 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember and Forget for Experience Replay
Paper and Code
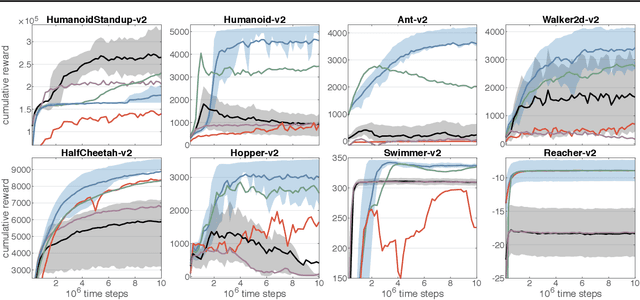

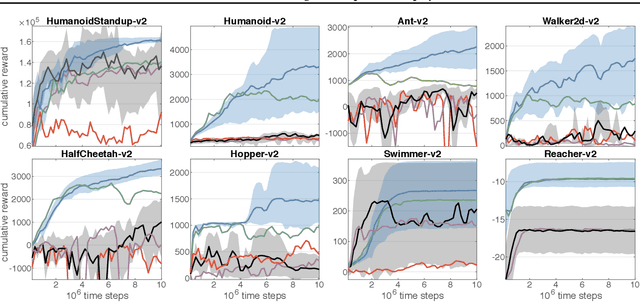
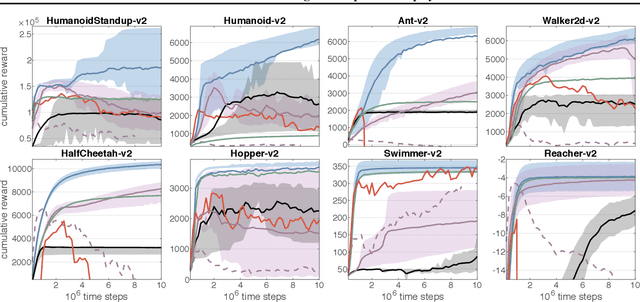
Experience replay (ER) is crucial for attaining high data-efficiency in off-policy reinforcement learning (RL). ER entails the recall of experiences obtained in past iterations to compute gradient estimates for the current policy. However, the accuracy of such updates may deteriorate when the policy diverges from past behaviors, possibly undermining the effectiveness of ER. Previous off-policy RL algorithms mitigated this issue by tuning hyper-parameters in order to abate policy changes. We propose a method for ER that relies on systematically Remembering and Forgetting past behaviors (ReF-ER). ReF-ER forgets experiences that would be too unlikely with the current policy and constrains policy changes within a trust region of the behaviors in the replay memory. We couple ReF-ER with Q-learning, deterministic policy gradient and off-policy gradient methods and we show that ReF-ER reliably improves the performance of continuous-action off-policy RL. We complement ReF-ER with a novel off-policy actor-critic algorithm (RACER) for continuous-action control. RACER employs a computationally efficient closed-form approximation of the action values and is shown to be highly competitive with state-of-the-art algorithms on benchmark problems, while being robust to large hyper-parameter variations.