 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Deep Learning
Jan 12, 2023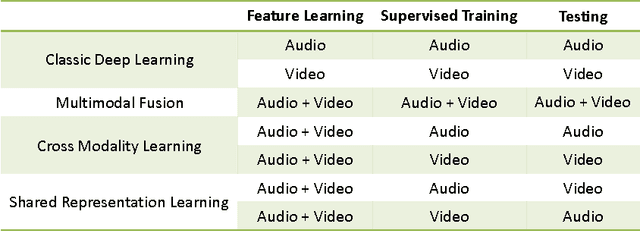
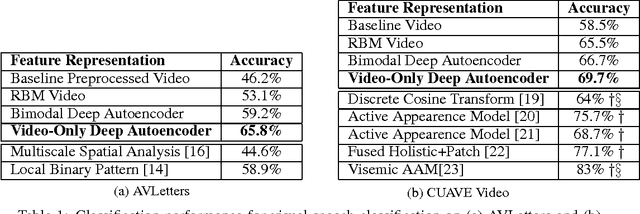
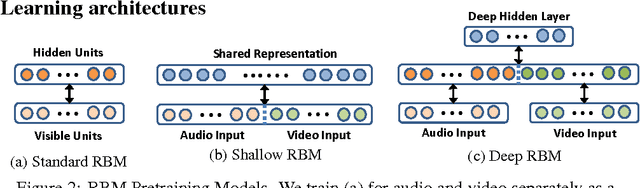
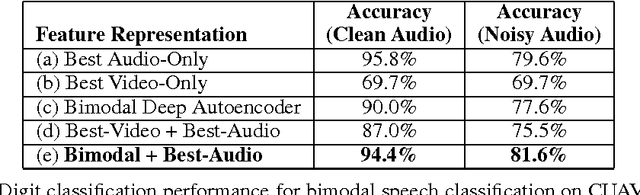
This book is the result of a seminar in which we reviewed multimodal approaches and attempted to create a solid overview of the field, starting with the current state-of-the-art approaches in the two subfields of Deep Learning individually. Further, modeling frameworks are discussed where one modality is transformed into the other, as well as models in which one modality is utilized to enhance representation learning for the other. To conclude the second part, architectures with a focus on handling both modalities simultaneously are introduced. Finally, we also cover other modalities as well as general-purpose multi-modal models, which are able to handle different tasks on different modalities within one unified architecture. One interesting application (Generative Art) eventually caps off this booklet.
Privacy-Preserving and Lossless Distributed Estimation of High-Dimensional Generalized Additive Mixed Models
Oct 14, 2022


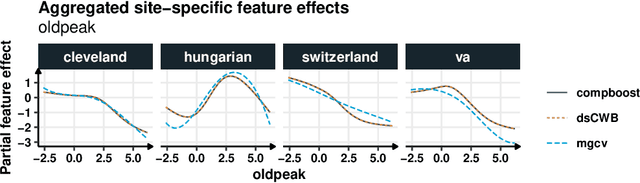
Various privacy-preserving frameworks that respect the individual's privacy in the analysis of data have been developed in recent years. However, available model classes such as simple statistics or generalized linear models lack the flexibility required for a good approximation of the underlying data-generating process in practice. In this paper, we propose an algorithm for a distributed, privacy-preserving, and lossless estimation of generalized additive mixed models (GAMM) using component-wise gradient boosting (CWB). Making use of CWB allows us to reframe the GAMM estimation as a distributed fitting of base learners using the $L_2$-loss. In order to account for the heterogeneity of different data location sites, we propose a distributed version of a row-wise tensor product that allows the computation of site-specific (smooth) effects. Our adaption of CWB preserves all the important properties of the original algorithm, such as an unbiased feature selection and the feasibility to fit models in high-dimensional feature spaces, and yields equivalent model estimates as CWB on pooled data. Next to a derivation of the equivalence of both algorithms, we also showcase the efficacy of our algorithm on a distributed heart disease data set and compare it with state-of-the-art methods.
Accelerated Componentwise Gradient Boosting using Efficient Data Representation and Momentum-based Optimization
Oct 29, 2021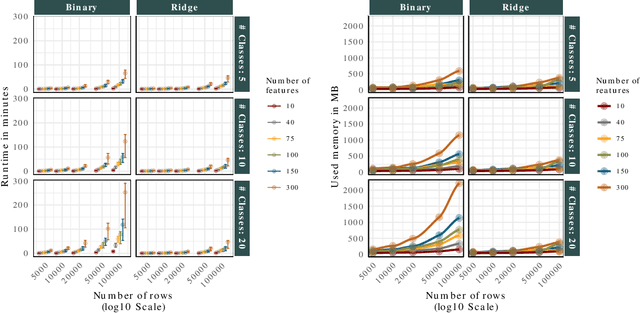
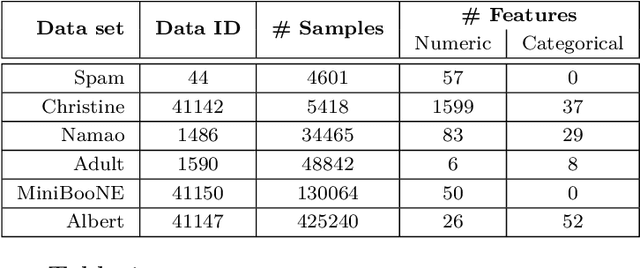
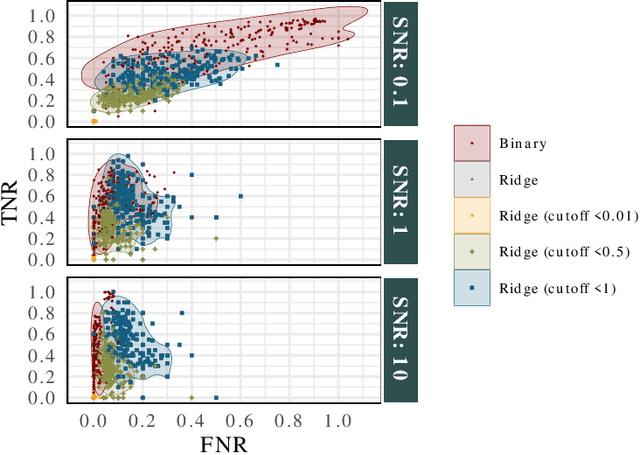
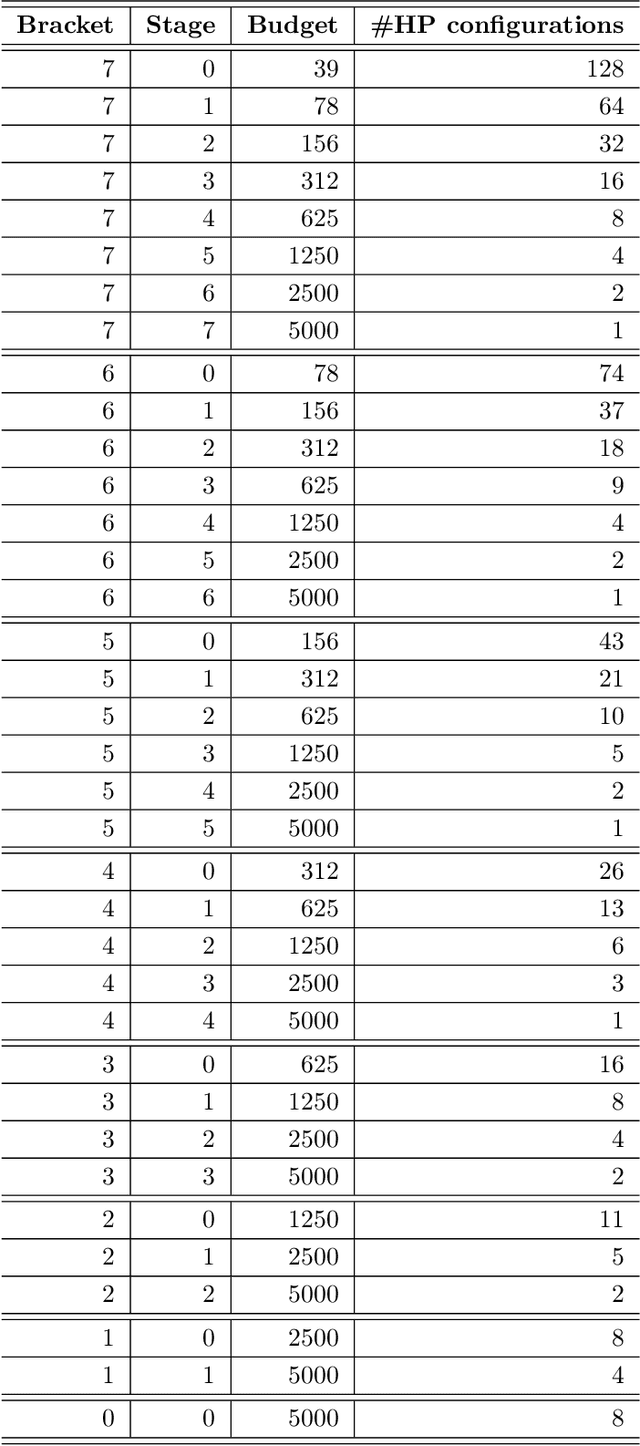
Componentwise boosting (CWB), also known as model-based boosting, is a variant of gradient boosting that builds on additive models as base learners to ensure interpretability. CWB is thus often used in research areas where models are employed as tools to explain relationships in data. One downside of CWB is its computational complexity in terms of memory and runtime. In this paper, we propose two techniques to overcome these issues without losing the properties of CWB: feature discretization of numerical features and incorporating Nesterov momentum into functional gradient descent. As the latter can be prone to early overfitting, we also propose a hybrid approach that prevents a possibly diverging gradient descent routine while ensuring faster convergence. We perform extensive benchmarks on multiple simulated and real-world data sets to demonstrate the improvements in runtime and memory consumption while maintaining state-of-the-art estimation and prediction performance.
Automatic Componentwise Boosting: An Interpretable AutoML System
Sep 12, 2021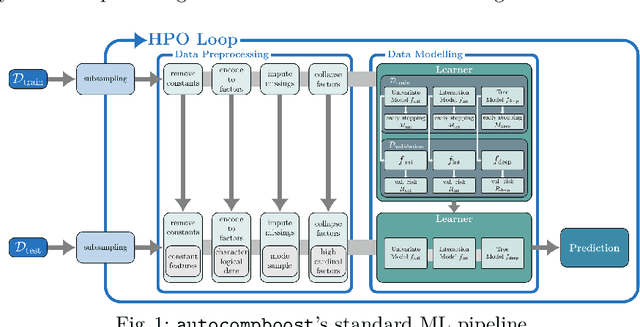
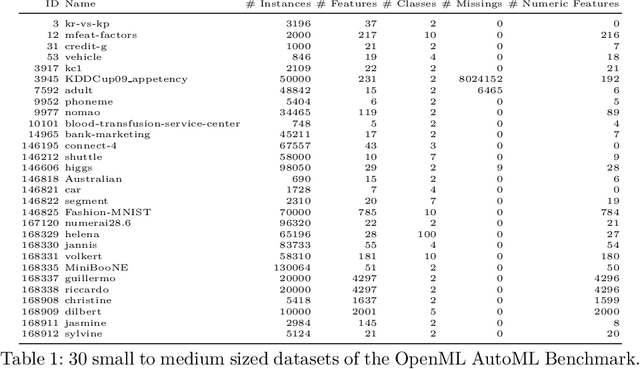


In practice, machine learning (ML) workflows require various different steps, from data preprocessing, missing value imputation, model selection, to model tuning as well as model evaluation. Many of these steps rely on human ML experts. AutoML - the field of automating these ML pipelines - tries to help practitioners to apply ML off-the-shelf without any expert knowledge. Most modern AutoML systems like auto-sklearn, H20-AutoML or TPOT aim for high predictive performance, thereby generating ensembles that consist almost exclusively of black-box models. This, in turn, makes the interpretation for the layperson more intricate and adds another layer of opacity for users. We propose an AutoML system that constructs an interpretable additive model that can be fitted using a highly scalable componentwise boosting algorithm. Our system provides tools for easy model interpretation such as visualizing partial effects and pairwise interactions, allows for a straightforward calculation of feature importance, and gives insights into the required model complexity to fit the given task. We introduce the general framework and outline its implementation autocompboost. To demonstrate the frameworks efficacy, we compare autocompboost to other existing systems based on the OpenML AutoML-Benchmark. Despite its restriction to an interpretable model space, our system is competitive in terms of predictive performance on most data sets while being more user-friendly and transparent.
Component-Wise Boosting of Targets for Multi-Output Prediction
Apr 08, 2019
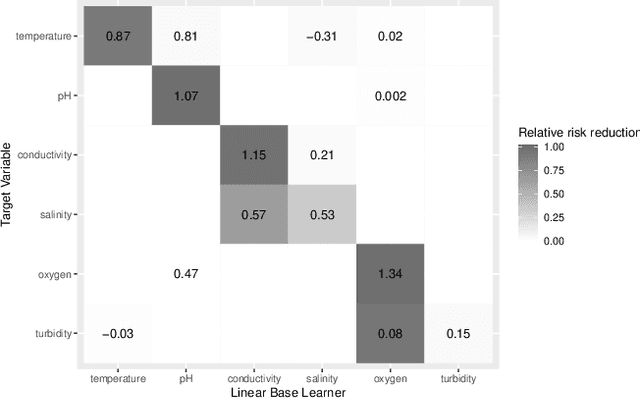

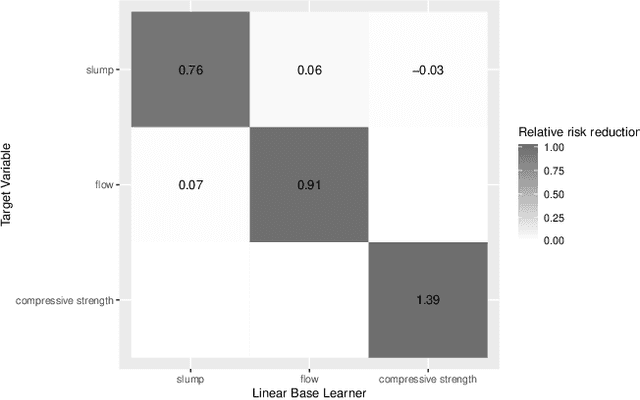
Multi-output prediction deals with the prediction of several targets of possibly diverse types. One way to address this problem is the so called problem transformation method. This method is often used in multi-label learning, but can also be used for multi-output prediction due to its generality and simplicity. In this paper, we introduce an algorithm that uses the problem transformation method for multi-output prediction, while simultaneously learning the dependencies between target variables in a sparse and interpretable manner. In a first step, predictions are obtained for each target individually. Target dependencies are then learned via a component-wise boosting approach. We compare our new method with similar approaches in a benchmark using multi-label, multivariate regression and mixed-type datasets.