 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHovering Control of Flapping Wings in Tandem with Multi-Rotors
Jul 31, 2023



This work briefly covers our efforts to stabilize the flight dynamics of Northeastern's tailless bat-inspired micro aerial vehicle, Aerobat. Flapping robots are not new. A plethora of examples is mainly dominated by insect-style design paradigms that are passively stable. However, Aerobat, in addition for being tailless, possesses morphing wings that add to the inherent complexity of flight control. The robot can dynamically adjust its wing platform configurations during gait cycles, increasing its efficiency and agility. We employ a guard design with manifold small thrusters to stabilize Aerobat's position and orientation in hovering, a flapping system in tandem with a multi-rotor. For flight control purposes, we take an approach based on assuming the guard cannot observe Aerobat's states. Then, we propose an observer to estimate the unknown states of the guard which are then used for closed-loop hovering control of the Guard-Aerobat platform.
The Shaky Foundations of Clinical Foundation Models: A Survey of Large Language Models and Foundation Models for EMRs
Mar 24, 2023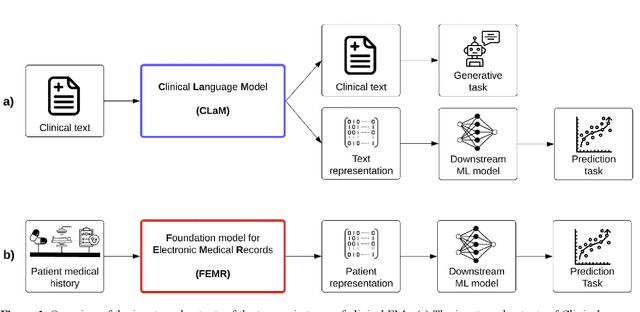
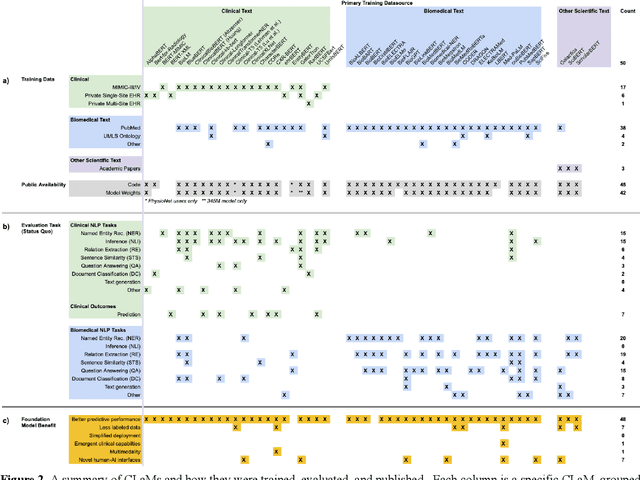
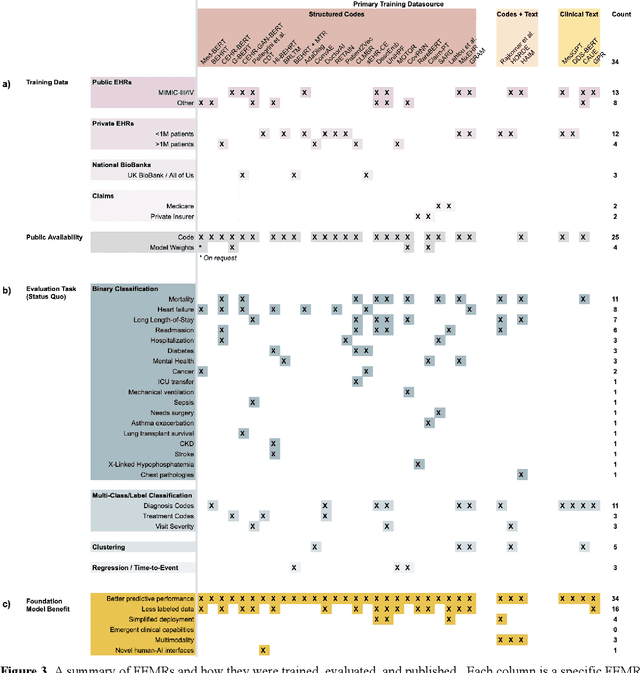

The successes of foundation models such as ChatGPT and AlphaFold have spurred significant interest in building similar models for electronic medical records (EMRs) to improve patient care and hospital operations. However, recent hype has obscured critical gaps in our understanding of these models' capabilities. We review over 80 foundation models trained on non-imaging EMR data (i.e. clinical text and/or structured data) and create a taxonomy delineating their architectures, training data, and potential use cases. We find that most models are trained on small, narrowly-scoped clinical datasets (e.g. MIMIC-III) or broad, public biomedical corpora (e.g. PubMed) and are evaluated on tasks that do not provide meaningful insights on their usefulness to health systems. In light of these findings, we propose an improved evaluation framework for measuring the benefits of clinical foundation models that is more closely grounded to metrics that matter in healthcare.
Self-Supervised Time-to-Event Modeling with Structured Medical Records
Jan 09, 2023



Time-to-event models (also known as survival models) are used in medicine and other fields for estimating the probability distribution of the time until a particular event occurs. While providing many advantages over traditional classification models, such as naturally handling censoring, time-to-event models require more parameters and are challenging to learn in settings with limited labeled training data. High censoring rates, common in events with long time horizons, further limit available training data and exacerbate the risk of overfitting. Existing methods, such as proportional hazard or accelerated failure time-based approaches, employ distributional assumptions to reduce parameter size, but they are vulnerable to model misspecification. In this work, we address these challenges with MOTOR, a self-supervised model that leverages temporal structure found in large-scale collections of timestamped, but largely unlabeled events, typical of electronic health record data. MOTOR defines a time-to-event pretraining task that naturally captures the probability distribution of event times, making it well-suited to applications in medicine. After pretraining on 8,192 tasks auto-generated from 2.7M patients (2.4B clinical events), we evaluate the performance of our pretrained model after fine-tuning to unseen time-to-event tasks. MOTOR-derived models improve upon current state-of-the-art C statistic performance by 6.6% and decrease training time (in wall time) by up to 8.2 times. We further improve sample efficiency, with adapted models matching current state-of-the-art performance using 95% less training data.
An Efficient Approach for Optimizing the Cost-effective Individualized Treatment Rule Using Conditional Random Forest
Apr 23, 2022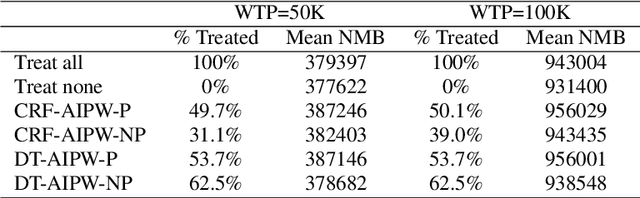
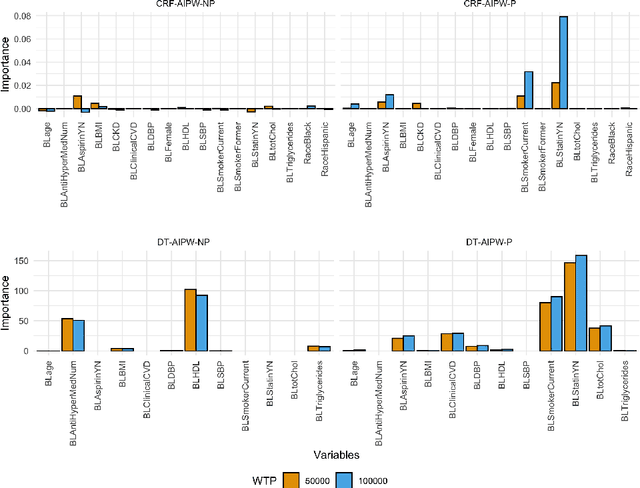
Evidence from observational studies has become increasingly important for supporting healthcare policy making via cost-effectiveness (CE) analyses. Similar as in comparative effectiveness studies, health economic evaluations that consider subject-level heterogeneity produce individualized treatment rules (ITRs) that are often more cost-effective than one-size-fits-all treatment. Thus, it is of great interest to develop statistical tools for learning such a cost-effective ITR (CE-ITR) under the causal inference framework that allows proper handling of potential confounding and can be applied to both trials and observational studies. In this paper, we use the concept of net-monetary-benefit (NMB) to assess the trade-off between health benefits and related costs. We estimate CE-ITR as a function of patients' characteristics that, when implemented, optimizes the allocation of limited healthcare resources by maximizing health gains while minimizing treatment-related costs. We employ the conditional random forest approach and identify the optimal CE-ITR using NMB-based classification algorithms, where two partitioned estimators are proposed for the subject-specific weights to effectively incorporate information from censored individuals. We conduct simulation studies to evaluate the performance of our proposals. We apply our top-performing algorithm to the NIH-funded Systolic Blood Pressure Intervention Trial (SPRINT) to illustrate the CE gains of assigning customized intensive blood pressure therapy.
Calibration Error for Heterogeneous Treatment Effects
Mar 24, 2022
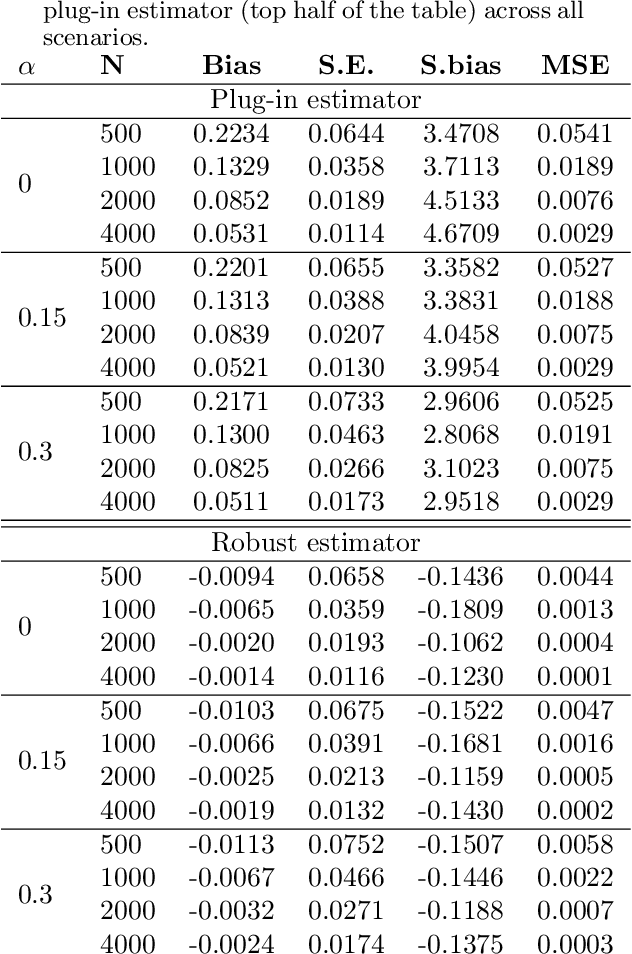
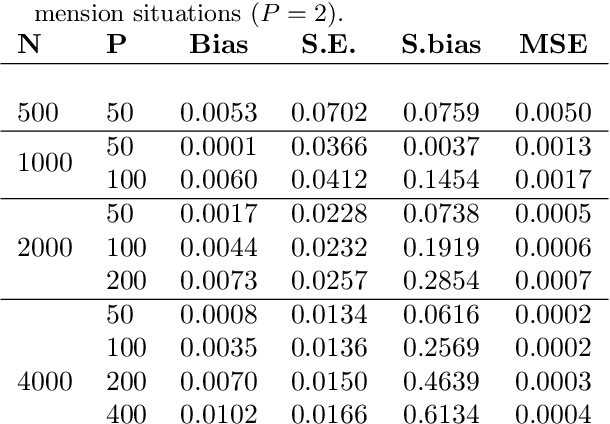
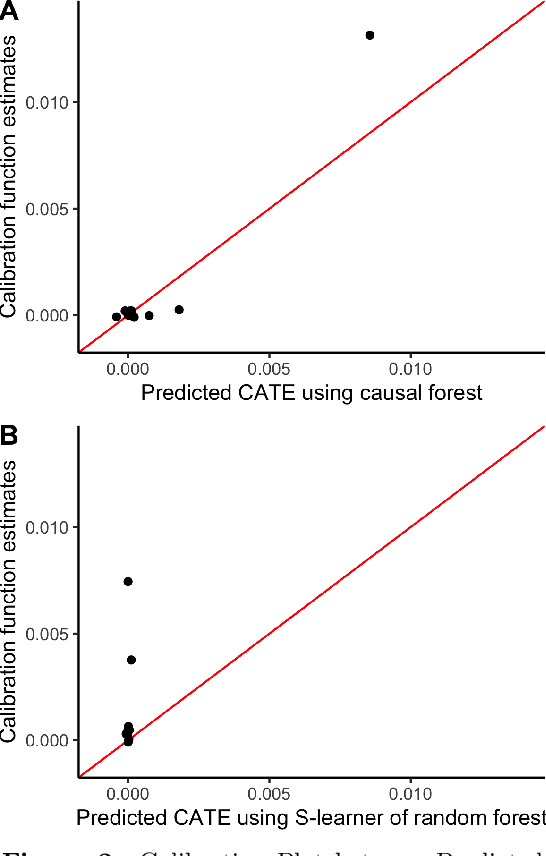
Recently, many researchers have advanced data-driven methods for modeling heterogeneous treatment effects (HTEs). Even still, estimation of HTEs is a difficult task -- these methods frequently over- or under-estimate the treatment effects, leading to poor calibration of the resulting models. However, while many methods exist for evaluating the calibration of prediction and classification models, formal approaches to assess the calibration of HTE models are limited to the calibration slope. In this paper, we define an analogue of the \smash{($\ell_2$)} expected calibration error for HTEs, and propose a robust estimator. Our approach is motivated by doubly robust treatment effect estimators, making it unbiased, and resilient to confounding, overfitting, and high-dimensionality issues. Furthermore, our method is straightforward to adapt to many structures under which treatment effects can be identified, including randomized trials, observational studies, and survival analysis. We illustrate how to use our proposed metric to evaluate the calibration of learned HTE models through the application to the CRITEO-UPLIFT Trial.
Net benefit, calibration, threshold selection, and training objectives for algorithmic fairness in healthcare
Feb 03, 2022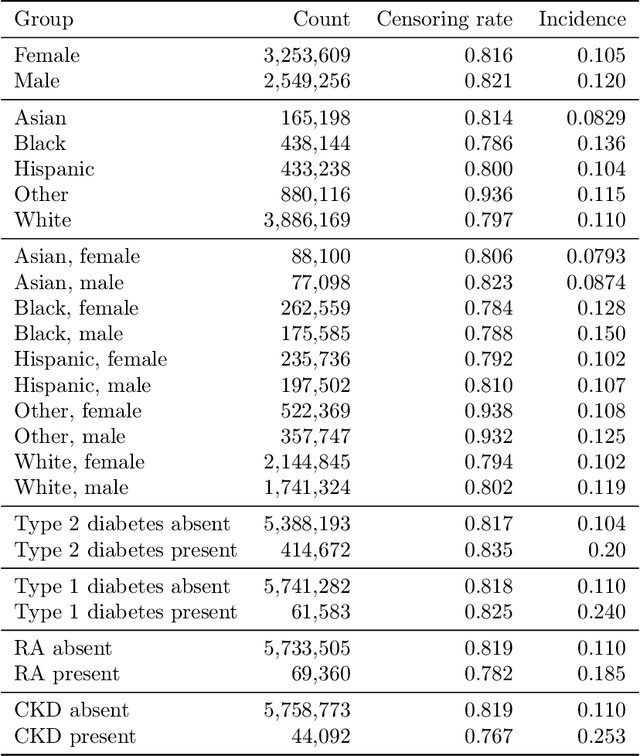
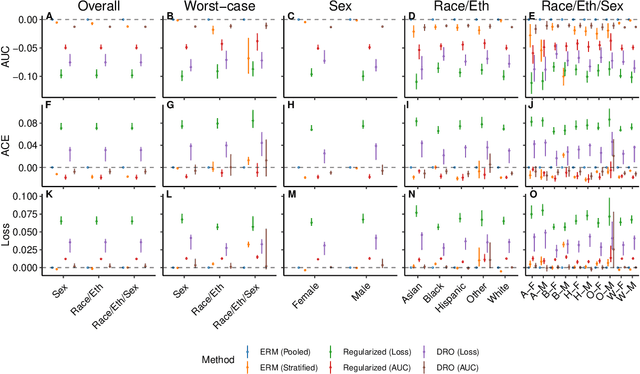
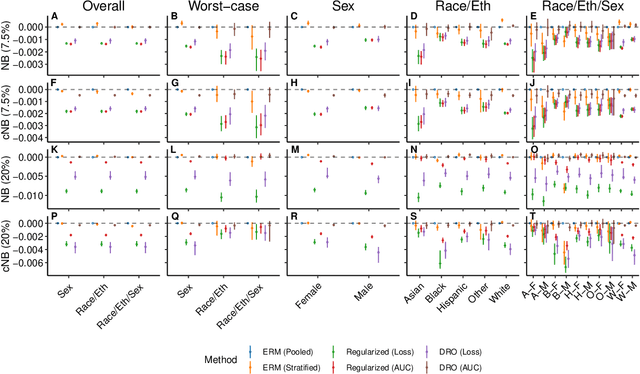
A growing body of work uses the paradigm of algorithmic fairness to frame the development of techniques to anticipate and proactively mitigate the introduction or exacerbation of health inequities that may follow from the use of model-guided decision-making. We evaluate the interplay between measures of model performance, fairness, and the expected utility of decision-making to offer practical recommendations for the operationalization of algorithmic fairness principles for the development and evaluation of predictive models in healthcare. We conduct an empirical case-study via development of models to estimate the ten-year risk of atherosclerotic cardiovascular disease to inform statin initiation in accordance with clinical practice guidelines. We demonstrate that approaches that incorporate fairness considerations into the model training objective typically do not improve model performance or confer greater net benefit for any of the studied patient populations compared to the use of standard learning paradigms followed by threshold selection concordant with patient preferences, evidence of intervention effectiveness, and model calibration. These results hold when the measured outcomes are not subject to differential measurement error across patient populations and threshold selection is unconstrained, regardless of whether differences in model performance metrics, such as in true and false positive error rates, are present. In closing, we argue for focusing model development efforts on developing calibrated models that predict outcomes well for all patient populations while emphasizing that such efforts are complementary to transparent reporting, participatory design, and reasoning about the impact of model-informed interventions in context.
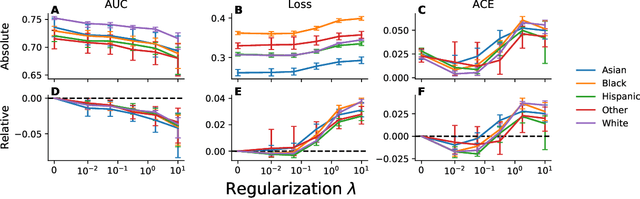
A comparison of approaches to improve worst-case predictive model performance over patient subpopulations
Aug 27, 2021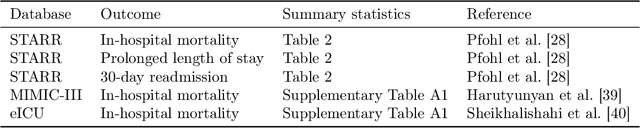
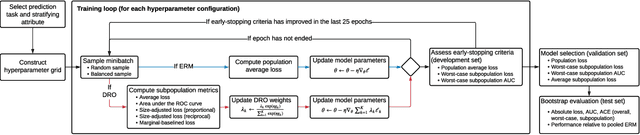
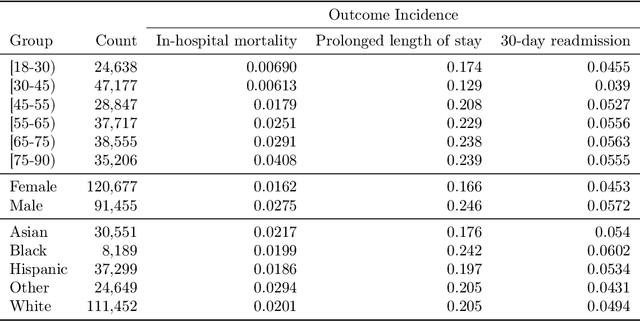
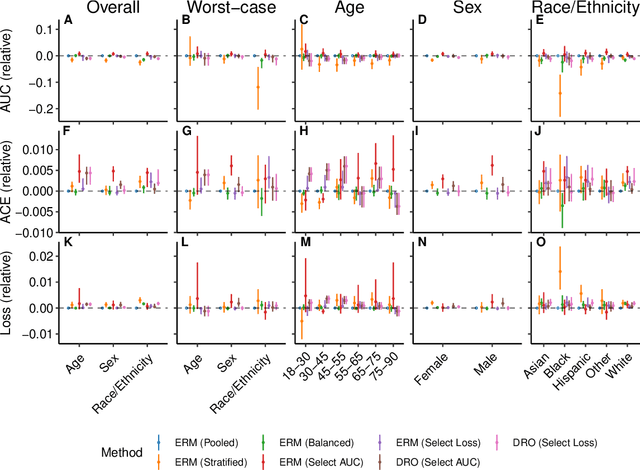
Predictive models for clinical outcomes that are accurate on average in a patient population may underperform drastically for some subpopulations, potentially introducing or reinforcing inequities in care access and quality. Model training approaches that aim to maximize worst-case model performance across subpopulations, such as distributionally robust optimization (DRO), attempt to address this problem without introducing additional harms. We conduct a large-scale empirical study of DRO and several variations of standard learning procedures to identify approaches for model development and selection that consistently improve disaggregated and worst-case performance over subpopulations compared to standard approaches for learning predictive models from electronic health records data. In the course of our evaluation, we introduce an extension to DRO approaches that allows for specification of the metric used to assess worst-case performance. We conduct the analysis for models that predict in-hospital mortality, prolonged length of stay, and 30-day readmission for inpatient admissions, and predict in-hospital mortality using intensive care data. We find that, with relatively few exceptions, no approach performs better, for each patient subpopulation examined, than standard learning procedures using the entire training dataset. These results imply that when it is of interest to improve model performance for patient subpopulations beyond what can be achieved with standard practices, it may be necessary to do so via techniques that implicitly or explicitly increase the effective sample size.