 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenalized Fair Regression for Multiple Groups in Chronic Kidney Disease
Dec 19, 2025



Fair regression methods have the potential to mitigate societal bias concerns in health care, but there has been little work on penalized fair regression when multiple groups experience such bias. We propose a general regression framework that addresses this gap with unfairness penalties for multiple groups. Our approach is demonstrated for binary outcomes with true positive rate disparity penalties. It can be efficiently implemented through reduction to a cost-sensitive classification problem. We additionally introduce novel score functions for automatically selecting penalty weights. Our penalized fair regression methods are empirically studied in simulations, where they achieve a fairness-accuracy frontier beyond that of existing comparison methods. Finally, we apply these methods to a national multi-site primary care study of chronic kidney disease to develop a fair classifier for end-stage renal disease. There we find substantial improvements in fairness for multiple race and ethnicity groups who experience societal bias in the health care system without any appreciable loss in overall fit.
Net benefit, calibration, threshold selection, and training objectives for algorithmic fairness in healthcare
Feb 03, 2022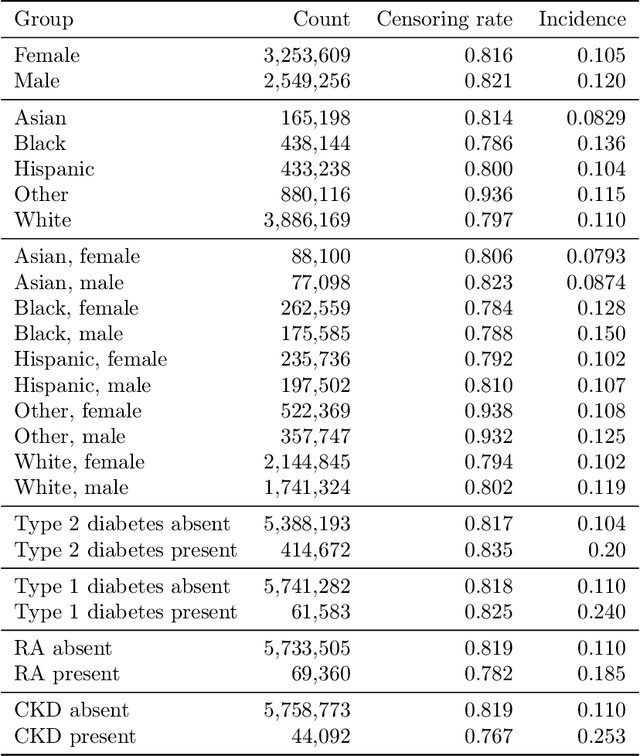
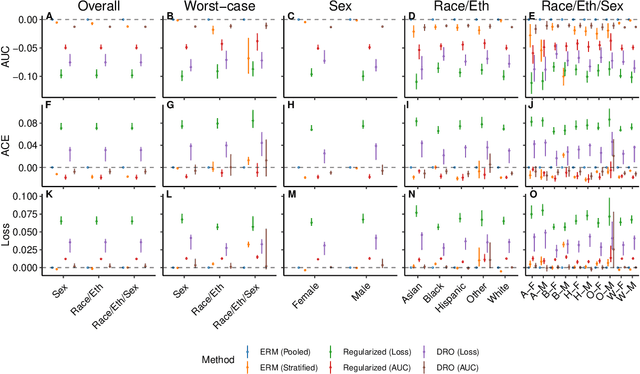
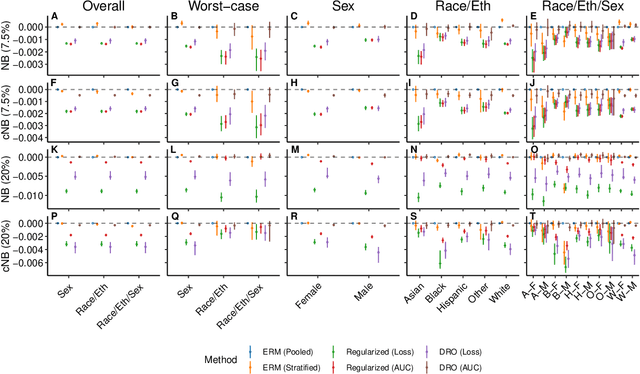
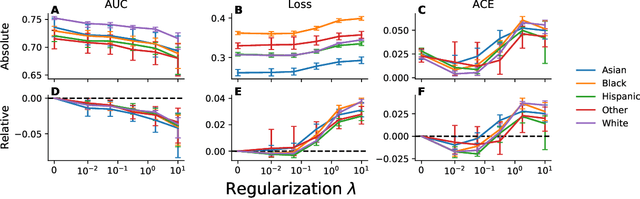
A growing body of work uses the paradigm of algorithmic fairness to frame the development of techniques to anticipate and proactively mitigate the introduction or exacerbation of health inequities that may follow from the use of model-guided decision-making. We evaluate the interplay between measures of model performance, fairness, and the expected utility of decision-making to offer practical recommendations for the operationalization of algorithmic fairness principles for the development and evaluation of predictive models in healthcare. We conduct an empirical case-study via development of models to estimate the ten-year risk of atherosclerotic cardiovascular disease to inform statin initiation in accordance with clinical practice guidelines. We demonstrate that approaches that incorporate fairness considerations into the model training objective typically do not improve model performance or confer greater net benefit for any of the studied patient populations compared to the use of standard learning paradigms followed by threshold selection concordant with patient preferences, evidence of intervention effectiveness, and model calibration. These results hold when the measured outcomes are not subject to differential measurement error across patient populations and threshold selection is unconstrained, regardless of whether differences in model performance metrics, such as in true and false positive error rates, are present. In closing, we argue for focusing model development efforts on developing calibrated models that predict outcomes well for all patient populations while emphasizing that such efforts are complementary to transparent reporting, participatory design, and reasoning about the impact of model-informed interventions in context.
A comparison of approaches to improve worst-case predictive model performance over patient subpopulations
Aug 27, 2021
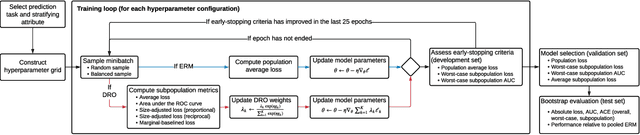
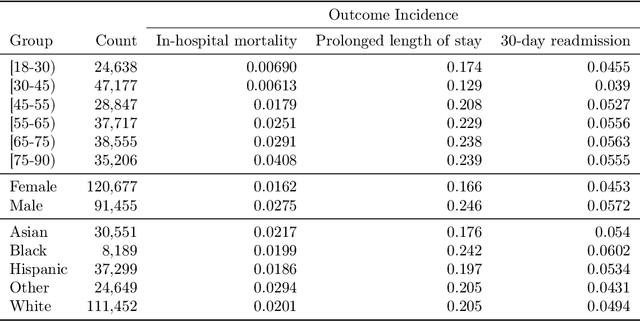
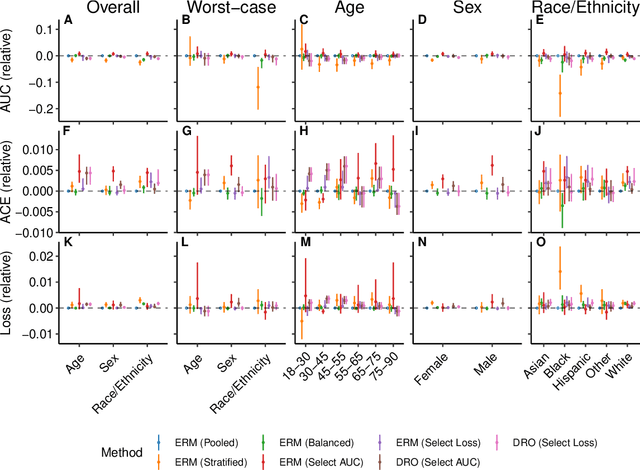
Predictive models for clinical outcomes that are accurate on average in a patient population may underperform drastically for some subpopulations, potentially introducing or reinforcing inequities in care access and quality. Model training approaches that aim to maximize worst-case model performance across subpopulations, such as distributionally robust optimization (DRO), attempt to address this problem without introducing additional harms. We conduct a large-scale empirical study of DRO and several variations of standard learning procedures to identify approaches for model development and selection that consistently improve disaggregated and worst-case performance over subpopulations compared to standard approaches for learning predictive models from electronic health records data. In the course of our evaluation, we introduce an extension to DRO approaches that allows for specification of the metric used to assess worst-case performance. We conduct the analysis for models that predict in-hospital mortality, prolonged length of stay, and 30-day readmission for inpatient admissions, and predict in-hospital mortality using intensive care data. We find that, with relatively few exceptions, no approach performs better, for each patient subpopulation examined, than standard learning procedures using the entire training dataset. These results imply that when it is of interest to improve model performance for patient subpopulations beyond what can be achieved with standard practices, it may be necessary to do so via techniques that implicitly or explicitly increase the effective sample size.
An Empirical Characterization of Fair Machine Learning For Clinical Risk Prediction
Jul 20, 2020



The use of machine learning to guide clinical decision making has the potential to worsen existing health disparities. Several recent works frame the problem as that of algorithmic fairness, a framework that has attracted considerable attention and criticism. However, the appropriateness of this framework is unclear due to both ethical as well as technical considerations, the latter of which include trade-offs between measures of fairness and model performance that are not well-understood for predictive models of clinical outcomes. To inform the ongoing debate, we conduct an empirical study to characterize the impact of penalizing group fairness violations on an array of measures of model performance and group fairness. We repeat the analyses across multiple observational healthcare databases, clinical outcomes, and sensitive attributes. We find that procedures that penalize differences between the distributions of predictions across groups induce nearly-universal degradation of multiple performance metrics within groups. On examining the secondary impact of these procedures, we observe heterogeneity of the effect of these procedures on measures of fairness in calibration and ranking across experimental conditions. Beyond the reported trade-offs, we emphasize that analyses of algorithmic fairness in healthcare lack the contextual grounding and causal awareness necessary to reason about the mechanisms that lead to health disparities, as well as about the potential of algorithmic fairness methods to counteract those mechanisms. In light of these limitations, we encourage researchers building predictive models for clinical use to step outside the algorithmic fairness frame and engage critically with the broader sociotechnical context surrounding the use of machine learning in healthcare.
Zero-Shot Transfer Learning with Synthesized Data for Multi-Domain Dialogue State Tracking
May 02, 2020



Zero-shot transfer learning for multi-domain dialogue state tracking can allow us to handle new domains without incurring the high cost of data acquisition. This paper proposes new zero-short transfer learning technique for dialogue state tracking where the in-domain training data are all synthesized from an abstract dialogue model and the ontology of the domain. We show that data augmentation through synthesized data can improve the accuracy of zero-shot learning for both the TRADE model and the BERT-based SUMBT model on the MultiWOZ 2.1 dataset. We show training with only synthesized in-domain data on the SUMBT model can reach about 2/3 of the accuracy obtained with the full training dataset. We improve the zero-shot learning state of the art on average across domains by 21%.