 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrouped Feature Importance and Combined Features Effect Plot
Apr 23, 2021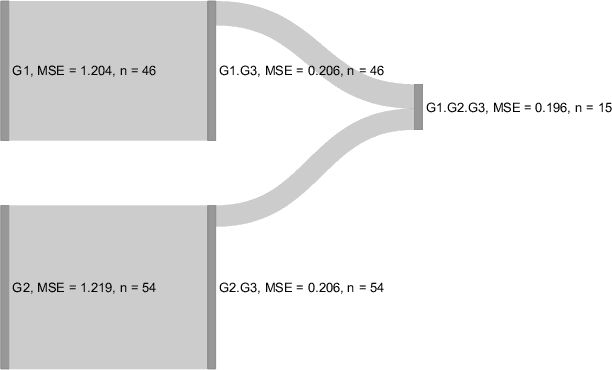

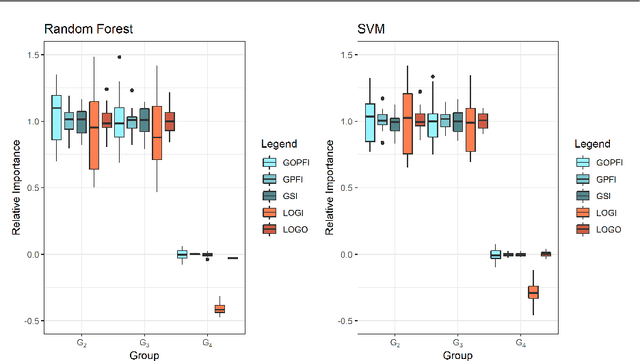

Interpretable machine learning has become a very active area of research due to the rising popularity of machine learning algorithms and their inherently challenging interpretability. Most work in this area has been focused on the interpretation of single features in a model. However, for researchers and practitioners, it is often equally important to quantify the importance or visualize the effect of feature groups. To address this research gap, we provide a comprehensive overview of how existing model-agnostic techniques can be defined for feature groups to assess the grouped feature importance, focusing on permutation-based, refitting, and Shapley-based methods. We also introduce an importance-based sequential procedure that identifies a stable and well-performing combination of features in the grouped feature space. Furthermore, we introduce the combined features effect plot, which is a technique to visualize the effect of a group of features based on a sparse, interpretable linear combination of features. We used simulation studies and a real data example from computational psychology to analyze, compare, and discuss these methods.
Component-Wise Boosting of Targets for Multi-Output Prediction
Apr 08, 2019
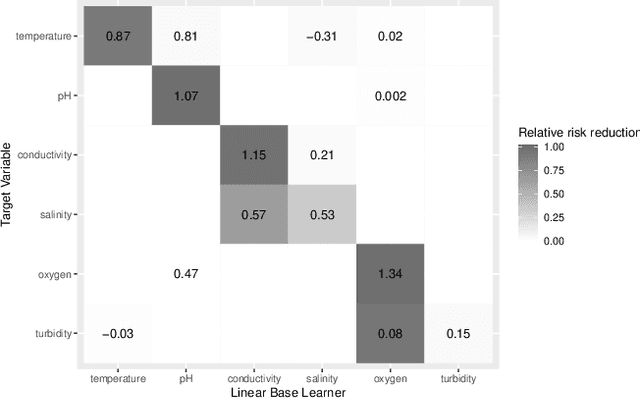

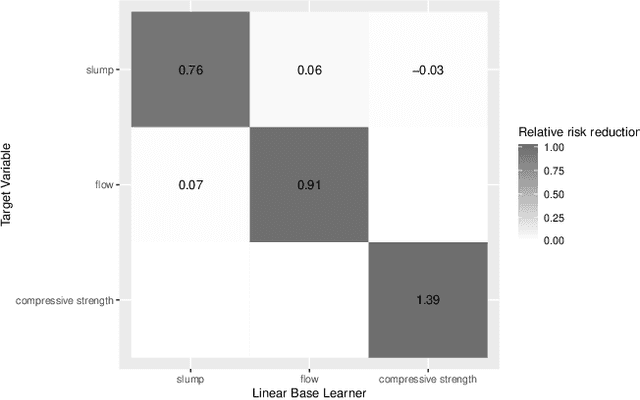
Multi-output prediction deals with the prediction of several targets of possibly diverse types. One way to address this problem is the so called problem transformation method. This method is often used in multi-label learning, but can also be used for multi-output prediction due to its generality and simplicity. In this paper, we introduce an algorithm that uses the problem transformation method for multi-output prediction, while simultaneously learning the dependencies between target variables in a sparse and interpretable manner. In a first step, predictions are obtained for each target individually. Target dependencies are then learned via a component-wise boosting approach. We compare our new method with similar approaches in a benchmark using multi-label, multivariate regression and mixed-type datasets.
Multilabel Classification with R Package mlr
Apr 03, 2017

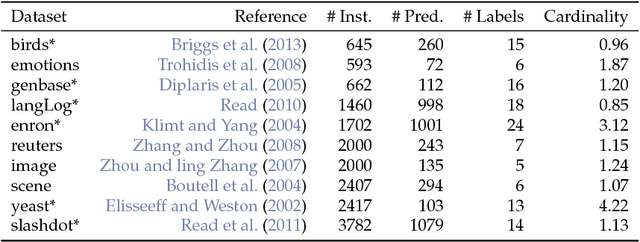

We implemented several multilabel classification algorithms in the machine learning package mlr. The implemented methods are binary relevance, classifier chains, nested stacking, dependent binary relevance and stacking, which can be used with any base learner that is accessible in mlr. Moreover, there is access to the multilabel classification versions of randomForestSRC and rFerns. All these methods can be easily compared by different implemented multilabel performance measures and resampling methods in the standardized mlr framework. In a benchmark experiment with several multilabel datasets, the performance of the different methods is evaluated.
* 18 pages, 2 figures, to be published in R Journal; reference corrected