 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivilege Scores
Feb 03, 2025



Bias-transforming methods of fairness-aware machine learning aim to correct a non-neutral status quo with respect to a protected attribute (PA). Current methods, however, lack an explicit formulation of what drives non-neutrality. We introduce privilege scores (PS) to measure PA-related privilege by comparing the model predictions in the real world with those in a fair world in which the influence of the PA is removed. At the individual level, PS can identify individuals who qualify for affirmative action; at the global level, PS can inform bias-transforming policies. After presenting estimation methods for PS, we propose privilege score contributions (PSCs), an interpretation method that attributes the origin of privilege to mediating features and direct effects. We provide confidence intervals for both PS and PSCs. Experiments on simulated and real-world data demonstrate the broad applicability of our methods and provide novel insights into gender and racial privilege in mortgage and college admissions applications.
mlr3summary: Concise and interpretable summaries for machine learning models
Apr 25, 2024
This work introduces a novel R package for concise, informative summaries of machine learning models. We take inspiration from the summary function for (generalized) linear models in R, but extend it in several directions: First, our summary function is model-agnostic and provides a unified summary output also for non-parametric machine learning models; Second, the summary output is more extensive and customizable -- it comprises information on the dataset, model performance, model complexity, model's estimated feature importances, feature effects, and fairness metrics; Third, models are evaluated based on resampling strategies for unbiased estimates of model performances, feature importances, etc. Overall, the clear, structured output should help to enhance and expedite the model selection process, making it a helpful tool for practitioners and researchers alike.
CountARFactuals -- Generating plausible model-agnostic counterfactual explanations with adversarial random forests
Apr 04, 2024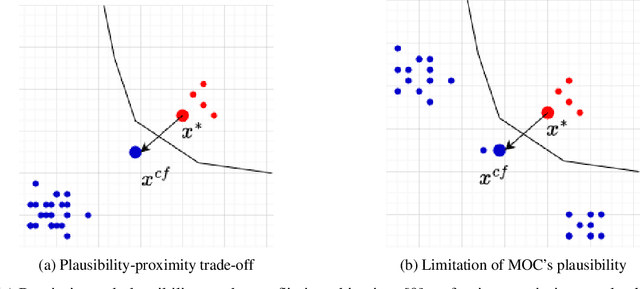


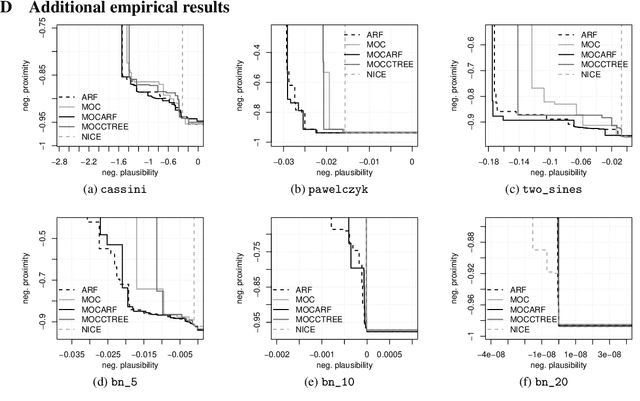
Counterfactual explanations elucidate algorithmic decisions by pointing to scenarios that would have led to an alternative, desired outcome. Giving insight into the model's behavior, they hint users towards possible actions and give grounds for contesting decisions. As a crucial factor in achieving these goals, counterfactuals must be plausible, i.e., describing realistic alternative scenarios within the data manifold. This paper leverages a recently developed generative modeling technique -- adversarial random forests (ARFs) -- to efficiently generate plausible counterfactuals in a model-agnostic way. ARFs can serve as a plausibility measure or directly generate counterfactual explanations. Our ARF-based approach surpasses the limitations of existing methods that aim to generate plausible counterfactual explanations: It is easy to train and computationally highly efficient, handles continuous and categorical data naturally, and allows integrating additional desiderata such as sparsity in a straightforward manner.
Leveraging Model-based Trees as Interpretable Surrogate Models for Model Distillation
Oct 04, 2023
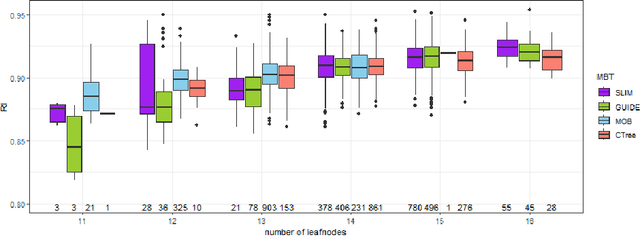

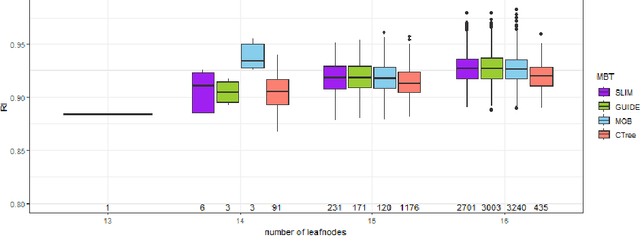
Surrogate models play a crucial role in retrospectively interpreting complex and powerful black box machine learning models via model distillation. This paper focuses on using model-based trees as surrogate models which partition the feature space into interpretable regions via decision rules. Within each region, interpretable models based on additive main effects are used to approximate the behavior of the black box model, striking for an optimal balance between interpretability and performance. Four model-based tree algorithms, namely SLIM, GUIDE, MOB, and CTree, are compared regarding their ability to generate such surrogate models. We investigate fidelity, interpretability, stability, and the algorithms' capability to capture interaction effects through appropriate splits. Based on our comprehensive analyses, we finally provide an overview of user-specific recommendations.
Causal Fair Machine Learning via Rank-Preserving Interventional Distributions
Jul 24, 2023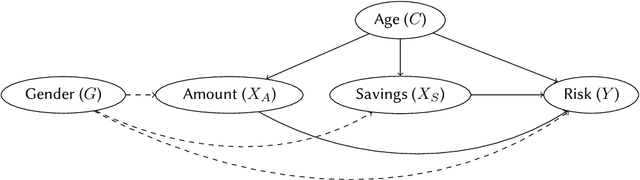

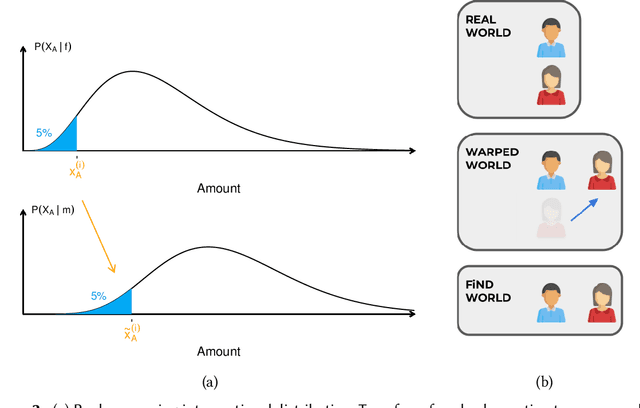
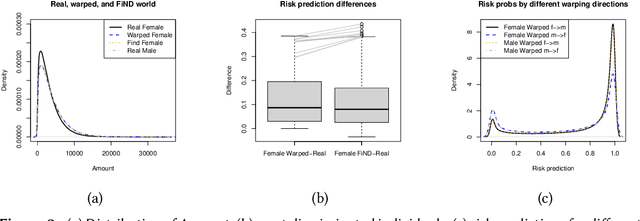
A decision can be defined as fair if equal individuals are treated equally and unequals unequally. Adopting this definition, the task of designing machine learning models that mitigate unfairness in automated decision-making systems must include causal thinking when introducing protected attributes. Following a recent proposal, we define individuals as being normatively equal if they are equal in a fictitious, normatively desired (FiND) world, where the protected attribute has no (direct or indirect) causal effect on the target. We propose rank-preserving interventional distributions to define an estimand of this FiND world and a warping method for estimation. Evaluation criteria for both the method and resulting model are presented and validated through simulations and empirical data. With this, we show that our warping approach effectively identifies the most discriminated individuals and mitigates unfairness.
Interpretable Regional Descriptors: Hyperbox-Based Local Explanations
May 04, 2023



This work introduces interpretable regional descriptors, or IRDs, for local, model-agnostic interpretations. IRDs are hyperboxes that describe how an observation's feature values can be changed without affecting its prediction. They justify a prediction by providing a set of "even if" arguments (semi-factual explanations), and they indicate which features affect a prediction and whether pointwise biases or implausibilities exist. A concrete use case shows that this is valuable for both machine learning modelers and persons subject to a decision. We formalize the search for IRDs as an optimization problem and introduce a unifying framework for computing IRDs that covers desiderata, initialization techniques, and a post-processing method. We show how existing hyperbox methods can be adapted to fit into this unified framework. A benchmark study compares the methods based on several quality measures and identifies two strategies to improve IRDs.
counterfactuals: An R Package for Counterfactual Explanation Methods
Apr 13, 2023Counterfactual explanation methods provide information on how feature values of individual observations must be changed to obtain a desired prediction. Despite the increasing amount of proposed methods in research, only a few implementations exist whose interfaces and requirements vary widely. In this work, we introduce the counterfactuals R package, which provides a modular and unified R6-based interface for counterfactual explanation methods. We implemented three existing counterfactual explanation methods and propose some optional methodological extensions to generalize these methods to different scenarios and to make them more comparable. We explain the structure and workflow of the package using real use cases and show how to integrate additional counterfactual explanation methods into the package. In addition, we compared the implemented methods for a variety of models and datasets with regard to the quality of their counterfactual explanations and their runtime behavior.
Heterogeneous Treatment Effect Estimation for Observational Data using Model-based Forests
Oct 06, 2022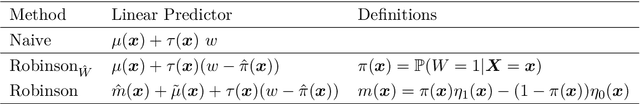
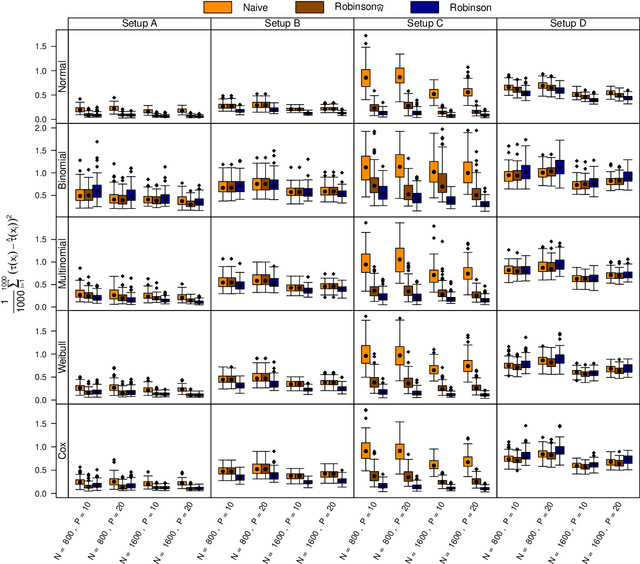
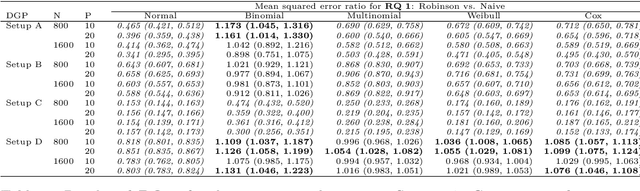
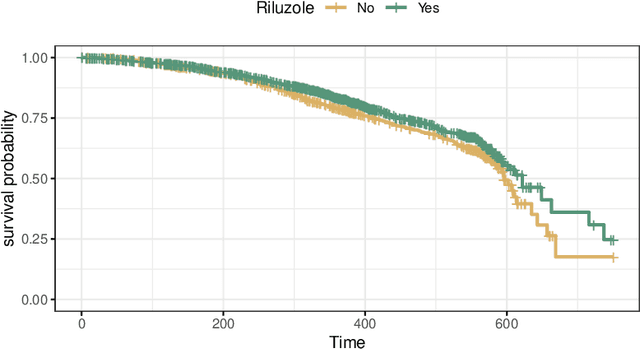
The estimation of heterogeneous treatment effects (HTEs) has attracted considerable interest in many disciplines, most prominently in medicine and economics. Contemporary research has so far primarily focused on continuous and binary responses where HTEs are traditionally estimated by a linear model, which allows the estimation of constant or heterogeneous effects even under certain model misspecifications. More complex models for survival, count, or ordinal outcomes require stricter assumptions to reliably estimate the treatment effect. Most importantly, the noncollapsibility issue necessitates the joint estimation of treatment and prognostic effects. Model-based forests allow simultaneous estimation of covariate-dependent treatment and prognostic effects, but only for randomized trials. In this paper, we propose modifications to model-based forests to address the confounding issue in observational data. In particular, we evaluate an orthogonalization strategy originally proposed by Robinson (1988, Econometrica) in the context of model-based forests targeting HTE estimation in generalized linear models and transformation models. We found that this strategy reduces confounding effects in a simulated study with various outcome distributions. We demonstrate the practical aspects of HTE estimation for survival and ordinal outcomes by an assessment of the potentially heterogeneous effect of Riluzole on the progress of Amyotrophic Lateral Sclerosis.
What Makes Forest-Based Heterogeneous Treatment Effect Estimators Work?
Jun 21, 2022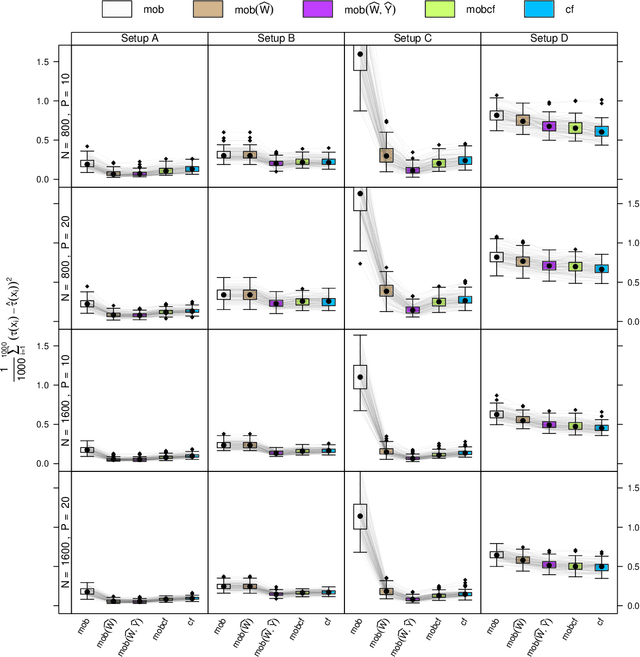
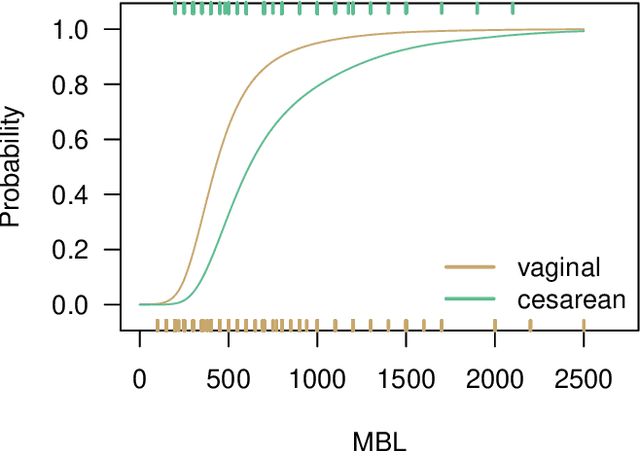
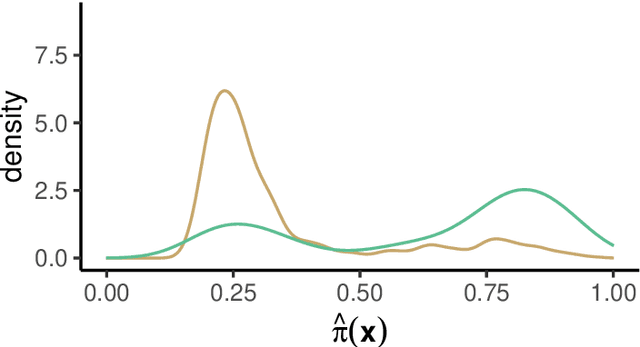
Estimation of heterogeneous treatment effects (HTE) is of prime importance in many disciplines, ranging from personalized medicine to economics among many others. Random forests have been shown to be a flexible and powerful approach to HTE estimation in both randomized trials and observational studies. In particular "causal forests", introduced by Athey, Tibshirani and Wager (2019), along with the R implementation in package grf were rapidly adopted. A related approach, called "model-based forests", that is geared towards randomized trials and simultaneously captures effects of both prognostic and predictive variables, was introduced by Seibold, Zeileis and Hothorn (2018) along with a modular implementation in the R package model4you. Here, we present a unifying view that goes beyond the theoretical motivations and investigates which computational elements make causal forests so successful and how these can be blended with the strengths of model-based forests. To do so, we show that both methods can be understood in terms of the same parameters and model assumptions for an additive model under L2 loss. This theoretical insight allows us to implement several flavors of "model-based causal forests" and dissect their different elements in silico. The original causal forests and model-based forests are compared with the new blended versions in a benchmark study exploring both randomized trials and observational settings. In the randomized setting, both approaches performed akin. If confounding was present in the data generating process, we found local centering of the treatment indicator with the corresponding propensities to be the main driver for good performance. Local centering of the outcome was less important, and might be replaced or enhanced by simultaneous split selection with respect to both prognostic and predictive effects.
Pitfalls to Avoid when Interpreting Machine Learning Models
Jul 08, 2020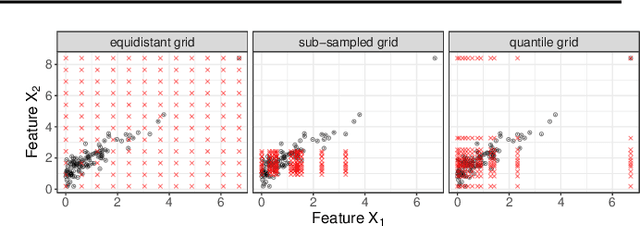
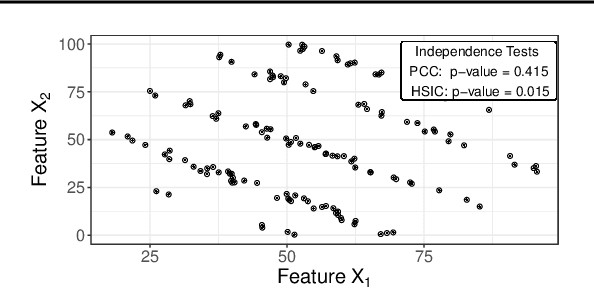
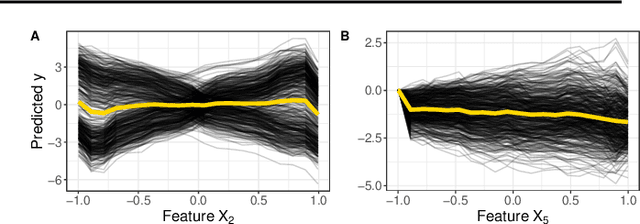
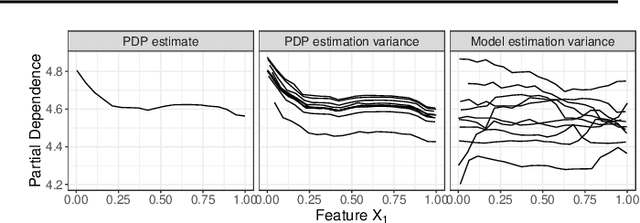
Modern requirements for machine learning (ML) models include both high predictive performance and model interpretability. A growing number of techniques provide model interpretations, but can lead to wrong conclusions if applied incorrectly. We illustrate pitfalls of ML model interpretation such as bad model generalization, dependent features, feature interactions or unjustified causal interpretations. Our paper addresses ML practitioners by raising awareness of pitfalls and pointing out solutions for correct model interpretation, as well as ML researchers by discussing open issues for further research.