 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Quadrupedal Legged and Aerial Locomotion via Structure Repurposing
Oct 10, 2025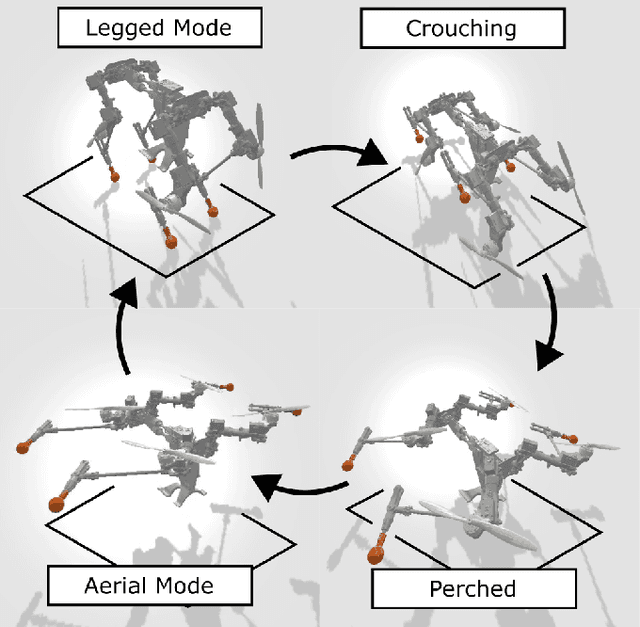
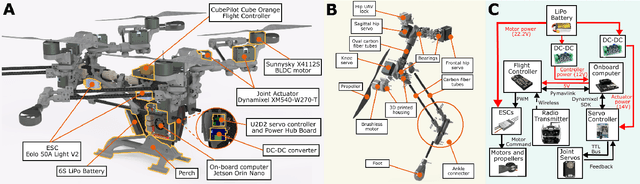

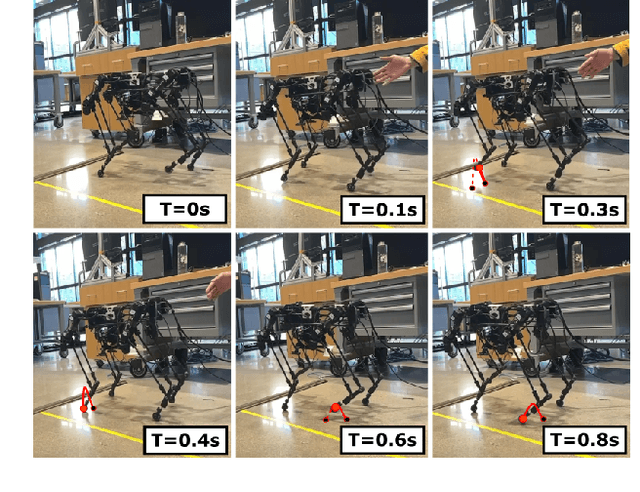
Multi-modal ground-aerial robots have been extensively studied, with a significant challenge lying in the integration of conflicting requirements across different modes of operation. The Husky robot family, developed at Northeastern University, and specifically the Husky v.2 discussed in this study, addresses this challenge by incorporating posture manipulation and thrust vectoring into multi-modal locomotion through structure repurposing. This quadrupedal robot features leg structures that can be repurposed for dynamic legged locomotion and flight. In this paper, we present the hardware design of the robot and report primary results on dynamic quadrupedal legged locomotion and hovering.
Self-supervised cost of transport estimation for multimodal path planning
Dec 08, 2024Autonomous robots operating in real environments are often faced with decisions on how best to navigate their surroundings. In this work, we address a particular instance of this problem: how can a robot autonomously decide on the energetically optimal path to follow given a high-level objective and information about the surroundings? To tackle this problem we developed a self-supervised learning method that allows the robot to estimate the cost of transport of its surroundings using only vision inputs. We apply our method to the multi-modal mobility morphobot (M4), a robot that can drive, fly, segway, and crawl through its environment. By deploying our system in the real world, we show that our method accurately assigns different cost of transports to various types of environments e.g. grass vs smooth road. We also highlight the low computational cost of our method, which is deployed on an Nvidia Jetson Orin Nano robotic compute unit. We believe that this work will allow multi-modal robotic platforms to unlock their full potential for navigation and exploration tasks.
How Strong a Kick Should be to Topple Northeastern's Tumbling Robot?
Nov 25, 2023



Rough terrain locomotion has remained one of the most challenging mobility questions. In 2022, NASA's Innovative Advanced Concepts (NIAC) Program invited US academic institutions to participate NASA's Breakthrough, Innovative \& Game-changing (BIG) Idea competition by proposing novel mobility systems that can negotiate extremely rough terrain, lunar bumpy craters. In this competition, Northeastern University won NASA's top Artemis Award award by proposing an articulated robot tumbler called COBRA (Crater Observing Bio-inspired Rolling Articulator). This report briefly explains the underlying principles that made COBRA successful in competing with other concepts ranging from cable-driven to multi-legged designs from six other participating US institutions.
Demonstrating Autonomous 3D Path Planning on a Novel Scalable UGV-UAV Morphing Robot
Aug 01, 2023



Some animals exhibit multi-modal locomotion capability to traverse a wide range of terrains and environments, such as amphibians that can swim and walk or birds that can fly and walk. This capability is extremely beneficial for expanding the animal's habitat range and they can choose the most energy efficient mode of locomotion in a given environment. The robotic biomimicry of this multi-modal locomotion capability can be very challenging but offer the same advantages. However, the expanded range of locomotion also increases the complexity of performing localization and path planning. In this work, we present our morphing multi-modal robot, which is capable of ground and aerial locomotion, and the implementation of readily available SLAM and path planning solutions to navigate a complex indoor environment.
Hovering Control of Flapping Wings in Tandem with Multi-Rotors
Jul 31, 2023



This work briefly covers our efforts to stabilize the flight dynamics of Northeastern's tailless bat-inspired micro aerial vehicle, Aerobat. Flapping robots are not new. A plethora of examples is mainly dominated by insect-style design paradigms that are passively stable. However, Aerobat, in addition for being tailless, possesses morphing wings that add to the inherent complexity of flight control. The robot can dynamically adjust its wing platform configurations during gait cycles, increasing its efficiency and agility. We employ a guard design with manifold small thrusters to stabilize Aerobat's position and orientation in hovering, a flapping system in tandem with a multi-rotor. For flight control purposes, we take an approach based on assuming the guard cannot observe Aerobat's states. Then, we propose an observer to estimate the unknown states of the guard which are then used for closed-loop hovering control of the Guard-Aerobat platform.
Learning swimming escape patterns under energy constraints
May 03, 2021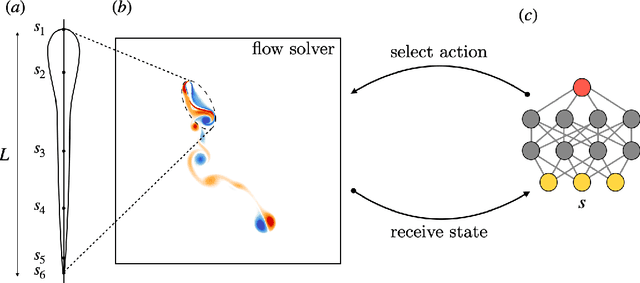
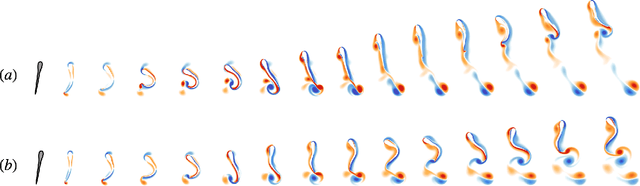
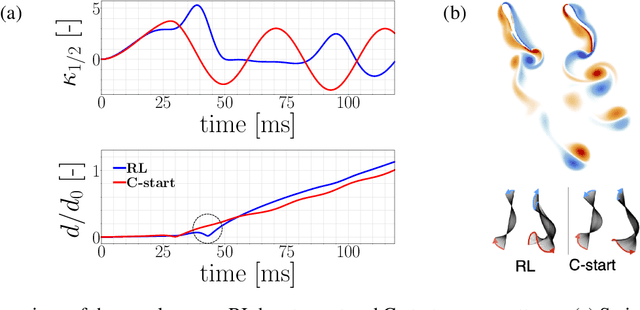

Swimming organisms can escape their predators by creating and harnessing unsteady flow fields through their body motions. Stochastic optimization and flow simulations have identified escape patterns that are consistent with those observed in natural larval swimmers. However, these patterns have been limited by the specification of a particular cost function and depend on a prescribed functional form of the body motion. Here, we deploy reinforcement learning to discover swimmer escape patterns under energy constraints. The identified patterns include the C-start mechanism, in addition to more energetically efficient escapes. We find that maximizing distance with limited energy requires swimming via short bursts of accelerating motion interlinked with phases of gliding. The present, data efficient, reinforcement learning algorithm results in an array of patterns that reveal practical flow optimization principles for efficient swimming and the methodology can be transferred to the control of aquatic robotic devices operating under energy constraints.
Learning Efficient Navigation in Vortical Flow Fields
Feb 21, 2021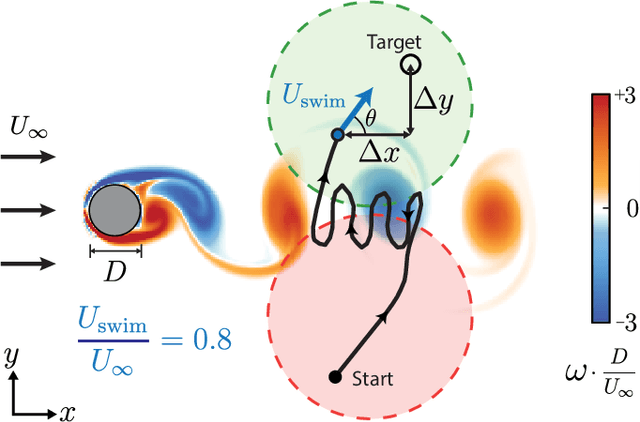
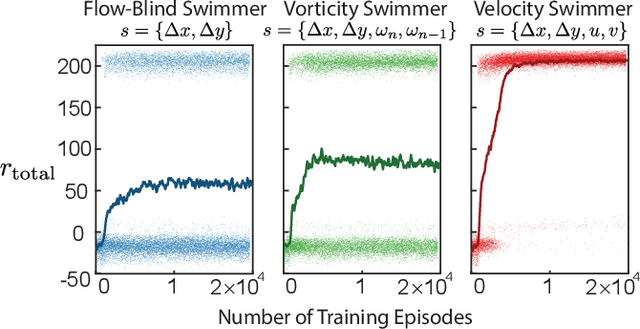

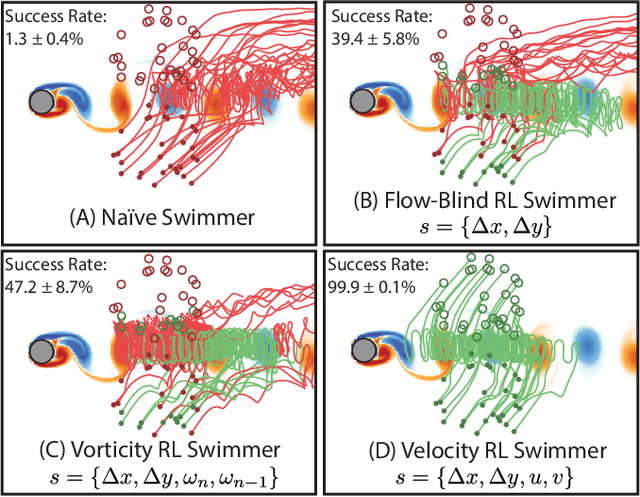
Efficient point-to-point navigation in the presence of a background flow field is important for robotic applications such as ocean surveying. In such applications, robots may only have knowledge of their immediate surroundings or be faced with time-varying currents, which limits the use of optimal control techniques for planning trajectories. Here, we apply a novel Reinforcement Learning algorithm to discover time-efficient navigation policies to steer a fixed-speed swimmer through an unsteady two-dimensional flow field. The algorithm entails inputting environmental cues into a deep neural network that determines the swimmer's actions, and deploying Remember and Forget Experience replay. We find that the resulting swimmers successfully exploit the background flow to reach the target, but that this success depends on the type of sensed environmental cue. Surprisingly, a velocity sensing approach outperformed a bio-mimetic vorticity sensing approach by nearly two-fold in success rate. Equipped with local velocity measurements, the reinforcement learning algorithm achieved near 100% success in reaching the target locations while approaching the time-efficiency of paths found by a global optimal control planner.