 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Survival Analysis for Preclinical Cognitive Decline Prediction in Alzheimer's Disease Using Longitudinal Biomarkers
Mar 20, 2025Predicting the risk of clinical progression from cognitively normal (CN) status to mild cognitive impairment (MCI) or Alzheimer's disease (AD) is critical for early intervention in Alzheimer's disease (AD). Traditional survival models often fail to capture complex longitudinal biomarker patterns associated with disease progression. We propose an ensemble survival analysis framework integrating multiple survival models to improve early prediction of clinical progression in initially cognitively normal individuals. We analyzed longitudinal biomarker data from the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort, including 721 participants, limiting analysis to up to three visits (baseline, 6-month follow-up, 12-month follow-up). Of these, 142 (19.7%) experienced clinical progression to MCI or AD. Our approach combined penalized Cox regression (LASSO, Elastic Net) with advanced survival models (Random Survival Forest, DeepSurv, XGBoost). Model predictions were aggregated using ensemble averaging and Bayesian Model Averaging (BMA). Predictive performance was assessed using Harrell's concordance index (C-index) and time-dependent area under the curve (AUC). The ensemble model achieved a peak C-index of 0.907 and an integrated time-dependent AUC of 0.904, outperforming baseline-only models (C-index 0.608). One follow-up visit after baseline significantly improved prediction accuracy (48.1% C-index, 48.2% AUC gains), while adding a second follow-up provided only marginal gains (2.1% C-index, 2.7% AUC). Our ensemble survival framework effectively integrates diverse survival models and aggregation techniques to enhance early prediction of preclinical AD progression. These findings highlight the importance of leveraging longitudinal biomarker data, particularly one follow-up visit, for accurate risk stratification and personalized intervention strategies.
WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents
Apr 08, 2024In the realm of web agent research, achieving both generalization and accuracy remains a challenging problem. Due to high variance in website structure, existing approaches often fail. Moreover, existing fine-tuning and in-context learning techniques fail to generalize across multiple websites. We introduce Wilbur, an approach that uses a differentiable ranking model and a novel instruction synthesis technique to optimally populate a black-box large language model's prompt with task demonstrations from previous runs. To maximize end-to-end success rates, we also propose an intelligent backtracking mechanism that learns and recovers from its mistakes. Finally, we show that our ranking model can be trained on data from a generative auto-curriculum which samples representative goals from an LLM, runs the agent, and automatically evaluates it, with no manual annotation. Wilbur achieves state-of-the-art results on the WebVoyager benchmark, beating text-only models by 8% overall, and up to 36% on certain websites. On the same benchmark, Wilbur is within 5% of a strong multi-modal model despite only receiving textual inputs, and further analysis reveals a substantial number of failures are due to engineering challenges of operating the web.
ACCESS: Prompt Engineering for Automated Web Accessibility Violation Corrections
Jan 28, 2024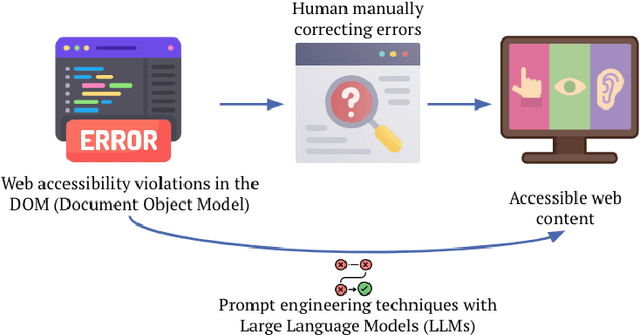


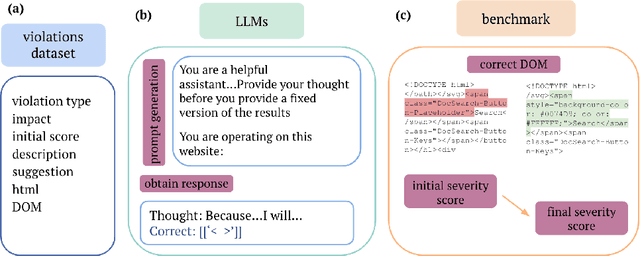
With the increasing need for inclusive and user-friendly technology, web accessibility is crucial to ensuring equal access to online content for individuals with disabilities, including visual, auditory, cognitive, or motor impairments. Despite the existence of accessibility guidelines and standards such as Web Content Accessibility Guidelines (WCAG) and the Web Accessibility Initiative (W3C), over 90\% of websites still fail to meet the necessary accessibility requirements. For web users with disabilities, there exists a need for a tool to automatically fix web page accessibility errors. While research has demonstrated methods to find and target accessibility errors, no research has focused on effectively correcting such violations. This paper presents a novel approach to correcting accessibility violations on the web by modifying the document object model (DOM) in real time with foundation models. Leveraging accessibility error information, large language models (LLMs), and prompt engineering techniques, we achieved greater than a 51\% reduction in accessibility violation errors after corrections on our novel benchmark: ACCESS. Our work demonstrates a valuable approach toward the direction of inclusive web content, and provides directions for future research to explore advanced methods to automate web accessibility.