
Jun 23, 2022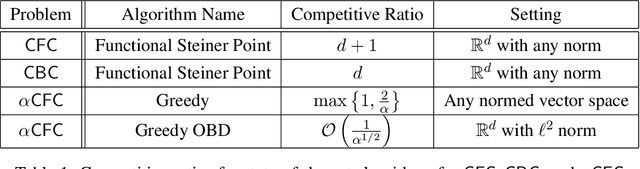

We consider the problem of convex function chasing with black-box advice, where an online decision-maker aims to minimize the total cost of making and switching between decisions in a normed vector space, aided by black-box advice such as the decisions of a machine-learned algorithm. The decision-maker seeks cost comparable to the advice when it performs well, known as $\textit{consistency}$, while also ensuring worst-case $\textit{robustness}$ even when the advice is adversarial. We first consider the common paradigm of algorithms that switch between the decisions of the advice and a competitive algorithm, showing that no algorithm in this class can improve upon 3-consistency while staying robust. We then propose two novel algorithms that bypass this limitation by exploiting the problem's convexity. The first, INTERP, achieves $(\sqrt{2}+\epsilon)$-consistency and $\mathcal{O}(\frac{C}{\epsilon^2})$-robustness for any $\epsilon > 0$, where $C$ is the competitive ratio of an algorithm for convex function chasing or a subclass thereof. The second, BDINTERP, achieves $(1+\epsilon)$-consistency and $\mathcal{O}(\frac{CD}{\epsilon})$-robustness when the problem has bounded diameter $D$. Further, we show that BDINTERP achieves near-optimal consistency-robustness trade-off for the special case where cost functions are $\alpha$-polyhedral.
Improving Adversarial Robustness Using Proxy Distributions
Apr 19, 2021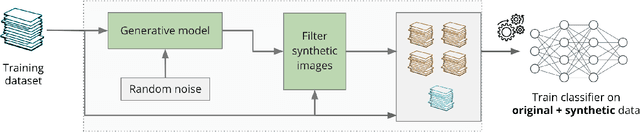

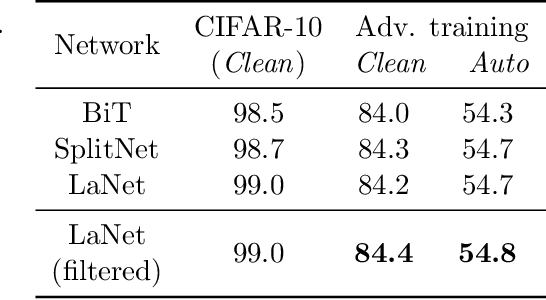
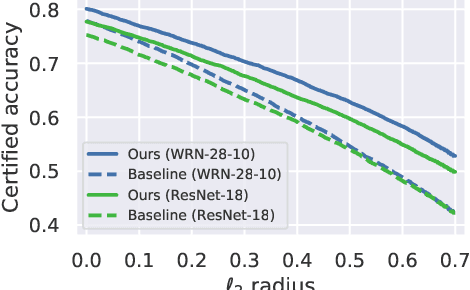
We focus on the use of proxy distributions, i.e., approximations of the underlying distribution of the training dataset, in both understanding and improving the adversarial robustness in image classification. While additional training data helps in adversarial training, curating a very large number of real-world images is challenging. In contrast, proxy distributions enable us to sample a potentially unlimited number of images and improve adversarial robustness using these samples. We first ask the question: when does adversarial robustness benefit from incorporating additional samples from the proxy distribution in the training stage? We prove that the difference between the robustness of a classifier on the proxy and original training dataset distribution is upper bounded by the conditional Wasserstein distance between them. Our result confirms the intuition that samples from a proxy distribution that closely approximates training dataset distribution should be able to boost adversarial robustness. Motivated by this finding, we leverage samples from state-of-the-art generative models, which can closely approximate training data distribution, to improve robustness. In particular, we improve robust accuracy by up to 6.1% and 5.7% in $l_{\infty}$ and $l_2$ threat model, and certified robust accuracy by 6.7% over baselines not using proxy distributions on the CIFAR-10 dataset. Since we can sample an unlimited number of images from a proxy distribution, it also allows us to investigate the effect of an increasing number of training samples on adversarial robustness. Here we provide the first large scale empirical investigation of accuracy vs robustness trade-off and sample complexity of adversarial training by training deep neural networks on 2K to 10M images.