 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Adversarial Robustness Using Proxy Distributions
Paper and Code

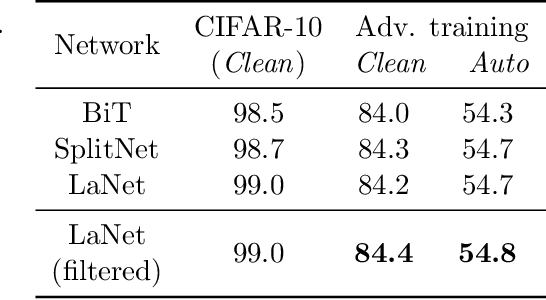
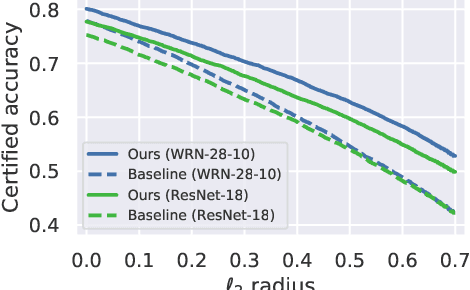
We focus on the use of proxy distributions, i.e., approximations of the underlying distribution of the training dataset, in both understanding and improving the adversarial robustness in image classification. While additional training data helps in adversarial training, curating a very large number of real-world images is challenging. In contrast, proxy distributions enable us to sample a potentially unlimited number of images and improve adversarial robustness using these samples. We first ask the question: when does adversarial robustness benefit from incorporating additional samples from the proxy distribution in the training stage? We prove that the difference between the robustness of a classifier on the proxy and original training dataset distribution is upper bounded by the conditional Wasserstein distance between them. Our result confirms the intuition that samples from a proxy distribution that closely approximates training dataset distribution should be able to boost adversarial robustness. Motivated by this finding, we leverage samples from state-of-the-art generative models, which can closely approximate training data distribution, to improve robustness. In particular, we improve robust accuracy by up to 6.1% and 5.7% in $l_{\infty}$ and $l_2$ threat model, and certified robust accuracy by 6.7% over baselines not using proxy distributions on the CIFAR-10 dataset. Since we can sample an unlimited number of images from a proxy distribution, it also allows us to investigate the effect of an increasing number of training samples on adversarial robustness. Here we provide the first large scale empirical investigation of accuracy vs robustness trade-off and sample complexity of adversarial training by training deep neural networks on 2K to 10M images.