 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphology-preserving Autoregressive 3D Generative Modelling of the Brain
Sep 07, 2022
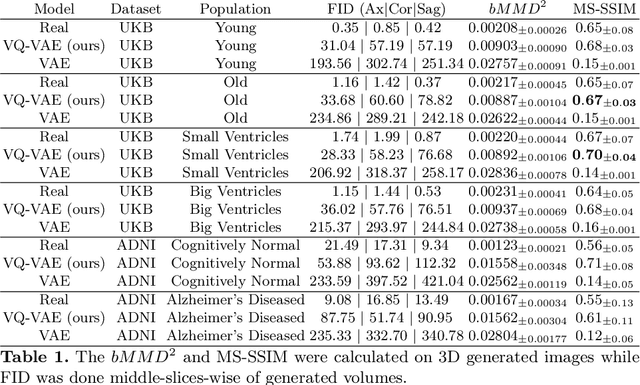
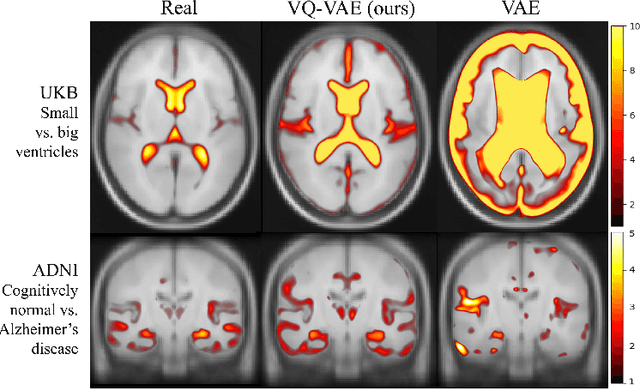
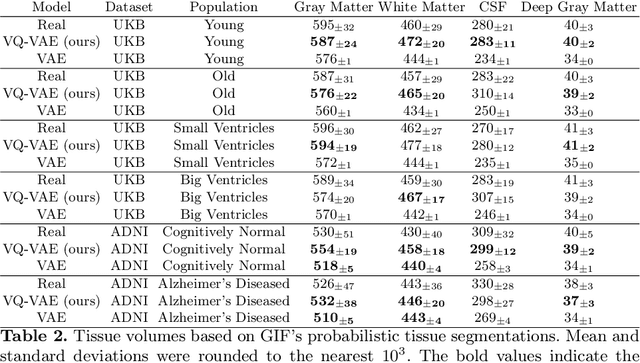
Human anatomy, morphology, and associated diseases can be studied using medical imaging data. However, access to medical imaging data is restricted by governance and privacy concerns, data ownership, and the cost of acquisition, thus limiting our ability to understand the human body. A possible solution to this issue is the creation of a model able to learn and then generate synthetic images of the human body conditioned on specific characteristics of relevance (e.g., age, sex, and disease status). Deep generative models, in the form of neural networks, have been recently used to create synthetic 2D images of natural scenes. Still, the ability to produce high-resolution 3D volumetric imaging data with correct anatomical morphology has been hampered by data scarcity and algorithmic and computational limitations. This work proposes a generative model that can be scaled to produce anatomically correct, high-resolution, and realistic images of the human brain, with the necessary quality to allow further downstream analyses. The ability to generate a potentially unlimited amount of data not only enables large-scale studies of human anatomy and pathology without jeopardizing patient privacy, but also significantly advances research in the field of anomaly detection, modality synthesis, learning under limited data, and fair and ethical AI. Code and trained models are available at: https://github.com/AmigoLab/SynthAnatomy.
Learning swimming escape patterns under energy constraints
May 03, 2021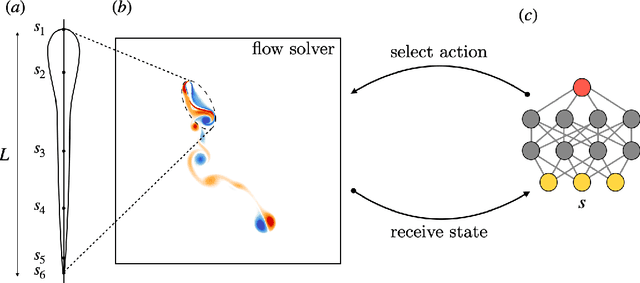
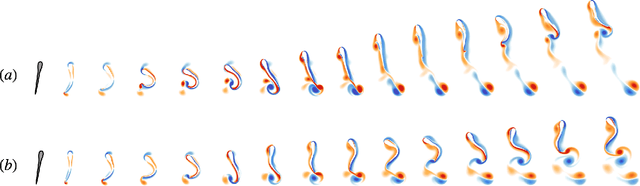
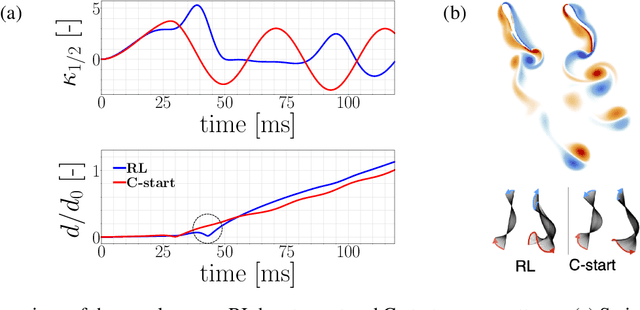

Swimming organisms can escape their predators by creating and harnessing unsteady flow fields through their body motions. Stochastic optimization and flow simulations have identified escape patterns that are consistent with those observed in natural larval swimmers. However, these patterns have been limited by the specification of a particular cost function and depend on a prescribed functional form of the body motion. Here, we deploy reinforcement learning to discover swimmer escape patterns under energy constraints. The identified patterns include the C-start mechanism, in addition to more energetically efficient escapes. We find that maximizing distance with limited energy requires swimming via short bursts of accelerating motion interlinked with phases of gliding. The present, data efficient, reinforcement learning algorithm results in an array of patterns that reveal practical flow optimization principles for efficient swimming and the methodology can be transferred to the control of aquatic robotic devices operating under energy constraints.
Learning Efficient Navigation in Vortical Flow Fields
Feb 21, 2021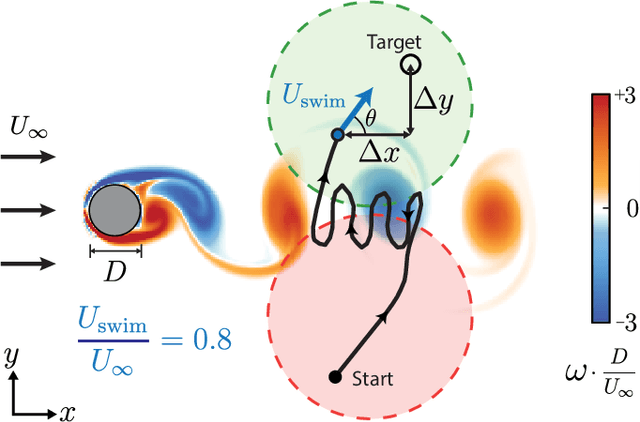
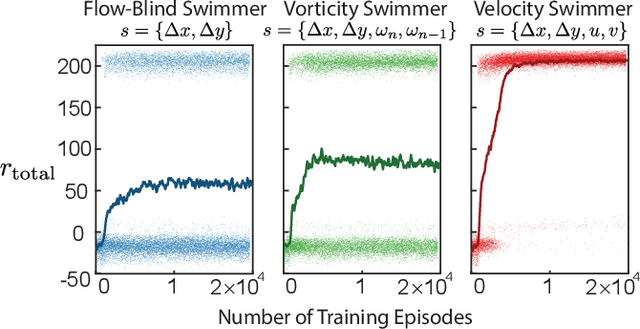

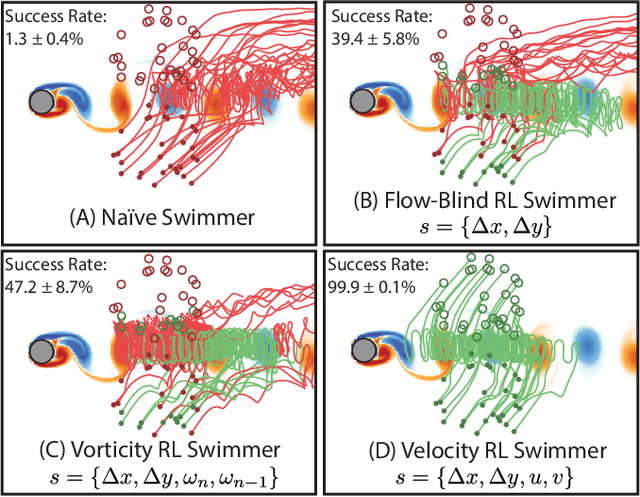
Efficient point-to-point navigation in the presence of a background flow field is important for robotic applications such as ocean surveying. In such applications, robots may only have knowledge of their immediate surroundings or be faced with time-varying currents, which limits the use of optimal control techniques for planning trajectories. Here, we apply a novel Reinforcement Learning algorithm to discover time-efficient navigation policies to steer a fixed-speed swimmer through an unsteady two-dimensional flow field. The algorithm entails inputting environmental cues into a deep neural network that determines the swimmer's actions, and deploying Remember and Forget Experience replay. We find that the resulting swimmers successfully exploit the background flow to reach the target, but that this success depends on the type of sensed environmental cue. Surprisingly, a velocity sensing approach outperformed a bio-mimetic vorticity sensing approach by nearly two-fold in success rate. Equipped with local velocity measurements, the reinforcement learning algorithm achieved near 100% success in reaching the target locations while approaching the time-efficiency of paths found by a global optimal control planner.
Improved Memories Learning
Aug 24, 2020


We propose Improved Memories Learning (IMeL), a novel algorithm that turns reinforcement learning (RL) into a supervised learning (SL) problem and delimits the role of neural networks (NN) to interpolation. IMeL consists of two components. The first is a reservoir of experiences. Each experience is updated based on a non-parametric procedural improvement of the policy, computed as a bounded one-sample Monte Carlo estimate. The second is a NN regressor, which receives as input improved experiences from the reservoir (context points) and computes the policy by interpolation. The NN learns to measure the similarity between states in order to compute long-term forecasts by averaging experiences, rather than by encoding the problem structure in the NN parameters. We present preliminary results and propose IMeL as a baseline method for assessing the merits of more complex models and inductive biases.
Automating Turbulence Modeling by Multi-Agent Reinforcement Learning
May 18, 2020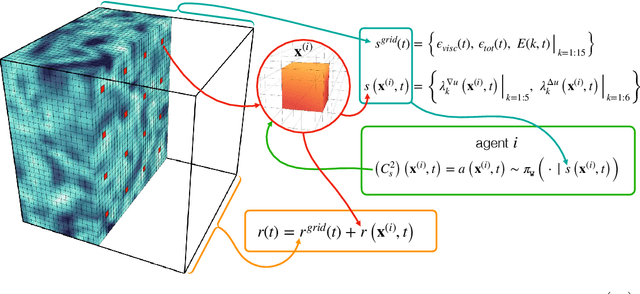
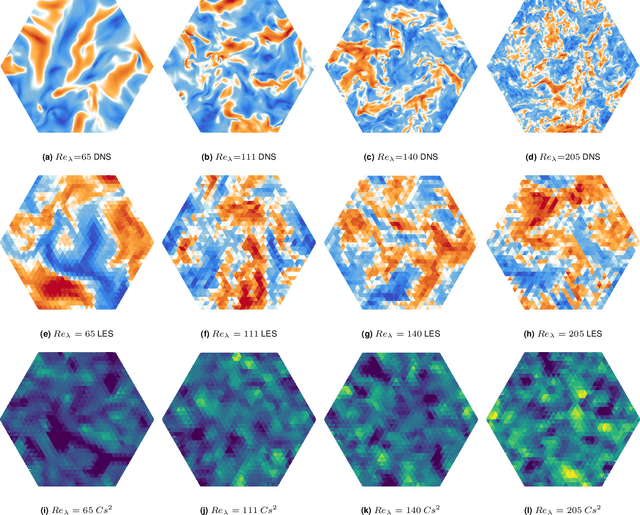
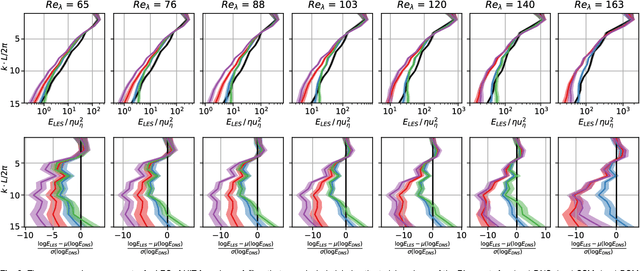
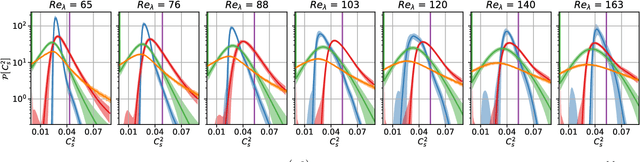
The modeling of turbulent flows is critical to scientific and engineering problems ranging from aircraft design to weather forecasting and climate prediction. Over the last sixty years numerous turbulence models have been proposed, largely based on physical insight and engineering intuition. Recent advances in machine learning and data science have incited new efforts to complement these approaches. To date, all such efforts have focused on supervised learning which, despite demonstrated promise, encounters difficulties in generalizing beyond the distributions of the training data. In this work we introduce multi-agent reinforcement learning (MARL) as an automated discovery tool of turbulence models. We demonstrate the potential of this approach on Large Eddy Simulations of homogeneous and isotropic turbulence using as reward the recovery of the statistical properties of Direct Numerical Simulations. Here, the closure model is formulated as a control policy enacted by cooperating agents, which detect critical spatio-temporal patterns in the flow field to estimate the unresolved sub-grid scale (SGS) physics. The present results are obtained with state-of-the-art algorithms based on experience replay and compare favorably with established dynamic SGS modeling approaches. Moreover, we show that the present turbulence models generalize across grid sizes and flow conditions as expressed by the Reynolds numbers.
Remember and Forget for Experience Replay
Oct 03, 2018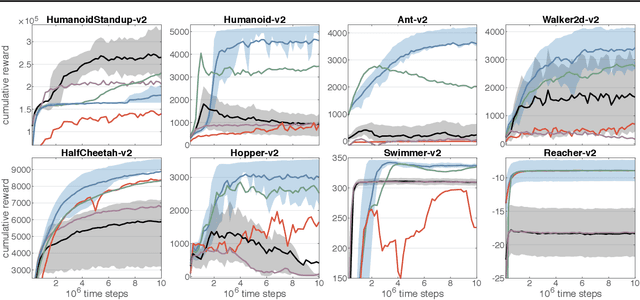

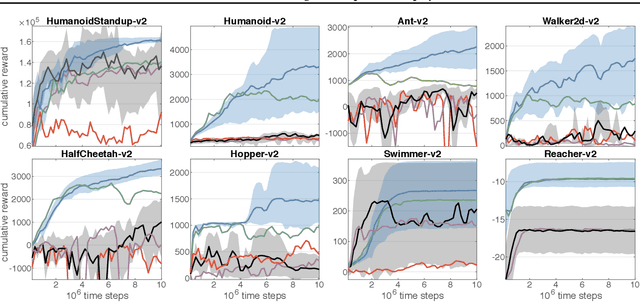
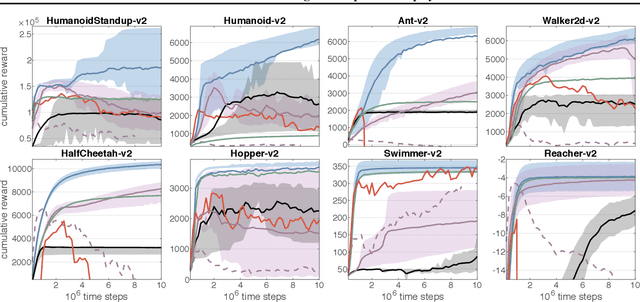
Experience replay (ER) is crucial for attaining high data-efficiency in off-policy reinforcement learning (RL). ER entails the recall of experiences obtained in past iterations to compute gradient estimates for the current policy. However, the accuracy of such updates may deteriorate when the policy diverges from past behaviors, possibly undermining the effectiveness of ER. Previous off-policy RL algorithms mitigated this issue by tuning hyper-parameters in order to abate policy changes. We propose a method for ER that relies on systematically Remembering and Forgetting past behaviors (ReF-ER). ReF-ER forgets experiences that would be too unlikely with the current policy and constrains policy changes within a trust region of the behaviors in the replay memory. We couple ReF-ER with Q-learning, deterministic policy gradient and off-policy gradient methods and we show that ReF-ER reliably improves the performance of continuous-action off-policy RL. We complement ReF-ER with a novel off-policy actor-critic algorithm (RACER) for continuous-action control. RACER employs a computationally efficient closed-form approximation of the action values and is shown to be highly competitive with state-of-the-art algorithms on benchmark problems, while being robust to large hyper-parameter variations.
Deep-Reinforcement-Learning for Gliding and Perching Bodies
Jul 07, 2018
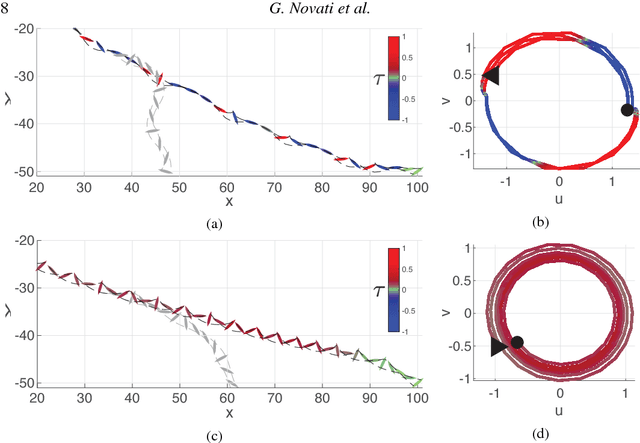
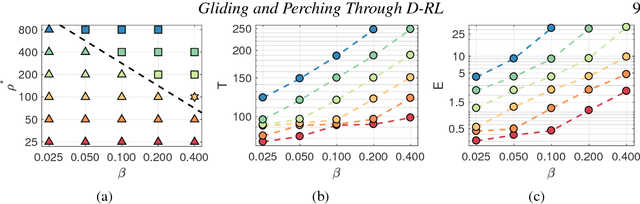
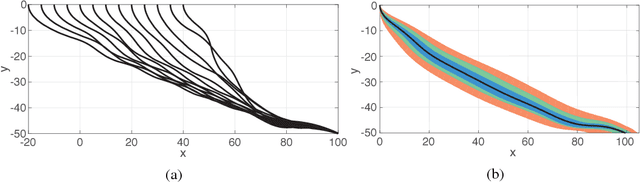
Controlled gliding is one of the most energetically efficient modes of transportation for natural and human powered fliers. Here we demonstrate that gliding and landing strategies with different optimality criteria can be identified through deep reinforcement learning without explicit knowledge of the underlying physics. We combine a two dimensional model of a controlled elliptical body with deep reinforcement learning (D-RL) to achieve gliding with either minimum energy expenditure, or fastest time of arrival, at a predetermined location. In both cases the gliding trajectories are smooth, although energy/time optimal strategies are distinguished by small/high frequency actuations. We examine the effects of the ellipse's shape and weight on the optimal policies for controlled gliding. Surprisingly, we find that the model-free reinforcement learning leads to more robust gliding than model-based optimal control strategies with a modest additional computational cost. We also demonstrate that the gliders with D-RL can generalize their strategies to reach the target location from previously unseen starting positions. The model-free character and robustness of D-RL suggests a promising framework for developing mechanical devices capable of exploiting complex flow environments.
Efficient collective swimming by harnessing vortices through deep reinforcement learning
Feb 07, 2018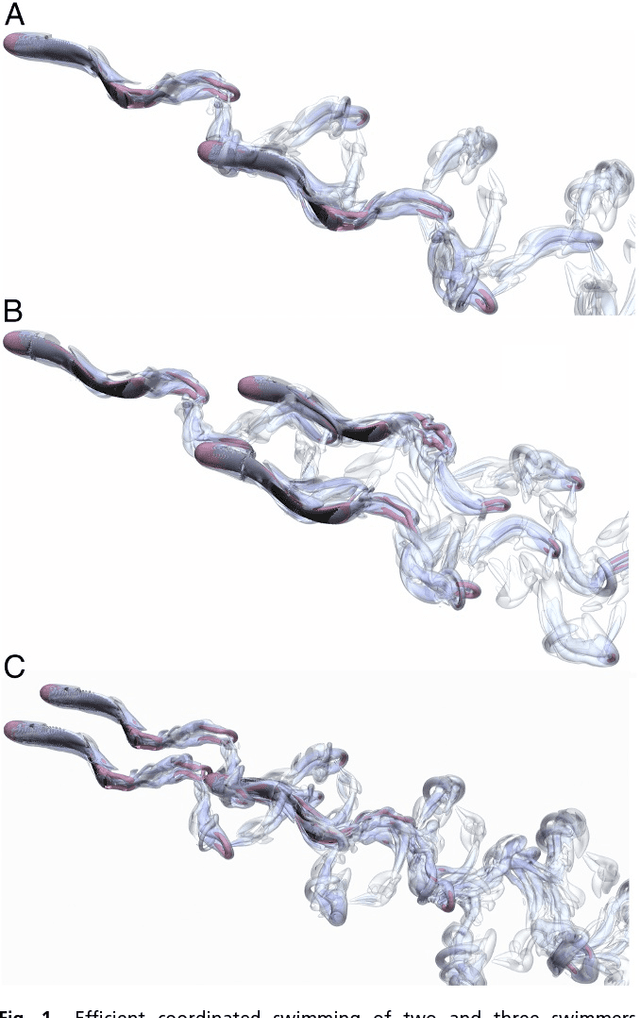
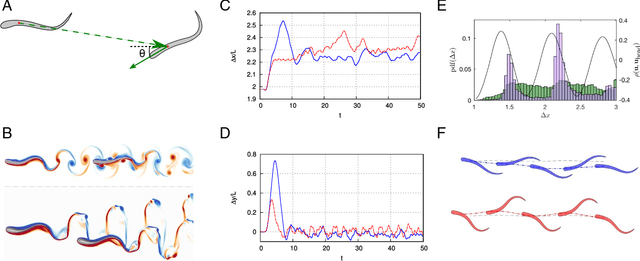
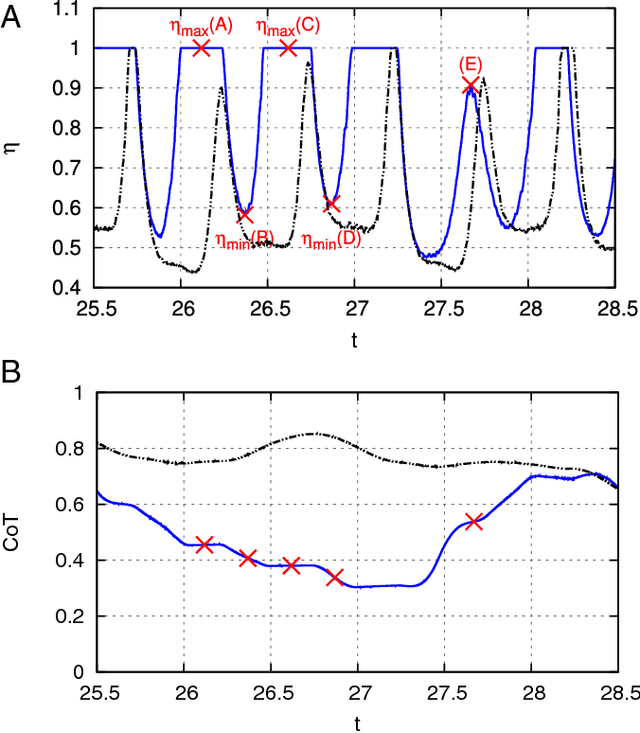
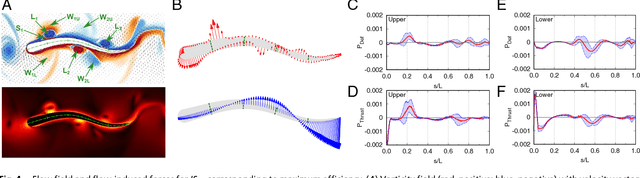
Fish in schooling formations navigate complex flow-fields replete with mechanical energy in the vortex wakes of their companions. Their schooling behaviour has been associated with evolutionary advantages including collective energy savings. How fish harvest energy from their complex fluid environment and the underlying physical mechanisms governing energy-extraction during collective swimming, is still unknown. Here we show that fish can improve their sustained propulsive efficiency by actively following, and judiciously intercepting, vortices in the wake of other swimmers. This swimming strategy leads to collective energy-savings and is revealed through the first ever combination of deep reinforcement learning with high-fidelity flow simulations. We find that a `smart-swimmer' can adapt its position and body deformation to synchronise with the momentum of the oncoming vortices, improving its average swimming-efficiency at no cost to the leader. The results show that fish may harvest energy deposited in vortices produced by their peers, and support the conjecture that swimming in formation is energetically advantageous. Moreover, this study demonstrates that deep reinforcement learning can produce navigation algorithms for complex flow-fields, with promising implications for energy savings in autonomous robotic swarms.