 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Draft: Thinking Faster by Writing Less
Feb 25, 2025



Large Language Models (LLMs) have demonstrated remarkable performance in solving complex reasoning tasks through mechanisms like Chain-of-Thought (CoT) prompting, which emphasizes verbose, step-by-step reasoning. However, humans typically employ a more efficient strategy: drafting concise intermediate thoughts that capture only essential information. In this work, we propose Chain of Draft (CoD), a novel paradigm inspired by human cognitive processes, where LLMs generate minimalistic yet informative intermediate reasoning outputs while solving tasks. By reducing verbosity and focusing on critical insights, CoD matches or surpasses CoT in accuracy while using as little as only 7.6% of the tokens, significantly reducing cost and latency across various reasoning tasks.
Instructional Segment Embedding: Improving LLM Safety with Instruction Hierarchy
Oct 09, 2024



Large Language Models (LLMs) are susceptible to security and safety threats, such as prompt injection, prompt extraction, and harmful requests. One major cause of these vulnerabilities is the lack of an instruction hierarchy. Modern LLM architectures treat all inputs equally, failing to distinguish between and prioritize various types of instructions, such as system messages, user prompts, and data. As a result, lower-priority user prompts may override more critical system instructions, including safety protocols. Existing approaches to achieving instruction hierarchy, such as delimiters and instruction-based training, do not address this issue at the architectural level. We introduce the Instructional Segment Embedding (ISE) technique, inspired by BERT, to modern large language models, which embeds instruction priority information directly into the model. This approach enables models to explicitly differentiate and prioritize various instruction types, significantly improving safety against malicious prompts that attempt to override priority rules. Our experiments on the Structured Query and Instruction Hierarchy benchmarks demonstrate an average robust accuracy increase of up to 15.75% and 18.68%, respectively. Furthermore, we observe an improvement in instruction-following capability of up to 4.1% evaluated on AlpacaEval. Overall, our approach offers a promising direction for enhancing the safety and effectiveness of LLM architectures.
WPO: Enhancing RLHF with Weighted Preference Optimization
Jun 17, 2024Reinforcement learning from human feedback (RLHF) is a promising solution to align large language models (LLMs) more closely with human values. Off-policy preference optimization, where the preference data is obtained from other models, is widely adopted due to its cost efficiency and scalability. However, off-policy preference optimization often suffers from a distributional gap between the policy used for data collection and the target policy, leading to suboptimal optimization. In this paper, we propose a novel strategy to mitigate this problem by simulating on-policy learning with off-policy preference data. Our Weighted Preference Optimization (WPO) method adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. This method not only addresses the distributional gap problem but also enhances the optimization process without incurring additional costs. We validate our method on instruction following benchmarks including Alpaca Eval 2 and MT-bench. WPO not only outperforms Direct Preference Optimization (DPO) by up to 5.6% on Alpaca Eval 2 but also establishes a remarkable length-controlled winning rate against GPT-4-turbo of 48.6% based on Llama-3-8B-Instruct, making it the strongest 8B model on the leaderboard. We will release the code and models at https://github.com/wzhouad/WPO.
Complementing GPT-3 with Few-Shot Sequence-to-Sequence Semantic Parsing over Wikidata
May 23, 2023As the largest knowledge base, Wikidata is a massive source of knowledge, complementing large language models with well-structured data. In this paper, we present WikiWebQuestions, a high-quality knowledge base question answering benchmark for Wikidata. This new benchmark uses real-world human data with SPARQL annotation to facilitate a more accurate comparison with large language models utilizing the up-to-date answers from Wikidata. Additionally, a baseline for this benchmark is established with an effective training data synthesis methodology and WikiSP, a Seq2Seq semantic parser, that handles large noisy knowledge graphs. Experimental results illustrate the effectiveness of this methodology, achieving 69% and 59% answer accuracy in the dev set and test set, respectively. We showed that we can pair semantic parsers with GPT-3 to provide a combination of verifiable results and qualified guesses that can provide useful answers to 97% of the questions in the dev set of our benchmark.
ThingTalk: An Extensible, Executable Representation Language for Task-Oriented Dialogues
Mar 23, 2022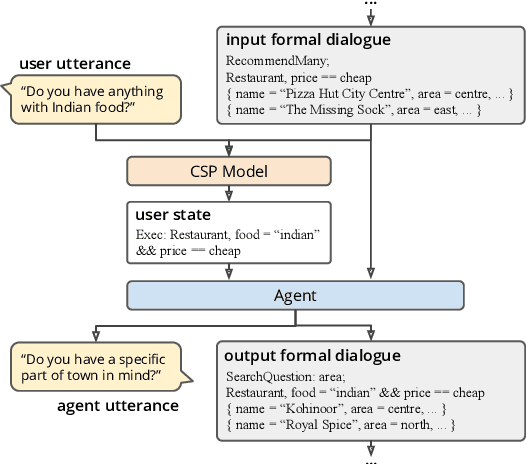
Task-oriented conversational agents rely on semantic parsers to translate natural language to formal representations. In this paper, we propose the design and rationale of the ThingTalk formal representation, and how the design improves the development of transactional task-oriented agents. ThingTalk is built on four core principles: (1) representing user requests directly as executable statements, covering all the functionality of the agent, (2) representing dialogues formally and succinctly to support accurate contextual semantic parsing, (3) standardizing types and interfaces to maximize reuse between agents, and (4) allowing multiple, independently-developed agents to be composed in a single virtual assistant. ThingTalk is developed as part of the Genie Framework that allows developers to quickly build transactional agents given a database and APIs. We compare ThingTalk to existing representations: SMCalFlow, SGD, TreeDST. Compared to the others, the ThingTalk design is both more general and more cost-effective. Evaluated on the MultiWOZ benchmark, using ThingTalk and associated tools yields a new state of the art accuracy of 79% turn-by-turn.
Localizing Open-Ontology QA Semantic Parsers in a Day Using Machine Translation
Oct 10, 2020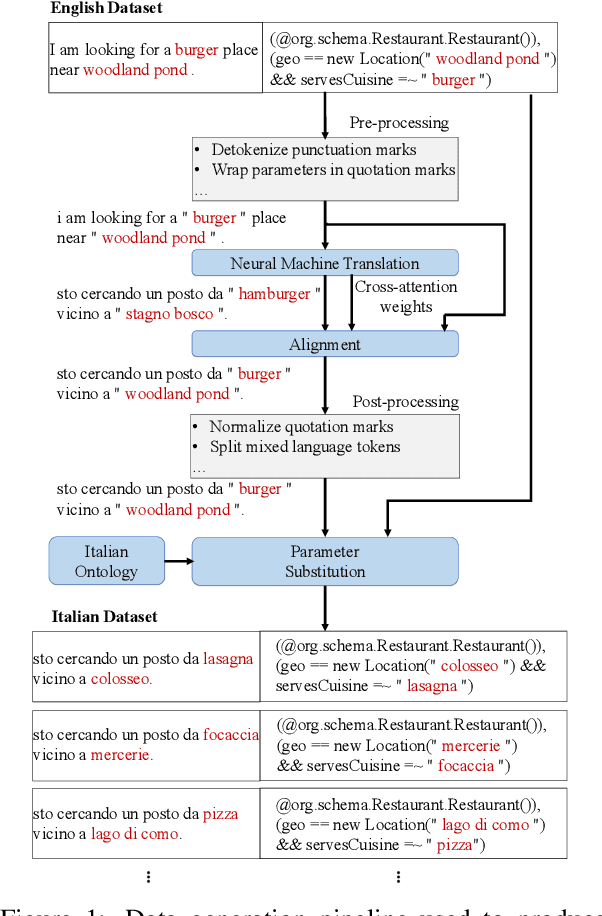

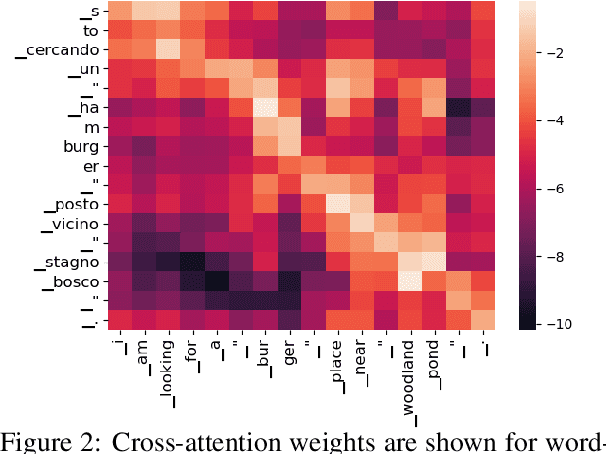
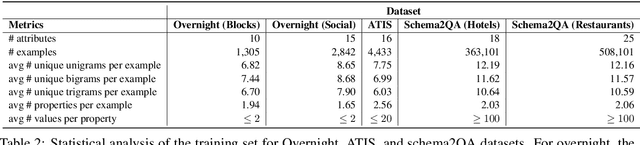
We propose Semantic Parser Localizer (SPL), a toolkit that leverages Neural Machine Translation (NMT) systems to localize a semantic parser for a new language. Our methodology is to (1) generate training data automatically in the target language by augmenting machine-translated datasets with local entities scraped from public websites, (2) add a few-shot boost of human-translated sentences and train a novel XLMR-LSTM semantic parser, and (3) test the model on natural utterances curated using human translators. We assess the effectiveness of our approach by extending the current capabilities of Schema2QA, a system for English Question Answering (QA) on the open web, to 10 new languages for the restaurants and hotels domains. Our models achieve an overall test accuracy ranging between 61% and 69% for the hotels domain and between 64% and 78% for restaurants domain, which compares favorably to 69% and 80% obtained for English parser trained on gold English data and a few examples from validation set. We show our approach outperforms the previous state-of-the-art methodology by more than 30% for hotels and 40% for restaurants with localized ontologies for the subset of languages tested. Our methodology enables any software developer to add a new language capability to a QA system for a new domain, leveraging machine translation, in less than 24 hours.
AutoQA: From Databases To QA Semantic Parsers With Only Synthetic Training Data
Oct 09, 2020



We propose AutoQA, a methodology and toolkit to generate semantic parsers that answer questions on databases, with no manual effort. Given a database schema and its data, AutoQA automatically generates a large set of high-quality questions for training that covers different database operations. It uses automatic paraphrasing combined with template-based parsing to find alternative expressions of an attribute in different parts of speech. It also uses a novel filtered auto-paraphraser to generate correct paraphrases of entire sentences. We apply AutoQA to the Schema2QA dataset and obtain an average logical form accuracy of 62.9% when tested on natural questions, which is only 6.4% lower than a model trained with expert natural language annotations and paraphrase data collected from crowdworkers. To demonstrate the generality of AutoQA, we also apply it to the Overnight dataset. AutoQA achieves 69.8% answer accuracy, 16.4% higher than the state-of-the-art zero-shot models and only 5.2% lower than the same model trained with human data.
Schema2QA: Answering Complex Queries on the Structured Web with a Neural Model
Jan 27, 2020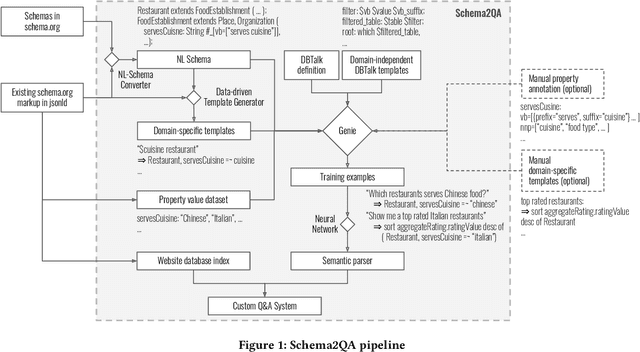


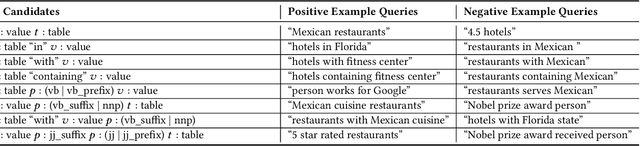
Virtual assistants have proprietary third-party skill platforms; they train and own the voice interface to websites based on their submitted skill information. This paper proposes Schema2QA, an open-source toolkit that leverages the Schema.org markup found in many websites to automatically build skills. Schema2QA has several advantages: (1) Schema2QA is more accurate than commercial assistants in answering compositional queries involving multiple properties; (2) it has a low-cost training data acquisition methodology that requires only writing a small number of annotations per domain and paraphrasing a small number of sentences. Schema2QA uses a novel neural model that combines the BERT pretrained model with an LSTM; the model can generalize a training set containing only synthesized and paraphrase data to understand real-world crowdsourced questions. We apply Schema2QA to two different domains, showing that the skills we built can answer useful queries with little manual effort. Our skills achieve an overall accuracy between 73% and 81%. With transfer learning, we show that a new domain can achieve a 59% accuracy without manual effort. The open-source Schema2QA lets each website create and own its linguistic interface.
Genie: A Generator of Natural Language Semantic Parsers for Virtual Assistant Commands
Apr 18, 2019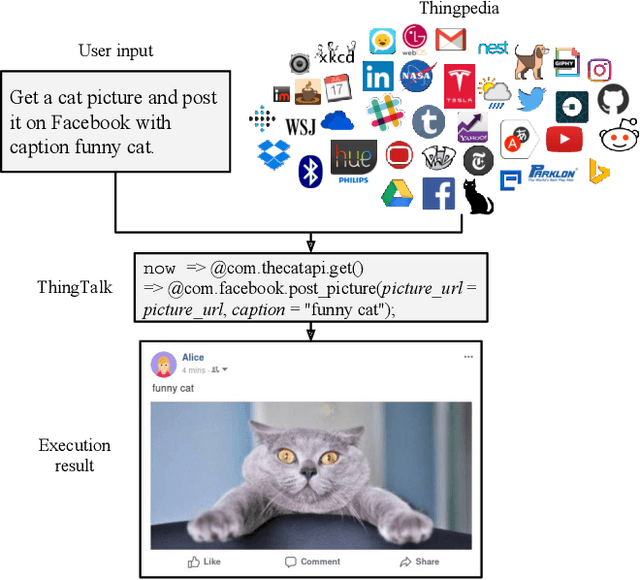
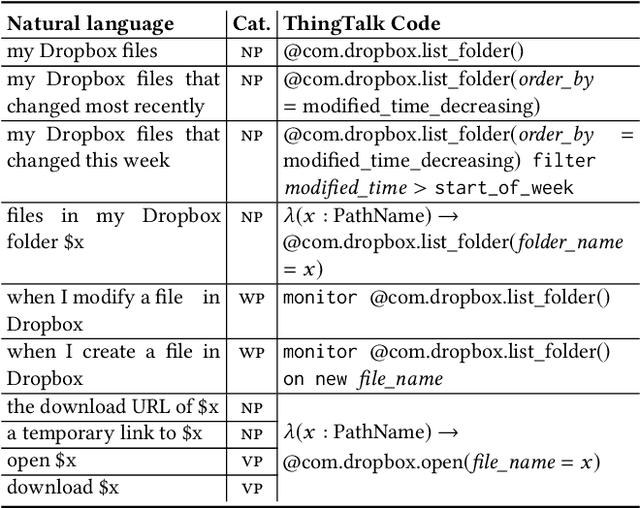
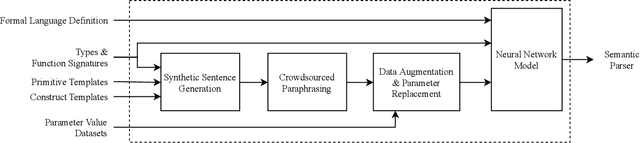

To understand diverse natural language commands, virtual assistants today are trained with numerous labor-intensive, manually annotated sentences. This paper presents a methodology and the Genie toolkit that can handle new compound commands with significantly less manual effort. We advocate formalizing the capability of virtual assistants with a Virtual Assistant Programming Language (VAPL) and using a neural semantic parser to translate natural language into VAPL code. Genie needs only a small realistic set of input sentences for validating the neural model. Developers write templates to synthesize data; Genie uses crowdsourced paraphrases and data augmentation, along with the synthesized data, to train a semantic parser. We also propose design principles that make VAPL languages amenable to natural language translation. We apply these principles to revise ThingTalk, the language used by the Almond virtual assistant. We use Genie to build the first semantic parser that can support compound virtual assistants commands with unquoted free-form parameters. Genie achieves a 62% accuracy on realistic user inputs. We demonstrate Genie's generality by showing a 19% and 31% improvement over the previous state of the art on a music skill, aggregate functions, and access control.