 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shaky Foundations of Clinical Foundation Models: A Survey of Large Language Models and Foundation Models for EMRs
Mar 24, 2023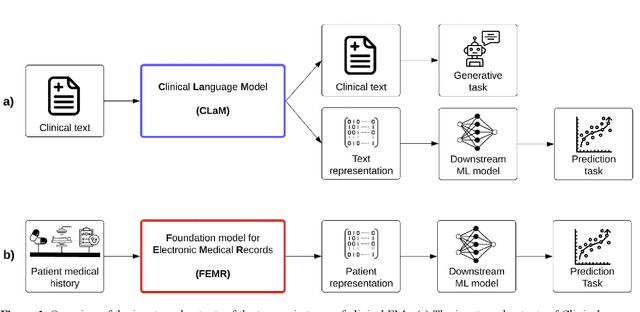
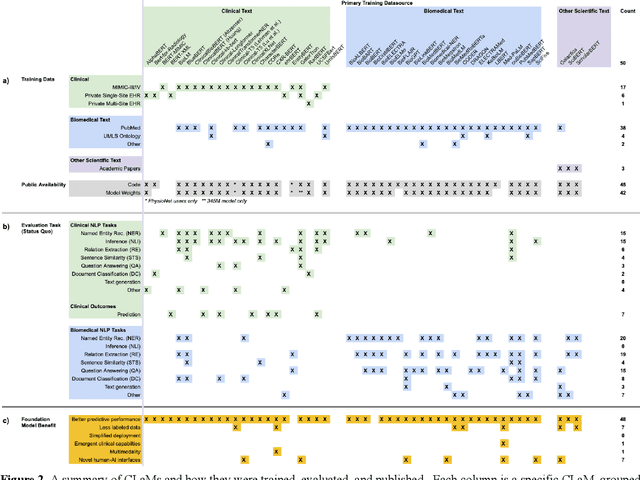
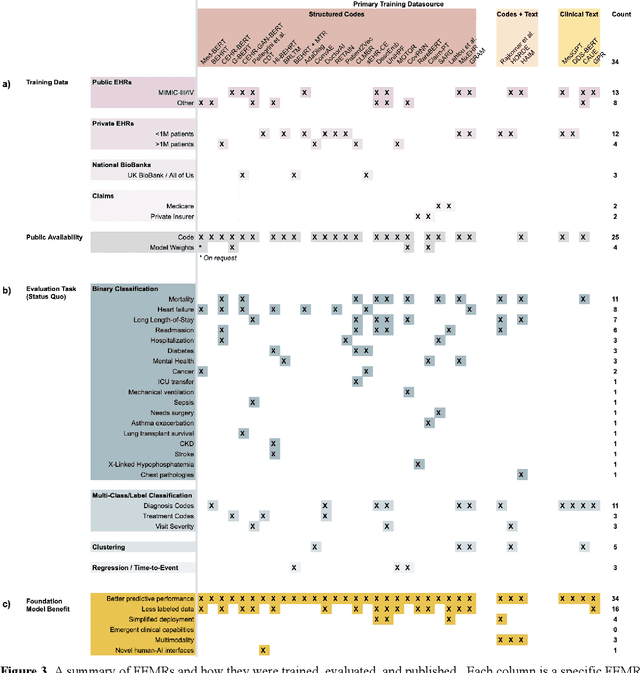

The successes of foundation models such as ChatGPT and AlphaFold have spurred significant interest in building similar models for electronic medical records (EMRs) to improve patient care and hospital operations. However, recent hype has obscured critical gaps in our understanding of these models' capabilities. We review over 80 foundation models trained on non-imaging EMR data (i.e. clinical text and/or structured data) and create a taxonomy delineating their architectures, training data, and potential use cases. We find that most models are trained on small, narrowly-scoped clinical datasets (e.g. MIMIC-III) or broad, public biomedical corpora (e.g. PubMed) and are evaluated on tasks that do not provide meaningful insights on their usefulness to health systems. In light of these findings, we propose an improved evaluation framework for measuring the benefits of clinical foundation models that is more closely grounded to metrics that matter in healthcare.
Evaluating Treatment Prioritization Rules via Rank-Weighted Average Treatment Effects
Nov 15, 2021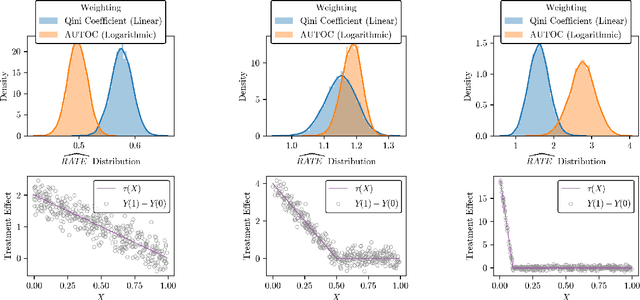
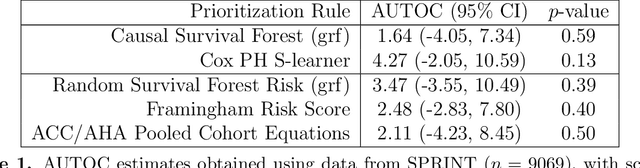
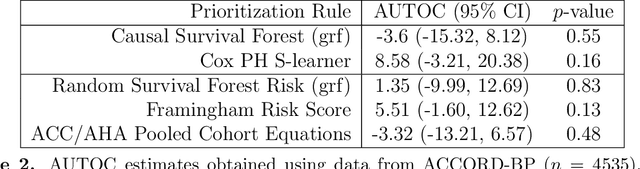
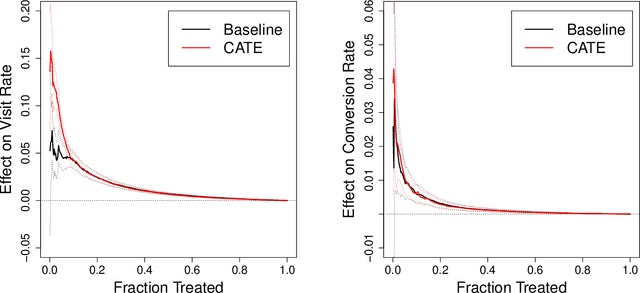
There are a number of available methods that can be used for choosing whom to prioritize treatment, including ones based on treatment effect estimation, risk scoring, and hand-crafted rules. We propose rank-weighted average treatment effect (RATE) metrics as a simple and general family of metrics for comparing treatment prioritization rules on a level playing field. RATEs are agnostic as to how the prioritization rules were derived, and only assesses them based on how well they succeed in identifying units that benefit the most from treatment. We define a family of RATE estimators and prove a central limit theorem that enables asymptotically exact inference in a wide variety of randomized and observational study settings. We provide justification for the use of bootstrapped confidence intervals and a framework for testing hypotheses about heterogeneity in treatment effectiveness correlated with the prioritization rule. Our definition of the RATE nests a number of existing metrics, including the Qini coefficient, and our analysis directly yields inference methods for these metrics. We demonstrate our approach in examples drawn from both personalized medicine and marketing. In the medical setting, using data from the SPRINT and ACCORD-BP randomized control trials, we find no significant evidence of heterogeneous treatment effects. On the other hand, in a large marketing trial, we find robust evidence of heterogeneity in the treatment effects of some digital advertising campaigns and demonstrate how RATEs can be used to compare targeting rules that prioritize estimated risk vs. those that prioritize estimated treatment benefit.