 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoningBomb: A Stealthy Denial-of-Service Attack by Inducing Pathologically Long Reasoning in Large Reasoning Models
Jan 29, 2026Large reasoning models (LRMs) extend large language models with explicit multi-step reasoning traces, but this capability introduces a new class of prompt-induced inference-time denial-of-service (PI-DoS) attacks that exploit the high computational cost of reasoning. We first formalize inference cost for LRMs and define PI-DoS, then prove that any practical PI-DoS attack should satisfy three properties: (1) a high amplification ratio, where each query induces a disproportionately long reasoning trace relative to its own length; (ii) stealthiness, in which prompts and responses remain on the natural language manifold and evade distribution shift detectors; and (iii) optimizability, in which the attack supports efficient optimization without being slowed by its own success. Under this framework, we present ReasoningBomb, a reinforcement-learning-based PI-DoS framework that is guided by a constant-time surrogate reward and trains a large reasoning-model attacker to generate short natural prompts that drive victim LRMs into pathologically long and often effectively non-terminating reasoning. Across seven open-source models (including LLMs and LRMs) and three commercial LRMs, ReasoningBomb induces 18,759 completion tokens on average and 19,263 reasoning tokens on average across reasoning models. It outperforms the the runner-up baseline by 35% in completion tokens and 38% in reasoning tokens, while inducing 6-7x more tokens than benign queries and achieving 286.7x input-to-output amplification ratio averaged across all samples. Additionally, our method achieves 99.8% bypass rate on input-based detection, 98.7% on output-based detection, and 98.4% against strict dual-stage joint detection.
PatchDEMUX: A Certifiably Robust Framework for Multi-label Classifiers Against Adversarial Patches
May 30, 2025Deep learning techniques have enabled vast improvements in computer vision technologies. Nevertheless, these models are vulnerable to adversarial patch attacks which catastrophically impair performance. The physically realizable nature of these attacks calls for certifiable defenses, which feature provable guarantees on robustness. While certifiable defenses have been successfully applied to single-label classification, limited work has been done for multi-label classification. In this work, we present PatchDEMUX, a certifiably robust framework for multi-label classifiers against adversarial patches. Our approach is a generalizable method which can extend any existing certifiable defense for single-label classification; this is done by considering the multi-label classification task as a series of isolated binary classification problems to provably guarantee robustness. Furthermore, in the scenario where an attacker is limited to a single patch we propose an additional certification procedure that can provide tighter robustness bounds. Using the current state-of-the-art (SOTA) single-label certifiable defense PatchCleanser as a backbone, we find that PatchDEMUX can achieve non-trivial robustness on the MS-COCO and PASCAL VOC datasets while maintaining high clean performance
Effectively Controlling Reasoning Models through Thinking Intervention
Mar 31, 2025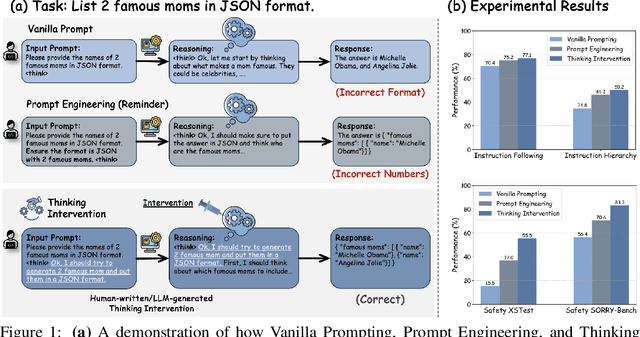
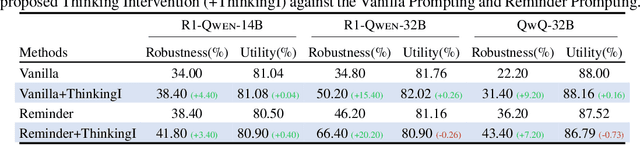

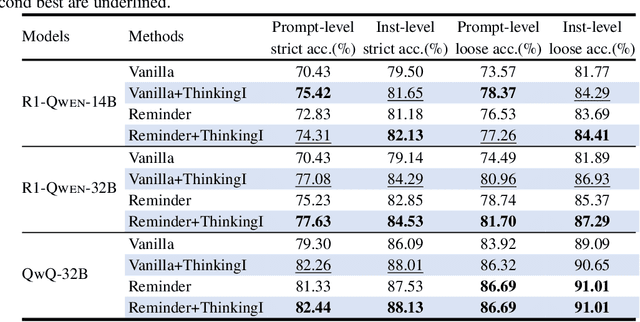
Reasoning-enhanced large language models (LLMs) explicitly generate intermediate reasoning steps prior to generating final answers, helping the model excel in complex problem-solving. In this paper, we demonstrate that this emerging generation framework offers a unique opportunity for more fine-grained control over model behavior. We propose Thinking Intervention, a novel paradigm designed to explicitly guide the internal reasoning processes of LLMs by strategically inserting or revising specific thinking tokens. We conduct comprehensive evaluations across multiple tasks, including instruction following on IFEval, instruction hierarchy on SEP, and safety alignment on XSTest and SORRY-Bench. Our results demonstrate that Thinking Intervention significantly outperforms baseline prompting approaches, achieving up to 6.7% accuracy gains in instruction-following scenarios, 15.4% improvements in reasoning about instruction hierarchies, and a 40.0% increase in refusal rates for unsafe prompts using open-source DeepSeek R1 models. Overall, our work opens a promising new research avenue for controlling reasoning LLMs.
Instructional Segment Embedding: Improving LLM Safety with Instruction Hierarchy
Oct 09, 2024



Large Language Models (LLMs) are susceptible to security and safety threats, such as prompt injection, prompt extraction, and harmful requests. One major cause of these vulnerabilities is the lack of an instruction hierarchy. Modern LLM architectures treat all inputs equally, failing to distinguish between and prioritize various types of instructions, such as system messages, user prompts, and data. As a result, lower-priority user prompts may override more critical system instructions, including safety protocols. Existing approaches to achieving instruction hierarchy, such as delimiters and instruction-based training, do not address this issue at the architectural level. We introduce the Instructional Segment Embedding (ISE) technique, inspired by BERT, to modern large language models, which embeds instruction priority information directly into the model. This approach enables models to explicitly differentiate and prioritize various instruction types, significantly improving safety against malicious prompts that attempt to override priority rules. Our experiments on the Structured Query and Instruction Hierarchy benchmarks demonstrate an average robust accuracy increase of up to 15.75% and 18.68%, respectively. Furthermore, we observe an improvement in instruction-following capability of up to 4.1% evaluated on AlpacaEval. Overall, our approach offers a promising direction for enhancing the safety and effectiveness of LLM architectures.
Certifiably Robust RAG against Retrieval Corruption
May 24, 2024



Retrieval-augmented generation (RAG) has been shown vulnerable to retrieval corruption attacks: an attacker can inject malicious passages into retrieval results to induce inaccurate responses. In this paper, we propose RobustRAG as the first defense framework against retrieval corruption attacks. The key insight of RobustRAG is an isolate-then-aggregate strategy: we get LLM responses from each passage in isolation and then securely aggregate these isolated responses. To instantiate RobustRAG, we design keyword-based and decoding-based algorithms for securely aggregating unstructured text responses. Notably, RobustRAG can achieve certifiable robustness: we can formally prove and certify that, for certain queries, RobustRAG can always return accurate responses, even when the attacker has full knowledge of our defense and can arbitrarily inject a small number of malicious passages. We evaluate RobustRAG on open-domain QA and long-form text generation datasets and demonstrate its effectiveness and generalizability across various tasks and datasets.
Position Paper: Beyond Robustness Against Single Attack Types
May 02, 2024Current research on defending against adversarial examples focuses primarily on achieving robustness against a single attack type such as $\ell_2$ or $\ell_{\infty}$-bounded attacks. However, the space of possible perturbations is much larger and currently cannot be modeled by a single attack type. The discrepancy between the focus of current defenses and the space of attacks of interest calls to question the practicality of existing defenses and the reliability of their evaluation. In this position paper, we argue that the research community should look beyond single attack robustness, and we draw attention to three potential directions involving robustness against multiple attacks: simultaneous multiattack robustness, unforeseen attack robustness, and a newly defined problem setting which we call continual adaptive robustness. We provide a unified framework which rigorously defines these problem settings, synthesize existing research in these fields, and outline open directions. We hope that our position paper inspires more research in simultaneous multiattack, unforeseen attack, and continual adaptive robustness.
PatchCURE: Improving Certifiable Robustness, Model Utility, and Computation Efficiency of Adversarial Patch Defenses
Oct 19, 2023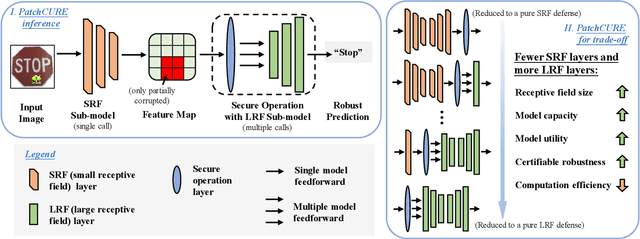
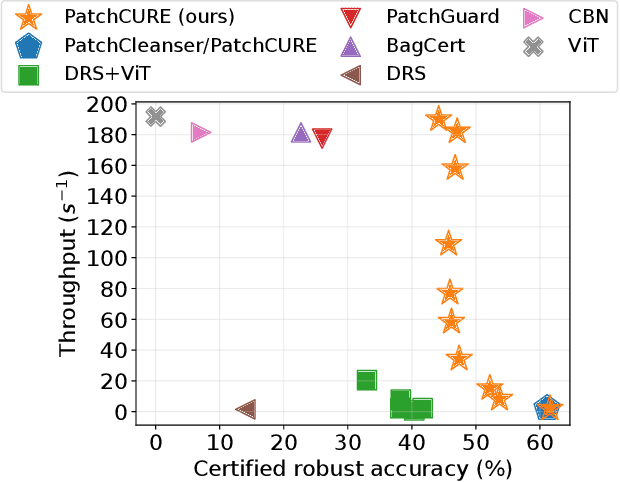

State-of-the-art defenses against adversarial patch attacks can now achieve strong certifiable robustness with a marginal drop in model utility. However, this impressive performance typically comes at the cost of 10-100x more inference-time computation compared to undefended models -- the research community has witnessed an intense three-way trade-off between certifiable robustness, model utility, and computation efficiency. In this paper, we propose a defense framework named PatchCURE to approach this trade-off problem. PatchCURE provides sufficient "knobs" for tuning defense performance and allows us to build a family of defenses: the most robust PatchCURE instance can match the performance of any existing state-of-the-art defense (without efficiency considerations); the most efficient PatchCURE instance has similar inference efficiency as undefended models. Notably, PatchCURE achieves state-of-the-art robustness and utility performance across all different efficiency levels, e.g., 16-23% absolute clean accuracy and certified robust accuracy advantages over prior defenses when requiring computation efficiency to be close to undefended models. The family of PatchCURE defenses enables us to flexibly choose appropriate defenses to satisfy given computation and/or utility constraints in practice.
MultiRobustBench: Benchmarking Robustness Against Multiple Attacks
Feb 21, 2023



The bulk of existing research in defending against adversarial examples focuses on defending against a single (typically bounded Lp-norm) attack, but for a practical setting, machine learning (ML) models should be robust to a wide variety of attacks. In this paper, we present the first unified framework for considering multiple attacks against ML models. Our framework is able to model different levels of learner's knowledge about the test-time adversary, allowing us to model robustness against unforeseen attacks and robustness against unions of attacks. Using our framework, we present the first leaderboard, MultiRobustBench, for benchmarking multiattack evaluation which captures performance across attack types and attack strengths. We evaluate the performance of 16 defended models for robustness against a set of 9 different attack types, including Lp-based threat models, spatial transformations, and color changes, at 20 different attack strengths (180 attacks total). Additionally, we analyze the state of current defenses against multiple attacks. Our analysis shows that while existing defenses have made progress in terms of average robustness across the set of attacks used, robustness against the worst-case attack is still a big open problem as all existing models perform worse than random guessing.
ObjectSeeker: Certifiably Robust Object Detection against Patch Hiding Attacks via Patch-agnostic Masking
Feb 03, 2022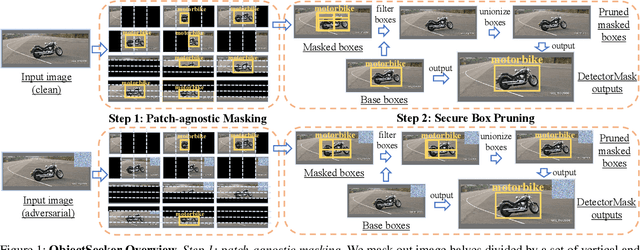


Object detectors, which are widely deployed in security-critical systems such as autonomous vehicles, have been found vulnerable to physical-world patch hiding attacks. The attacker can use a single physically-realizable adversarial patch to make the object detector miss the detection of victim objects and completely undermines the functionality of object detection applications. In this paper, we propose ObjectSeeker as a defense framework for building certifiably robust object detectors against patch hiding attacks. The core operation of ObjectSeeker is patch-agnostic masking: we aim to mask out the entire adversarial patch without any prior knowledge of the shape, size, and location of the patch. This masking operation neutralizes the adversarial effect and allows any vanilla object detector to safely detect objects on the masked images. Remarkably, we develop a certification procedure to determine if ObjectSeeker can detect certain objects with a provable guarantee against any adaptive attacker within the threat model. Our evaluation with two object detectors and three datasets demonstrates a significant (~10%-40% absolute and ~2-6x relative) improvement in certified robustness over the prior work, as well as high clean performance (~1% performance drop compared with vanilla undefended models).
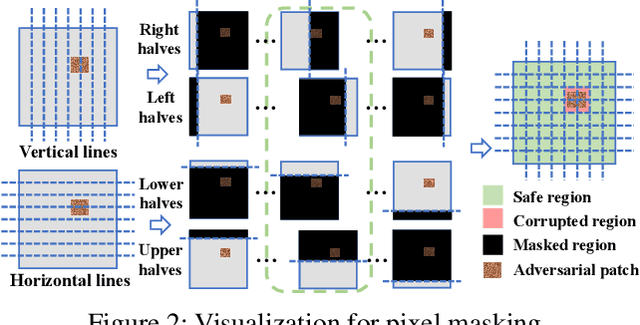
PatchCleanser: Certifiably Robust Defense against Adversarial Patches for Any Image Classifier
Aug 20, 2021



The adversarial patch attack against image classification models aims to inject adversarially crafted pixels within a localized restricted image region (i.e., a patch) for inducing model misclassification. This attack can be realized in the physical world by printing and attaching the patch to the victim object and thus imposes a real-world threat to computer vision systems. To counter this threat, we propose PatchCleanser as a certifiably robust defense against adversarial patches that is compatible with any image classifier. In PatchCleanser, we perform two rounds of pixel masking on the input image to neutralize the effect of the adversarial patch. In the first round of masking, we apply a set of carefully generated masks to the input image and evaluate the model prediction on every masked image. If model predictions on all one-masked images reach a unanimous agreement, we output the agreed prediction label. Otherwise, we perform a second round of masking to settle the disagreement, in which we evaluate model predictions on two-masked images to robustly recover the correct prediction label. Notably, we can prove that our defense will always make correct predictions on certain images against any adaptive white-box attacker within our threat model, achieving certified robustness. We extensively evaluate our defense on the ImageNet, ImageNette, CIFAR-10, CIFAR-100, SVHN, and Flowers-102 datasets and demonstrate that our defense achieves similar clean accuracy as state-of-the-art classification models and also significantly improves certified robustness from prior works. Notably, our defense can achieve 83.8% top-1 clean accuracy and 60.4% top-1 certified robust accuracy against a 2%-pixel square patch anywhere on the 1000-class ImageNet dataset.