 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRANITE: A Generalized Regional Framework for Identifying Agreement in Feature-Based Explanations
Jan 30, 2026Feature-based explanation methods aim to quantify how features influence the model's behavior, either locally or globally, but different methods often disagree, producing conflicting explanations. This disagreement arises primarily from two sources: how feature interactions are handled and how feature dependencies are incorporated. We propose GRANITE, a generalized regional explanation framework that partitions the feature space into regions where interaction and distribution influences are minimized. This approach aligns different explanation methods, yielding more consistent and interpretable explanations. GRANITE unifies existing regional approaches, extends them to feature groups, and introduces a recursive partitioning algorithm to estimate such regions. We demonstrate its effectiveness on real-world datasets, providing a practical tool for consistent and interpretable feature explanations.
Unifying Feature-Based Explanations with Functional ANOVA and Cooperative Game Theory
Dec 22, 2024Feature-based explanations, using perturbations or gradients, are a prevalent tool to understand decisions of black box machine learning models. Yet, differences between these methods still remain mostly unknown, which limits their applicability for practitioners. In this work, we introduce a unified framework for local and global feature-based explanations using two well-established concepts: functional ANOVA (fANOVA) from statistics, and the notion of value and interaction from cooperative game theory. We introduce three fANOVA decompositions that determine the influence of feature distributions, and use game-theoretic measures, such as the Shapley value and interactions, to specify the influence of higher-order interactions. Our framework combines these two dimensions to uncover similarities and differences between a wide range of explanation techniques for features and groups of features. We then empirically showcase the usefulness of our framework on synthetic and real-world datasets.
Effector: A Python package for regional explanations
Apr 03, 2024Global feature effect methods explain a model outputting one plot per feature. The plot shows the average effect of the feature on the output, like the effect of age on the annual income. However, average effects may be misleading when derived from local effects that are heterogeneous, i.e., they significantly deviate from the average. To decrease the heterogeneity, regional effects provide multiple plots per feature, each representing the average effect within a specific subspace. For interpretability, subspaces are defined as hyperrectangles defined by a chain of logical rules, like age's effect on annual income separately for males and females and different levels of professional experience. We introduce Effector, a Python library dedicated to regional feature effects. Effector implements well-established global effect methods, assesses the heterogeneity of each method and, based on that, provides regional effects. Effector automatically detects subspaces where regional effects have reduced heterogeneity. All global and regional effect methods share a common API, facilitating comparisons between them. Moreover, the library's interface is extensible so new methods can be easily added and benchmarked. The library has been thoroughly tested, ships with many tutorials (https://xai-effector.github.io/) and is available under an open-source license at PyPi (https://pypi.org/project/effector/) and Github (https://github.com/givasile/effector).
Explaining Bayesian Optimization by Shapley Values Facilitates Human-AI Collaboration
Mar 08, 2024



Bayesian optimization (BO) with Gaussian processes (GP) has become an indispensable algorithm for black box optimization problems. Not without a dash of irony, BO is often considered a black box itself, lacking ways to provide reasons as to why certain parameters are proposed to be evaluated. This is particularly relevant in human-in-the-loop applications of BO, such as in robotics. We address this issue by proposing ShapleyBO, a framework for interpreting BO's proposals by game-theoretic Shapley values.They quantify each parameter's contribution to BO's acquisition function. Exploiting the linearity of Shapley values, we are further able to identify how strongly each parameter drives BO's exploration and exploitation for additive acquisition functions like the confidence bound. We also show that ShapleyBO can disentangle the contributions to exploration into those that explore aleatoric and epistemic uncertainty. Moreover, our method gives rise to a ShapleyBO-assisted human machine interface (HMI), allowing users to interfere with BO in case proposals do not align with human reasoning. We demonstrate this HMI's benefits for the use case of personalizing wearable robotic devices (assistive back exosuits) by human-in-the-loop BO. Results suggest human-BO teams with access to ShapleyBO can achieve lower regret than teams without.
Leveraging Model-based Trees as Interpretable Surrogate Models for Model Distillation
Oct 04, 2023
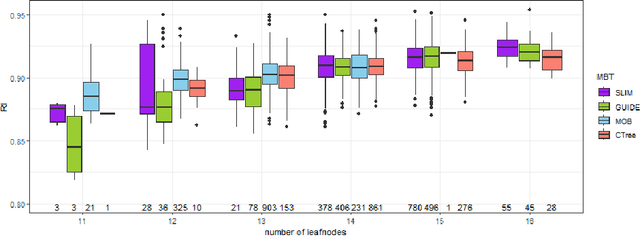

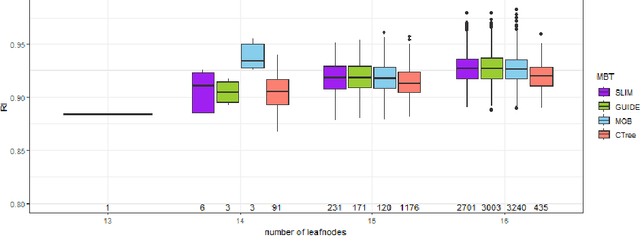
Surrogate models play a crucial role in retrospectively interpreting complex and powerful black box machine learning models via model distillation. This paper focuses on using model-based trees as surrogate models which partition the feature space into interpretable regions via decision rules. Within each region, interpretable models based on additive main effects are used to approximate the behavior of the black box model, striking for an optimal balance between interpretability and performance. Four model-based tree algorithms, namely SLIM, GUIDE, MOB, and CTree, are compared regarding their ability to generate such surrogate models. We investigate fidelity, interpretability, stability, and the algorithms' capability to capture interaction effects through appropriate splits. Based on our comprehensive analyses, we finally provide an overview of user-specific recommendations.
Decomposing Global Feature Effects Based on Feature Interactions
Jun 01, 2023Global feature effect methods, such as partial dependence plots, provide an intelligible visualization of the expected marginal feature effect. However, such global feature effect methods can be misleading, as they do not represent local feature effects of single observations well when feature interactions are present. We formally introduce generalized additive decomposition of global effects (GADGET), which is a new framework based on recursive partitioning to find interpretable regions in the feature space such that the interaction-related heterogeneity of local feature effects is minimized. We provide a mathematical foundation of the framework and show that it is applicable to the most popular methods to visualize marginal feature effects, namely partial dependence, accumulated local effects, and Shapley additive explanations (SHAP) dependence. Furthermore, we introduce a new permutation-based interaction test to detect significant feature interactions that is applicable to any feature effect method that fits into our proposed framework. We empirically evaluate the theoretical characteristics of the proposed methods based on various feature effect methods in different experimental settings. Moreover, we apply our introduced methodology to two real-world examples to showcase their usefulness.
REPID: Regional Effect Plots with implicit Interaction Detection
Feb 15, 2022

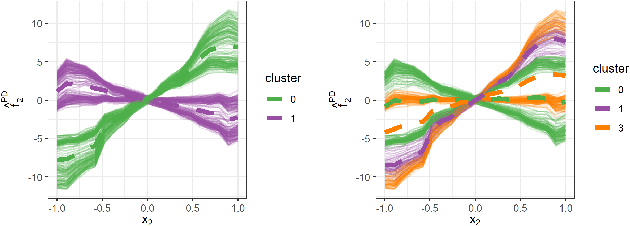

Machine learning models can automatically learn complex relationships, such as non-linear and interaction effects. Interpretable machine learning methods such as partial dependence plots visualize marginal feature effects but may lead to misleading interpretations when feature interactions are present. Hence, employing additional methods that can detect and measure the strength of interactions is paramount to better understand the inner workings of machine learning models. We demonstrate several drawbacks of existing global interaction detection approaches, characterize them theoretically, and evaluate them empirically. Furthermore, we introduce regional effect plots with implicit interaction detection, a novel framework to detect interactions between a feature of interest and other features. The framework also quantifies the strength of interactions and provides interpretable and distinct regions in which feature effects can be interpreted more reliably, as they are less confounded by interactions. We prove the theoretical eligibility of our method and show its applicability on various simulation and real-world examples.
Explaining Hyperparameter Optimization via Partial Dependence Plots
Nov 08, 2021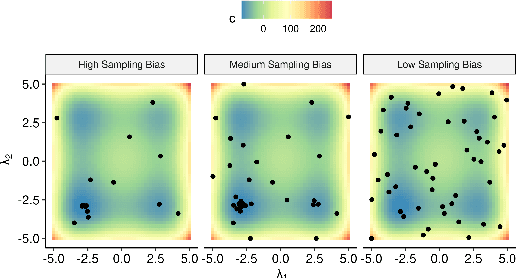
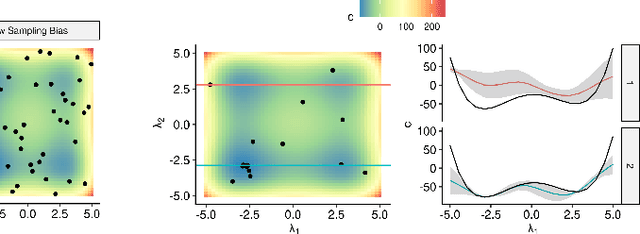
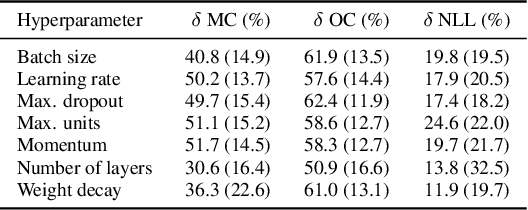
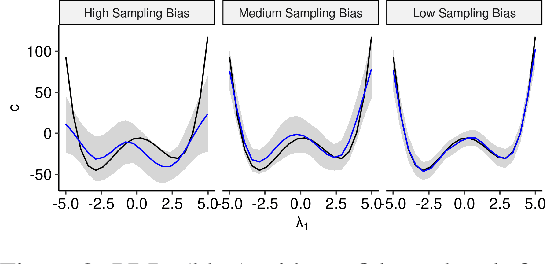
Automated hyperparameter optimization (HPO) can support practitioners to obtain peak performance in machine learning models. However, there is often a lack of valuable insights into the effects of different hyperparameters on the final model performance. This lack of explainability makes it difficult to trust and understand the automated HPO process and its results. We suggest using interpretable machine learning (IML) to gain insights from the experimental data obtained during HPO with Bayesian optimization (BO). BO tends to focus on promising regions with potential high-performance configurations and thus induces a sampling bias. Hence, many IML techniques, such as the partial dependence plot (PDP), carry the risk of generating biased interpretations. By leveraging the posterior uncertainty of the BO surrogate model, we introduce a variant of the PDP with estimated confidence bands. We propose to partition the hyperparameter space to obtain more confident and reliable PDPs in relevant sub-regions. In an experimental study, we provide quantitative evidence for the increased quality of the PDPs within sub-regions.
Grouped Feature Importance and Combined Features Effect Plot
Apr 23, 2021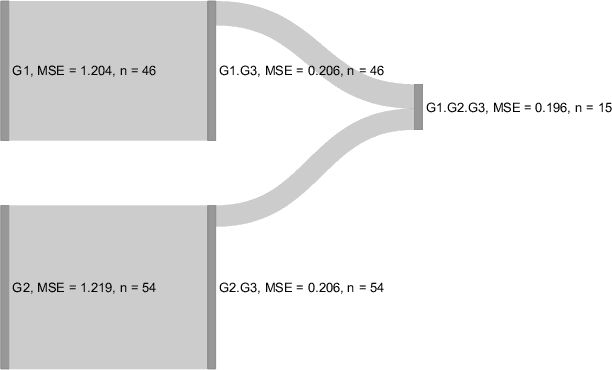

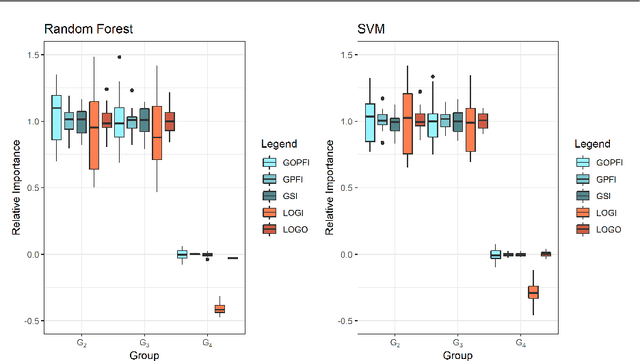

Interpretable machine learning has become a very active area of research due to the rising popularity of machine learning algorithms and their inherently challenging interpretability. Most work in this area has been focused on the interpretation of single features in a model. However, for researchers and practitioners, it is often equally important to quantify the importance or visualize the effect of feature groups. To address this research gap, we provide a comprehensive overview of how existing model-agnostic techniques can be defined for feature groups to assess the grouped feature importance, focusing on permutation-based, refitting, and Shapley-based methods. We also introduce an importance-based sequential procedure that identifies a stable and well-performing combination of features in the grouped feature space. Furthermore, we introduce the combined features effect plot, which is a technique to visualize the effect of a group of features based on a sparse, interpretable linear combination of features. We used simulation studies and a real data example from computational psychology to analyze, compare, and discuss these methods.
Pitfalls to Avoid when Interpreting Machine Learning Models
Jul 08, 2020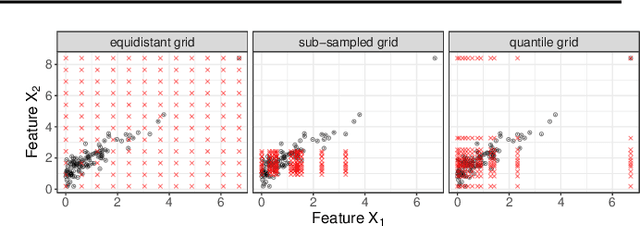
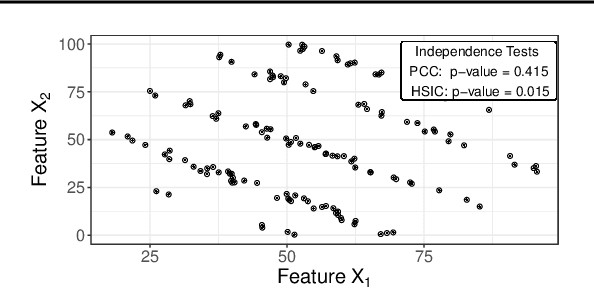
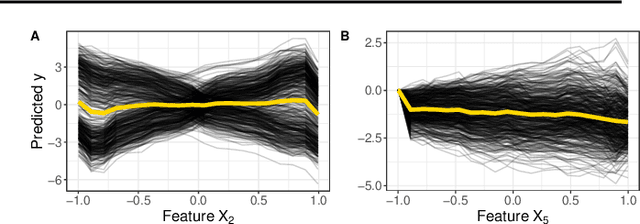
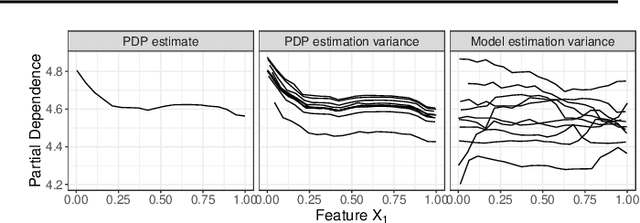
Modern requirements for machine learning (ML) models include both high predictive performance and model interpretability. A growing number of techniques provide model interpretations, but can lead to wrong conclusions if applied incorrectly. We illustrate pitfalls of ML model interpretation such as bad model generalization, dependent features, feature interactions or unjustified causal interpretations. Our paper addresses ML practitioners by raising awareness of pitfalls and pointing out solutions for correct model interpretation, as well as ML researchers by discussing open issues for further research.