 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema2QA: Answering Complex Queries on the Structured Web with a Neural Model
Paper and Code
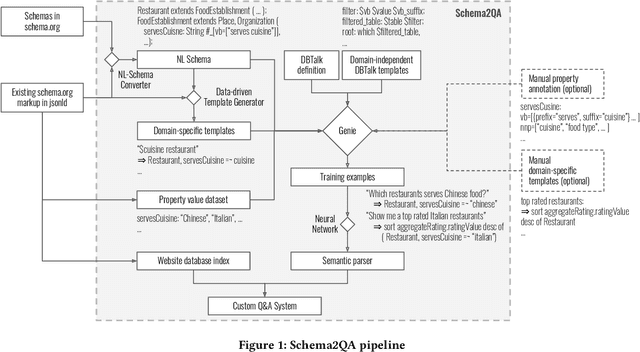


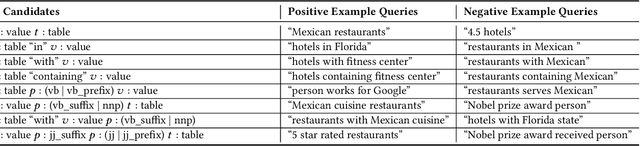
Virtual assistants have proprietary third-party skill platforms; they train and own the voice interface to websites based on their submitted skill information. This paper proposes Schema2QA, an open-source toolkit that leverages the Schema.org markup found in many websites to automatically build skills. Schema2QA has several advantages: (1) Schema2QA is more accurate than commercial assistants in answering compositional queries involving multiple properties; (2) it has a low-cost training data acquisition methodology that requires only writing a small number of annotations per domain and paraphrasing a small number of sentences. Schema2QA uses a novel neural model that combines the BERT pretrained model with an LSTM; the model can generalize a training set containing only synthesized and paraphrase data to understand real-world crowdsourced questions. We apply Schema2QA to two different domains, showing that the skills we built can answer useful queries with little manual effort. Our skills achieve an overall accuracy between 73% and 81%. With transfer learning, we show that a new domain can achieve a 59% accuracy without manual effort. The open-source Schema2QA lets each website create and own its linguistic interface.