 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebLists: Extracting Structured Information From Complex Interactive Websites Using Executable LLM Agents
Apr 17, 2025Most recent web agent research has focused on navigation and transaction tasks, with little emphasis on extracting structured data at scale. We present WebLists, a benchmark of 200 data-extraction tasks across four common business and enterprise use-cases. Each task requires an agent to navigate to a webpage, configure it appropriately, and extract complete datasets with well-defined schemas. We show that both LLMs with search capabilities and SOTA web agents struggle with these tasks, with a recall of 3% and 31%, respectively, despite higher performance on question-answering tasks. To address this challenge, we propose BardeenAgent, a novel framework that enables web agents to convert their execution into repeatable programs, and replay them at scale across pages with similar structure. BardeenAgent is also the first LLM agent to take advantage of the regular structure of HTML. In particular BardeenAgent constructs a generalizable CSS selector to capture all relevant items on the page, then fits the operations to extract the data. On the WebLists benchmark, BardeenAgent achieves 66% recall overall, more than doubling the performance of SOTA web agents, and reducing cost per output row by 3x.
WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents
Apr 08, 2024In the realm of web agent research, achieving both generalization and accuracy remains a challenging problem. Due to high variance in website structure, existing approaches often fail. Moreover, existing fine-tuning and in-context learning techniques fail to generalize across multiple websites. We introduce Wilbur, an approach that uses a differentiable ranking model and a novel instruction synthesis technique to optimally populate a black-box large language model's prompt with task demonstrations from previous runs. To maximize end-to-end success rates, we also propose an intelligent backtracking mechanism that learns and recovers from its mistakes. Finally, we show that our ranking model can be trained on data from a generative auto-curriculum which samples representative goals from an LLM, runs the agent, and automatically evaluates it, with no manual annotation. Wilbur achieves state-of-the-art results on the WebVoyager benchmark, beating text-only models by 8% overall, and up to 36% on certain websites. On the same benchmark, Wilbur is within 5% of a strong multi-modal model despite only receiving textual inputs, and further analysis reveals a substantial number of failures are due to engineering challenges of operating the web.
BYOC: Personalized Few-Shot Classification with Co-Authored Class Descriptions
Oct 09, 2023Text classification is a well-studied and versatile building block for many NLP applications. Yet, existing approaches require either large annotated corpora to train a model with or, when using large language models as a base, require carefully crafting the prompt as well as using a long context that can fit many examples. As a result, it is not possible for end-users to build classifiers for themselves. To address this issue, we propose a novel approach to few-shot text classification using an LLM. Rather than few-shot examples, the LLM is prompted with descriptions of the salient features of each class. These descriptions are coauthored by the user and the LLM interactively: while the user annotates each few-shot example, the LLM asks relevant questions that the user answers. Examples, questions, and answers are summarized to form the classification prompt. Our experiments show that our approach yields high accuracy classifiers, within 82% of the performance of models trained with significantly larger datasets while using only 1% of their training sets. Additionally, in a study with 30 participants, we show that end-users are able to build classifiers to suit their specific needs. The personalized classifiers show an average accuracy of 90%, which is 15% higher than the state-of-the-art approach.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022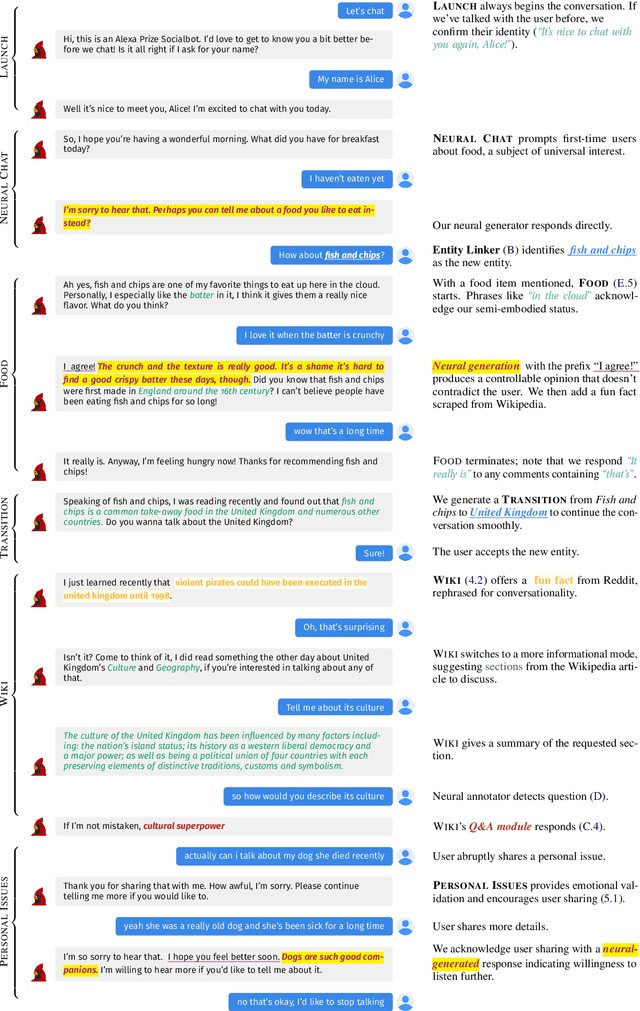


We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
ThingTalk: An Extensible, Executable Representation Language for Task-Oriented Dialogues
Mar 23, 2022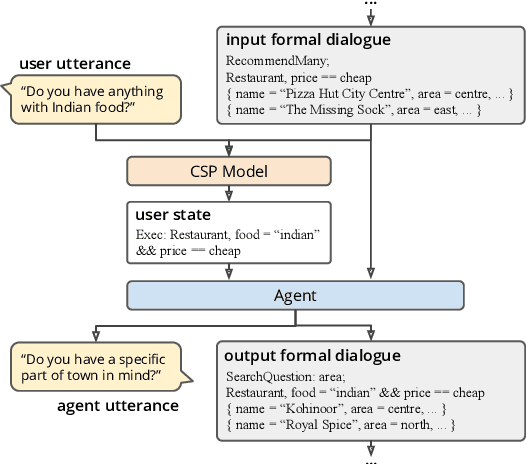
Task-oriented conversational agents rely on semantic parsers to translate natural language to formal representations. In this paper, we propose the design and rationale of the ThingTalk formal representation, and how the design improves the development of transactional task-oriented agents. ThingTalk is built on four core principles: (1) representing user requests directly as executable statements, covering all the functionality of the agent, (2) representing dialogues formally and succinctly to support accurate contextual semantic parsing, (3) standardizing types and interfaces to maximize reuse between agents, and (4) allowing multiple, independently-developed agents to be composed in a single virtual assistant. ThingTalk is developed as part of the Genie Framework that allows developers to quickly build transactional agents given a database and APIs. We compare ThingTalk to existing representations: SMCalFlow, SGD, TreeDST. Compared to the others, the ThingTalk design is both more general and more cost-effective. Evaluated on the MultiWOZ benchmark, using ThingTalk and associated tools yields a new state of the art accuracy of 79% turn-by-turn.
Contextual Semantic Parsing for Multilingual Task-Oriented Dialogues
Nov 04, 2021

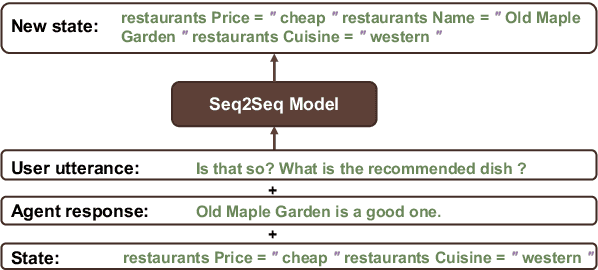

Robust state tracking for task-oriented dialogue systems currently remains restricted to a few popular languages. This paper shows that given a large-scale dialogue data set in one language, we can automatically produce an effective semantic parser for other languages using machine translation. We propose automatic translation of dialogue datasets with alignment to ensure faithful translation of slot values and eliminate costly human supervision used in previous benchmarks. We also propose a new contextual semantic parsing model, which encodes the formal slots and values, and only the last agent and user utterances. We show that the succinct representation reduces the compounding effect of translation errors, without harming the accuracy in practice. We evaluate our approach on several dialogue state tracking benchmarks. On RiSAWOZ, CrossWOZ, CrossWOZ-EN, and MultiWOZ-ZH datasets we improve the state of the art by 11%, 17%, 20%, and 0.3% in joint goal accuracy. We present a comprehensive error analysis for all three datasets showing erroneous annotations can obscure judgments on the quality of the model. Finally, we present RiSAWOZ English and German datasets, created using our translation methodology. On these datasets, accuracy is within 11% of the original showing that high-accuracy multilingual dialogue datasets are possible without relying on expensive human annotations.
Grounding Open-Domain Instructions to Automate Web Support Tasks
Apr 04, 2021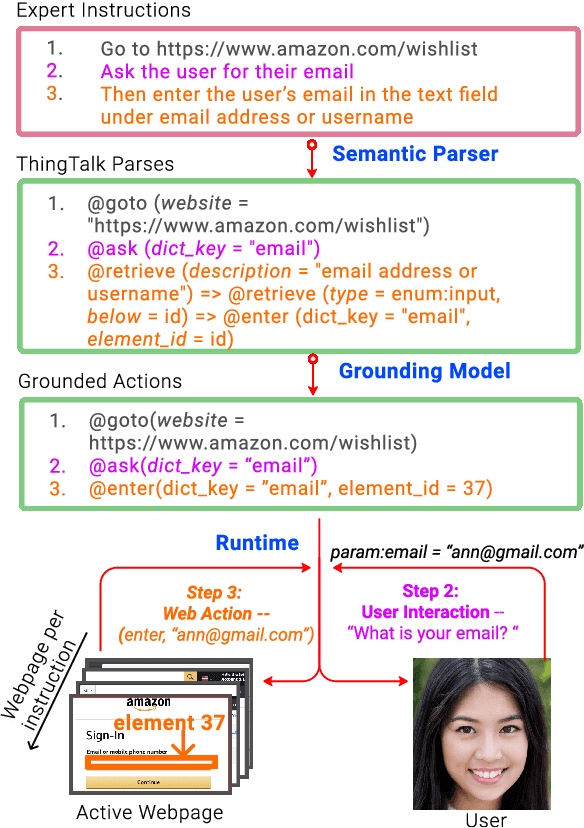
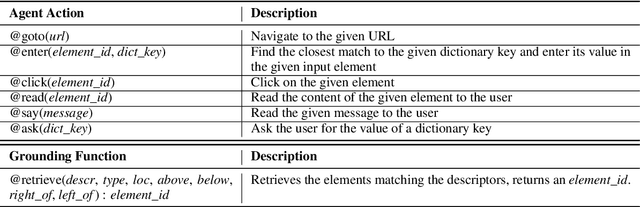
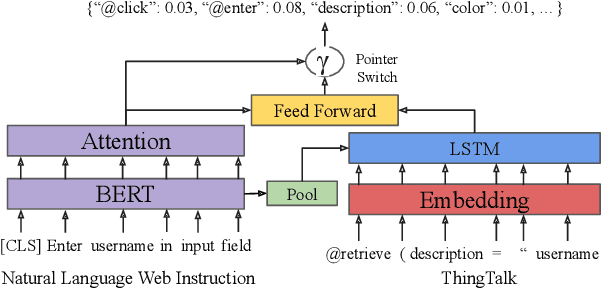

Grounding natural language instructions on the web to perform previously unseen tasks enables accessibility and automation. We introduce a task and dataset to train AI agents from open-domain, step-by-step instructions originally written for people. We build RUSS (Rapid Universal Support Service) to tackle this problem. RUSS consists of two models: First, a BERT-LSTM with pointers parses instructions to ThingTalk, a domain-specific language we design for grounding natural language on the web. Then, a grounding model retrieves the unique IDs of any webpage elements requested in ThingTalk. RUSS may interact with the user through a dialogue (e.g. ask for an address) or execute a web operation (e.g. click a button) inside the web runtime. To augment training, we synthesize natural language instructions mapped to ThingTalk. Our dataset consists of 80 different customer service problems from help websites, with a total of 741 step-by-step instructions and their corresponding actions. RUSS achieves 76.7% end-to-end accuracy predicting agent actions from single instructions. It outperforms state-of-the-art models that directly map instructions to actions without ThingTalk. Our user study shows that RUSS is preferred by actual users over web navigation.
Localizing Open-Ontology QA Semantic Parsers in a Day Using Machine Translation
Oct 10, 2020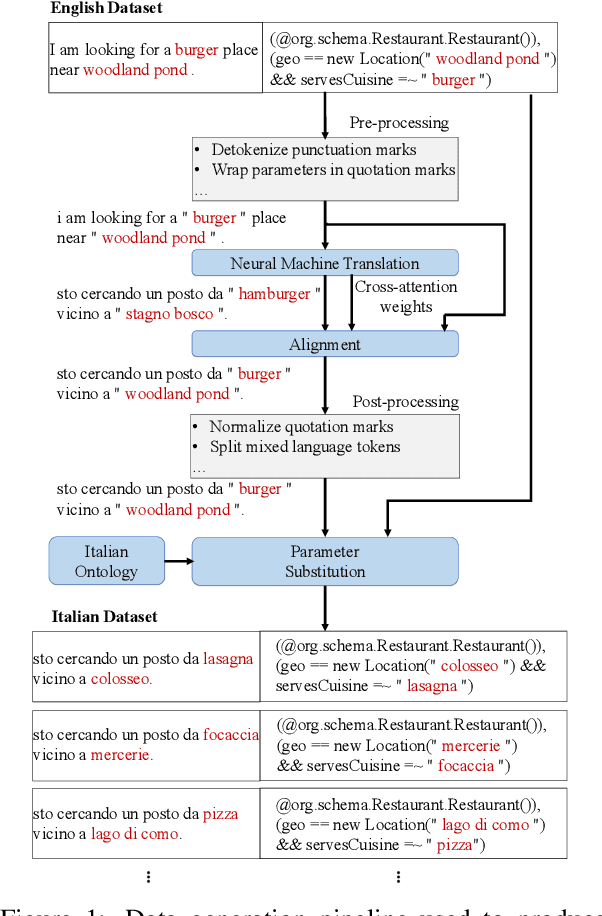

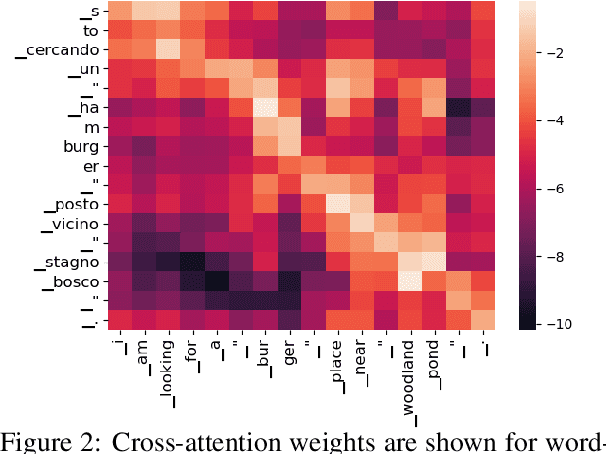
We propose Semantic Parser Localizer (SPL), a toolkit that leverages Neural Machine Translation (NMT) systems to localize a semantic parser for a new language. Our methodology is to (1) generate training data automatically in the target language by augmenting machine-translated datasets with local entities scraped from public websites, (2) add a few-shot boost of human-translated sentences and train a novel XLMR-LSTM semantic parser, and (3) test the model on natural utterances curated using human translators. We assess the effectiveness of our approach by extending the current capabilities of Schema2QA, a system for English Question Answering (QA) on the open web, to 10 new languages for the restaurants and hotels domains. Our models achieve an overall test accuracy ranging between 61% and 69% for the hotels domain and between 64% and 78% for restaurants domain, which compares favorably to 69% and 80% obtained for English parser trained on gold English data and a few examples from validation set. We show our approach outperforms the previous state-of-the-art methodology by more than 30% for hotels and 40% for restaurants with localized ontologies for the subset of languages tested. Our methodology enables any software developer to add a new language capability to a QA system for a new domain, leveraging machine translation, in less than 24 hours.
AutoQA: From Databases To QA Semantic Parsers With Only Synthetic Training Data
Oct 09, 2020



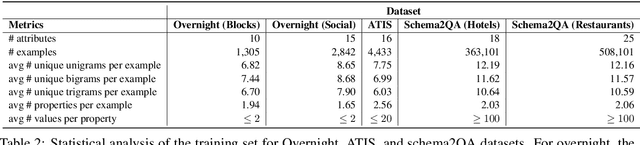
We propose AutoQA, a methodology and toolkit to generate semantic parsers that answer questions on databases, with no manual effort. Given a database schema and its data, AutoQA automatically generates a large set of high-quality questions for training that covers different database operations. It uses automatic paraphrasing combined with template-based parsing to find alternative expressions of an attribute in different parts of speech. It also uses a novel filtered auto-paraphraser to generate correct paraphrases of entire sentences. We apply AutoQA to the Schema2QA dataset and obtain an average logical form accuracy of 62.9% when tested on natural questions, which is only 6.4% lower than a model trained with expert natural language annotations and paraphrase data collected from crowdworkers. To demonstrate the generality of AutoQA, we also apply it to the Overnight dataset. AutoQA achieves 69.8% answer accuracy, 16.4% higher than the state-of-the-art zero-shot models and only 5.2% lower than the same model trained with human data.
State-Machine-Based Dialogue Agents with Few-Shot Contextual Semantic Parsers
Sep 16, 2020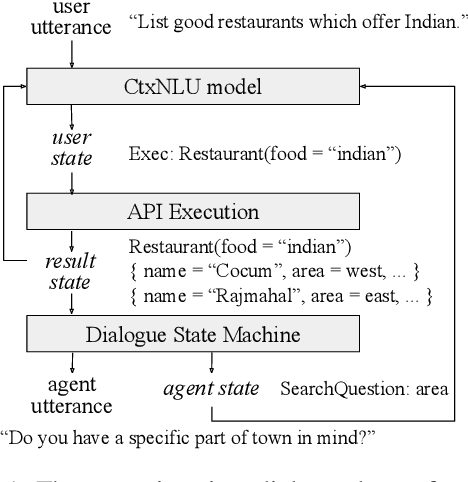
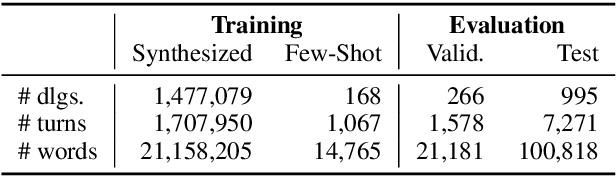

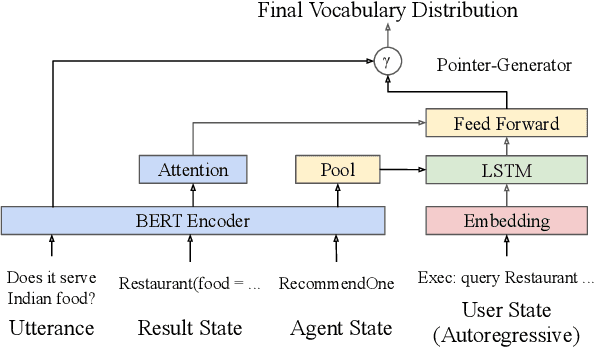
This paper presents a methodology and toolkit for creating a rule-based multi-domain conversational agent for transactions from (1) language annotations of the domains' database schemas and APIs and (2) a couple of hundreds of annotated human dialogues. There is no need for a large annotated training set, which is expensive to acquire. The toolkit uses a pre-defined abstract dialogue state machine to synthesize millions of dialogues based on the domains' information. The annotated and synthesized data are used to train a contextual semantic parser that interprets the user's latest utterance in the context of a formal representation of the conversation up to that point. Developers can refine the state machine to achieve higher accuracy. On the MultiWOZ benchmark, we achieve over 71% turn-by-turn slot accuracy on a cleaned, reannotated test set, without using any of the original training data. Our state machine can model 96% of the human agent turns. Our training strategy improves by 9% over a baseline that uses the same amount of hand-labeled data, showing the benefit of synthesizing data using the state machine.