 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Car Model Identification System for Streamlining the Automobile Sales Process
Oct 23, 2023



This project presents an automated solution for the efficient identification of car models and makes from images, aimed at streamlining the vehicle listing process on online car-selling platforms. Through a thorough exploration encompassing various efficient network architectures including Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and hybrid models, we achieved a notable accuracy of 81.97% employing the EfficientNet (V2 b2) architecture. To refine performance, a combination of strategies, including data augmentation, fine-tuning pretrained models, and extensive hyperparameter tuning, were applied. The trained model offers the potential for automating information extraction, promising enhanced user experiences across car-selling websites.
Multimodal Deep Learning
Jan 12, 2023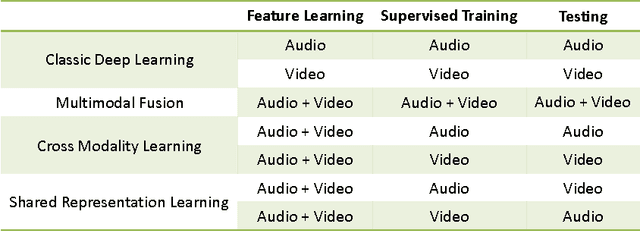
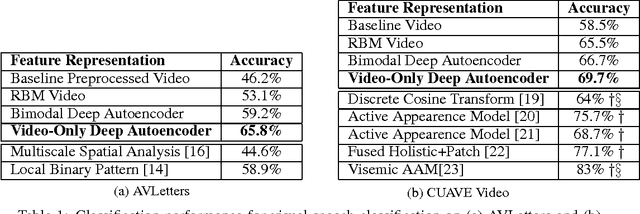
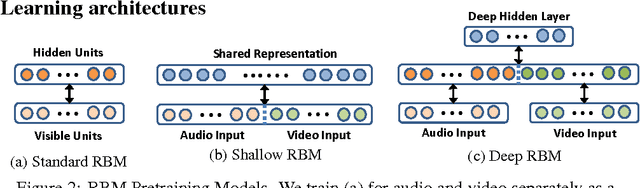
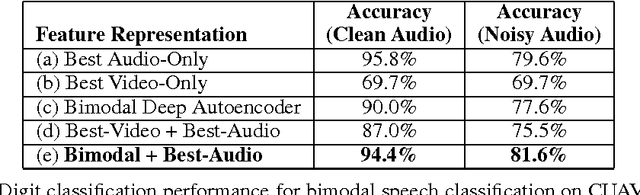
This book is the result of a seminar in which we reviewed multimodal approaches and attempted to create a solid overview of the field, starting with the current state-of-the-art approaches in the two subfields of Deep Learning individually. Further, modeling frameworks are discussed where one modality is transformed into the other, as well as models in which one modality is utilized to enhance representation learning for the other. To conclude the second part, architectures with a focus on handling both modalities simultaneously are introduced. Finally, we also cover other modalities as well as general-purpose multi-modal models, which are able to handle different tasks on different modalities within one unified architecture. One interesting application (Generative Art) eventually caps off this booklet.