 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Fusion for High-Resolution Estimation
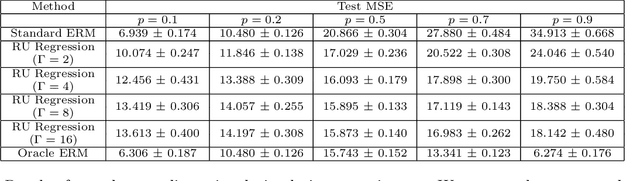
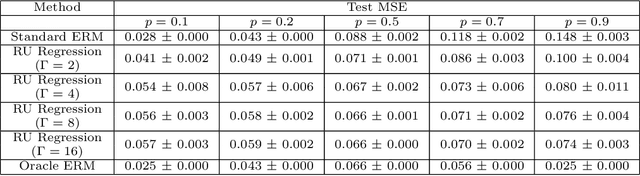
Aug 20, 2025High-resolution estimates of population health indicators are critical for precision public health. We propose a method for high-resolution estimation that fuses distinct data sources: an unbiased, low-resolution data source (e.g. aggregated administrative data) and a potentially biased, high-resolution data source (e.g. individual-level online survey responses). We assume that the potentially biased, high-resolution data source is generated from the population under a model of sampling bias where observables can have arbitrary impact on the probability of response but the difference in the log probabilities of response between units with the same observables is linear in the difference between sufficient statistics of their observables and outcomes. Our data fusion method learns a distribution that is closest (in the sense of KL divergence) to the online survey distribution and consistent with the aggregated administrative data and our model of sampling bias. This method outperforms baselines that rely on either data source alone on a testbed that includes repeated measurements of three indicators measured by both the (online) Household Pulse Survey and ground-truth data sources at two geographic resolutions over the same time period.
Admissibility of Completely Randomized Trials: A Large-Deviation Approach
Jun 05, 2025When an experimenter has the option of running an adaptive trial, is it admissible to ignore this option and run a non-adaptive trial instead? We provide a negative answer to this question in the best-arm identification problem, where the experimenter aims to allocate measurement efforts judiciously to confidently deploy the most effective treatment arm. We find that, whenever there are at least three treatment arms, there exist simple adaptive designs that universally and strictly dominate non-adaptive completely randomized trials. This dominance is characterized by a notion called efficiency exponent, which quantifies a design's statistical efficiency when the experimental sample is large. Our analysis focuses on the class of batched arm elimination designs, which progressively eliminate underperforming arms at pre-specified batch intervals. We characterize simple sufficient conditions under which these designs universally and strictly dominate completely randomized trials. These results resolve the second open problem posed in Qin [2022].
Off-Policy Evaluation in Markov Decision Processes under Weak Distributional Overlap
Feb 13, 2024Doubly robust methods hold considerable promise for off-policy evaluation in Markov decision processes (MDPs) under sequential ignorability: They have been shown to converge as $1/\sqrt{T}$ with the horizon $T$, to be statistically efficient in large samples, and to allow for modular implementation where preliminary estimation tasks can be executed using standard reinforcement learning techniques. Existing results, however, make heavy use of a strong distributional overlap assumption whereby the stationary distributions of the target policy and the data-collection policy are within a bounded factor of each other -- and this assumption is typically only credible when the state space of the MDP is bounded. In this paper, we re-visit the task of off-policy evaluation in MDPs under a weaker notion of distributional overlap, and introduce a class of truncated doubly robust (TDR) estimators which we find to perform well in this setting. When the distribution ratio of the target and data-collection policies is square-integrable (but not necessarily bounded), our approach recovers the large-sample behavior previously established under strong distributional overlap. When this ratio is not square-integrable, TDR is still consistent but with a slower-than-$1/\sqrt{T}$; furthermore, this rate of convergence is minimax over a class of MDPs defined only using mixing conditions. We validate our approach numerically and find that, in our experiments, appropriate truncation plays a major role in enabling accurate off-policy evaluation when strong distributional overlap does not hold.
Learning from a Biased Sample
Sep 05, 2022
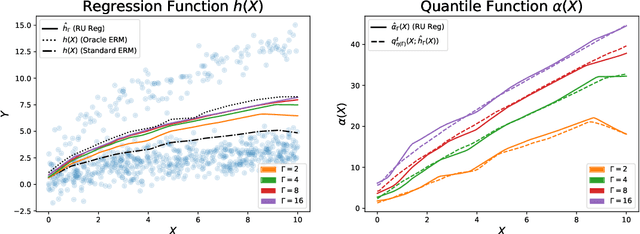
The empirical risk minimization approach to data-driven decision making assumes that we can learn a decision rule from training data drawn under the same conditions as the ones we want to deploy it under. However, in a number of settings, we may be concerned that our training sample is biased, and that some groups (characterized by either observable or unobservable attributes) may be under- or over-represented relative to the general population; and in this setting empirical risk minimization over the training set may fail to yield rules that perform well at deployment. Building on concepts from distributionally robust optimization and sensitivity analysis, we propose a method for learning a decision rule that minimizes the worst-case risk incurred under a family of test distributions whose conditional distributions of outcomes $Y$ given covariates $X$ differ from the conditional training distribution by at most a constant factor, and whose covariate distributions are absolutely continuous with respect to the covariate distribution of the training data. We apply a result of Rockafellar and Uryasev to show that this problem is equivalent to an augmented convex risk minimization problem. We give statistical guarantees for learning a robust model using the method of sieves and propose a deep learning algorithm whose loss function captures our robustness target. We empirically validate our proposed method in simulations and a case study with the MIMIC-III dataset.
What Makes Forest-Based Heterogeneous Treatment Effect Estimators Work?
Jun 21, 2022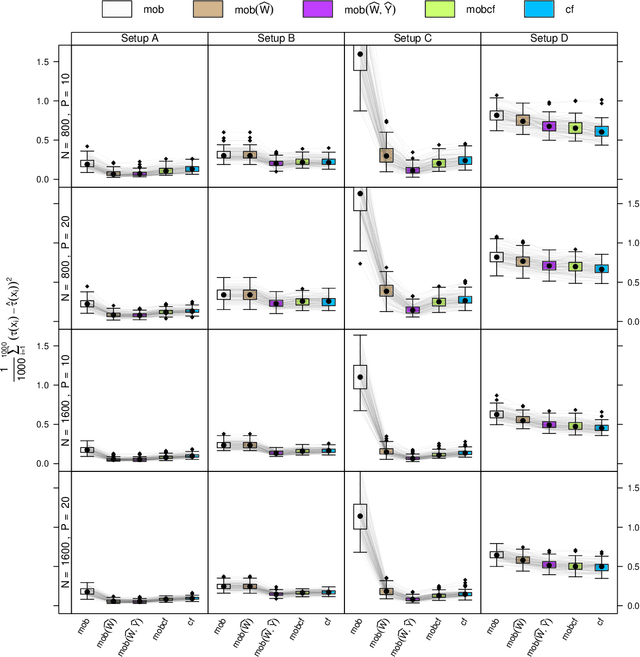
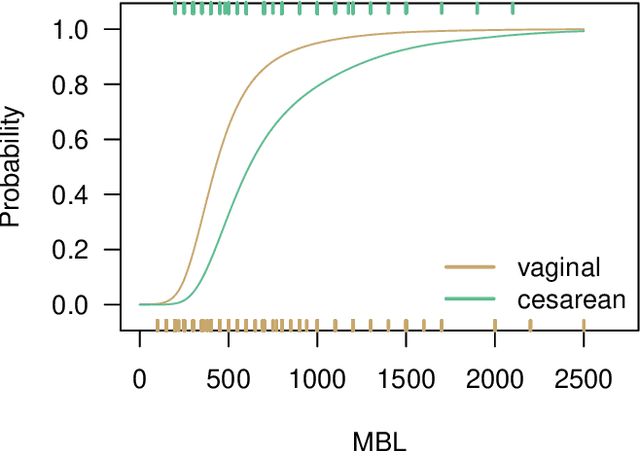
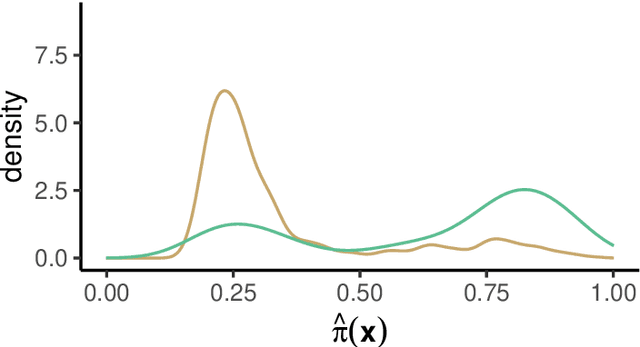
Estimation of heterogeneous treatment effects (HTE) is of prime importance in many disciplines, ranging from personalized medicine to economics among many others. Random forests have been shown to be a flexible and powerful approach to HTE estimation in both randomized trials and observational studies. In particular "causal forests", introduced by Athey, Tibshirani and Wager (2019), along with the R implementation in package grf were rapidly adopted. A related approach, called "model-based forests", that is geared towards randomized trials and simultaneously captures effects of both prognostic and predictive variables, was introduced by Seibold, Zeileis and Hothorn (2018) along with a modular implementation in the R package model4you. Here, we present a unifying view that goes beyond the theoretical motivations and investigates which computational elements make causal forests so successful and how these can be blended with the strengths of model-based forests. To do so, we show that both methods can be understood in terms of the same parameters and model assumptions for an additive model under L2 loss. This theoretical insight allows us to implement several flavors of "model-based causal forests" and dissect their different elements in silico. The original causal forests and model-based forests are compared with the new blended versions in a benchmark study exploring both randomized trials and observational settings. In the randomized setting, both approaches performed akin. If confounding was present in the data generating process, we found local centering of the treatment indicator with the corresponding propensities to be the main driver for good performance. Local centering of the outcome was less important, and might be replaced or enhanced by simultaneous split selection with respect to both prognostic and predictive effects.
Policy Learning with Competing Agents
Apr 04, 2022
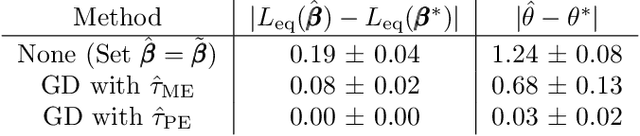
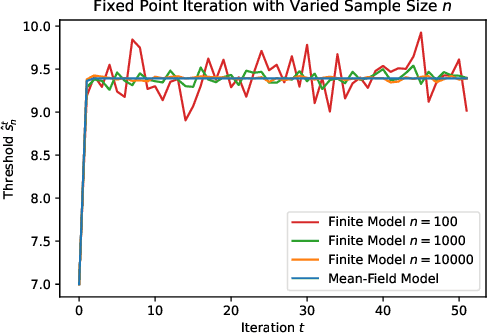
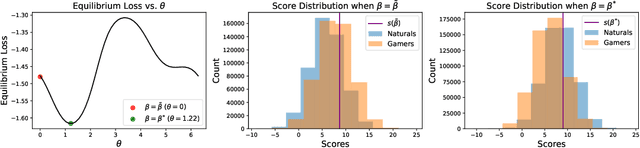
Decision makers often aim to learn a treatment assignment policy under a capacity constraint on the number of agents that they can treat. When agents can respond strategically to such policies, competition arises, complicating the estimation of the effect of the policy. In this paper, we study capacity-constrained treatment assignment in the presence of such interference. We consider a dynamic model where heterogeneous agents myopically best respond to the previous treatment assignment policy. When the number of agents is large but finite, we show that the threshold for receiving treatment under a given policy converges to the policy's mean-field equilibrium threshold. Based on this result, we develop a consistent estimator for the policy effect and demonstrate in simulations that it can be used for learning optimal capacity-constrained policies in the presence of strategic behavior.
Partial Likelihood Thompson Sampling
Mar 02, 2022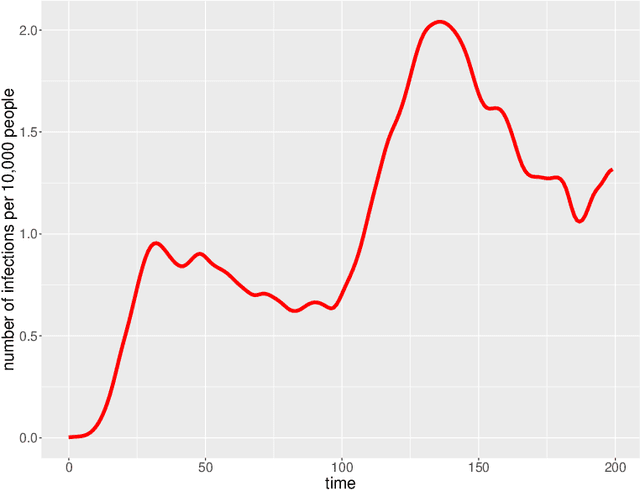
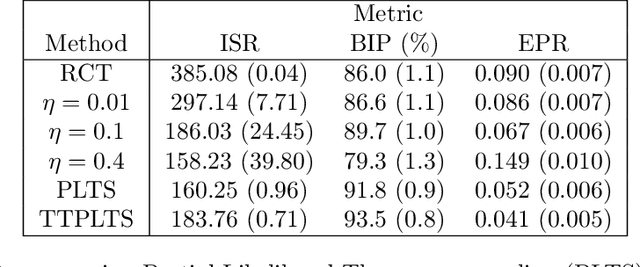
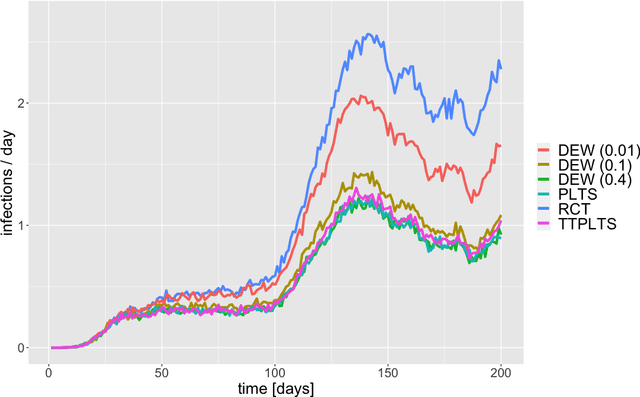
We consider the problem of deciding how best to target and prioritize existing vaccines that may offer protection against new variants of an infectious disease. Sequential experiments are a promising approach; however, challenges due to delayed feedback and the overall ebb and flow of disease prevalence make available method inapplicable for this task. We present a method, partial likelihood Thompson sampling, that can handle these challenges. Our method involves running Thompson sampling with belief updates determined by partial likelihood each time we observe an event. To test our approach, we ran a semi-synthetic experiment based on 200 days of COVID-19 infection data in the US.
Thompson Sampling with Unrestricted Delays
Feb 24, 2022


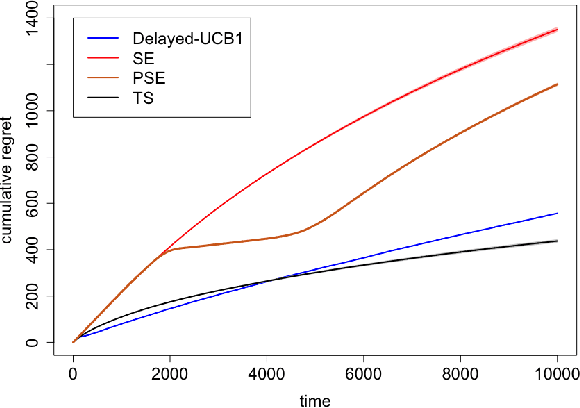
We investigate properties of Thompson Sampling in the stochastic multi-armed bandit problem with delayed feedback. In a setting with i.i.d delays, we establish to our knowledge the first regret bounds for Thompson Sampling with arbitrary delay distributions, including ones with unbounded expectation. Our bounds are qualitatively comparable to the best available bounds derived via ad-hoc algorithms, and only depend on delays via selected quantiles of the delay distributions. Furthermore, in extensive simulation experiments, we find that Thompson Sampling outperforms a number of alternative proposals, including methods specifically designed for settings with delayed feedback.
Evaluating Treatment Prioritization Rules via Rank-Weighted Average Treatment Effects
Nov 15, 2021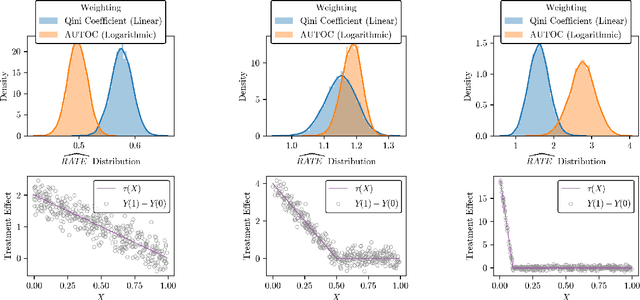
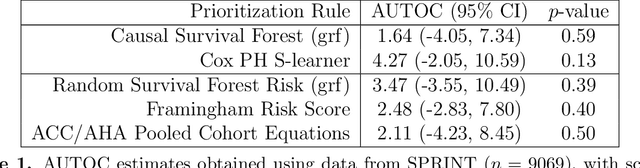
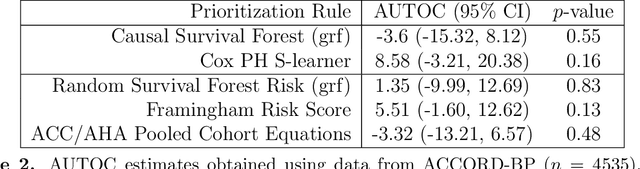
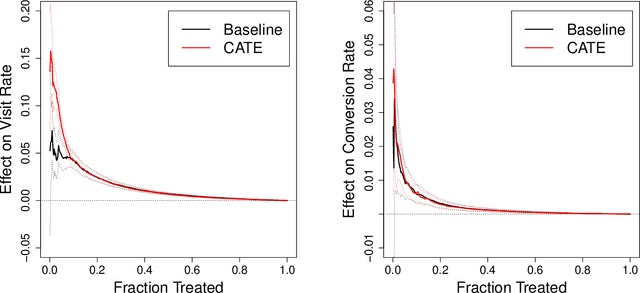
There are a number of available methods that can be used for choosing whom to prioritize treatment, including ones based on treatment effect estimation, risk scoring, and hand-crafted rules. We propose rank-weighted average treatment effect (RATE) metrics as a simple and general family of metrics for comparing treatment prioritization rules on a level playing field. RATEs are agnostic as to how the prioritization rules were derived, and only assesses them based on how well they succeed in identifying units that benefit the most from treatment. We define a family of RATE estimators and prove a central limit theorem that enables asymptotically exact inference in a wide variety of randomized and observational study settings. We provide justification for the use of bootstrapped confidence intervals and a framework for testing hypotheses about heterogeneity in treatment effectiveness correlated with the prioritization rule. Our definition of the RATE nests a number of existing metrics, including the Qini coefficient, and our analysis directly yields inference methods for these metrics. We demonstrate our approach in examples drawn from both personalized medicine and marketing. In the medical setting, using data from the SPRINT and ACCORD-BP randomized control trials, we find no significant evidence of heterogeneous treatment effects. On the other hand, in a large marketing trial, we find robust evidence of heterogeneity in the treatment effects of some digital advertising campaigns and demonstrate how RATEs can be used to compare targeting rules that prioritize estimated risk vs. those that prioritize estimated treatment benefit.
Off-Policy Evaluation in Partially Observed Markov Decision Processes
Oct 24, 2021
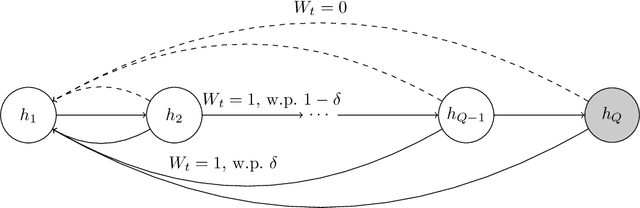
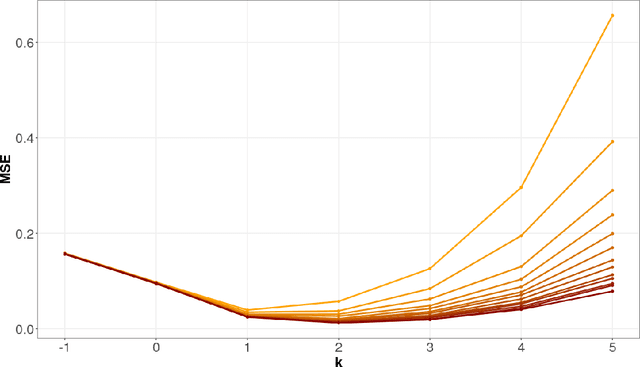
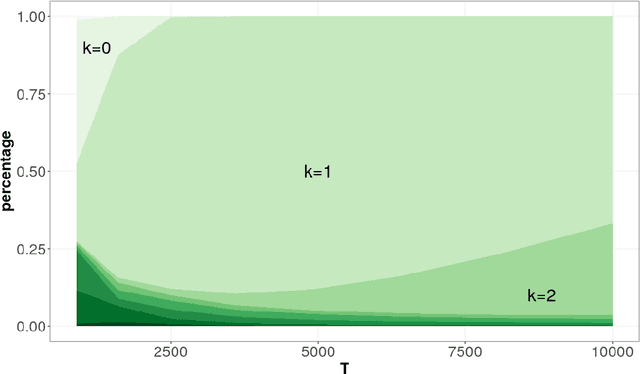
We consider off-policy evaluation of dynamic treatment rules under the assumption that the underlying system can be modeled as a partially observed Markov decision process (POMDP). We propose an estimator, partial history importance weighting, and show that it can consistently estimate the stationary mean rewards of a target policy given long enough draws from the behavior policy. Furthermore, we establish an upper bound on its error that decays polynomially in the number of observations (i.e., the number of trajectories times their length), with an exponent that depends on the overlap of the target and behavior policies, and on the mixing time of the underlying system. We also establish a polynomial minimax lower bound for off-policy evaluation under the POMDP assumption, and show that its exponent has the same qualitative dependence on overlap and mixing time as obtained in our upper bound. Together, our upper and lower bounds imply that off-policy evaluation in POMDPs is strictly harder than off-policy evaluation in (fully observed) Markov decision processes, but strictly easier than model-free off-policy evaluation.