 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying multilingual party manifestos: Domain transfer across country, time, and genre
Jul 31, 2023



Annotating costs of large corpora are still one of the main bottlenecks in empirical social science research. On the one hand, making use of the capabilities of domain transfer allows re-using annotated data sets and trained models. On the other hand, it is not clear how well domain transfer works and how reliable the results are for transfer across different dimensions. We explore the potential of domain transfer across geographical locations, languages, time, and genre in a large-scale database of political manifestos. First, we show the strong within-domain classification performance of fine-tuned transformer models. Second, we vary the genre of the test set across the aforementioned dimensions to test for the fine-tuned models' robustness and transferability. For switching genres, we use an external corpus of transcribed speeches from New Zealand politicians while for the other three dimensions, custom splits of the Manifesto database are used. While BERT achieves the best scores in the initial experiments across modalities, DistilBERT proves to be competitive at a lower computational expense and is thus used for further experiments across time and country. The results of the additional analysis show that (Distil)BERT can be applied to future data with similar performance. Moreover, we observe (partly) notable differences between the political manifestos of different countries of origin, even if these countries share a language or a cultural background.
Multimodal Deep Learning
Jan 12, 2023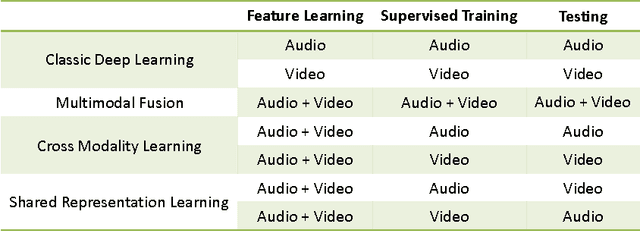
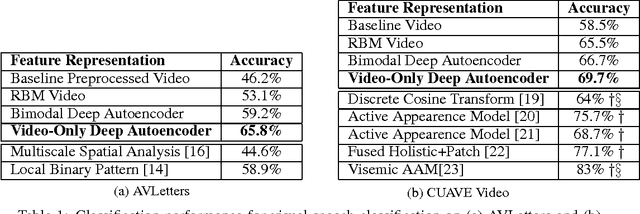
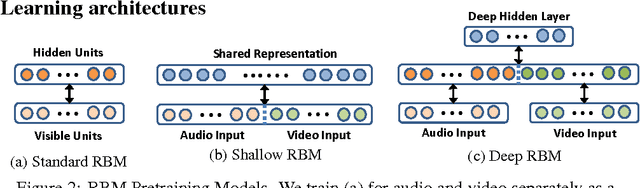
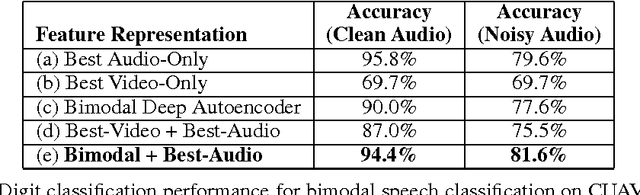
This book is the result of a seminar in which we reviewed multimodal approaches and attempted to create a solid overview of the field, starting with the current state-of-the-art approaches in the two subfields of Deep Learning individually. Further, modeling frameworks are discussed where one modality is transformed into the other, as well as models in which one modality is utilized to enhance representation learning for the other. To conclude the second part, architectures with a focus on handling both modalities simultaneously are introduced. Finally, we also cover other modalities as well as general-purpose multi-modal models, which are able to handle different tasks on different modalities within one unified architecture. One interesting application (Generative Art) eventually caps off this booklet.