 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollecting Prosody in the Wild: A Content-Controlled, Privacy-First Smartphone Protocol and Empirical Evaluation
Mar 17, 2026Collecting everyday speech data for prosodic analysis is challenging due to the confounding of prosody and semantics, privacy constraints, and participant compliance. We introduce and empirically evaluate a content-controlled, privacy-first smartphone protocol that uses scripted read-aloud sentences to standardize lexical content (including prompt valence) while capturing natural variation in prosodic delivery. The protocol performs on-device prosodic feature extraction, deletes raw audio immediately, and transmits only derived features for analysis. We deployed the protocol in a large study (N = 560; 9,877 recordings), evaluated compliance and data quality, and conducted diagnostic prediction tasks on the extracted features, predicting speaker sex and concurrently reported momentary affective states (valence, arousal). We discuss implications and directions for advancing and deploying the protocol.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Against Algorithmic Exploitation of Human Vulnerabilities
Jan 12, 2023
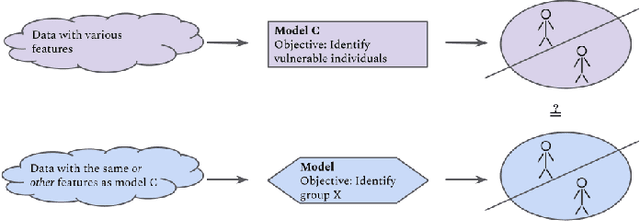
Decisions such as which movie to watch next, which song to listen to, or which product to buy online, are increasingly influenced by recommender systems and user models that incorporate information on users' past behaviours, preferences, and digitally created content. Machine learning models that enable recommendations and that are trained on user data may unintentionally leverage information on human characteristics that are considered vulnerabilities, such as depression, young age, or gambling addiction. The use of algorithmic decisions based on latent vulnerable state representations could be considered manipulative and could have a deteriorating impact on the condition of vulnerable individuals. In this paper, we are concerned with the problem of machine learning models inadvertently modelling vulnerabilities, and want to raise awareness for this issue to be considered in legislation and AI ethics. Hence, we define and describe common vulnerabilities, and illustrate cases where they are likely to play a role in algorithmic decision-making. We propose a set of requirements for methods to detect the potential for vulnerability modelling, detect whether vulnerable groups are treated differently by a model, and detect whether a model has created an internal representation of vulnerability. We conclude that explainable artificial intelligence methods may be necessary for detecting vulnerability exploitation by machine learning-based recommendation systems.
Factorized Structured Regression for Large-Scale Varying Coefficient Models
May 25, 2022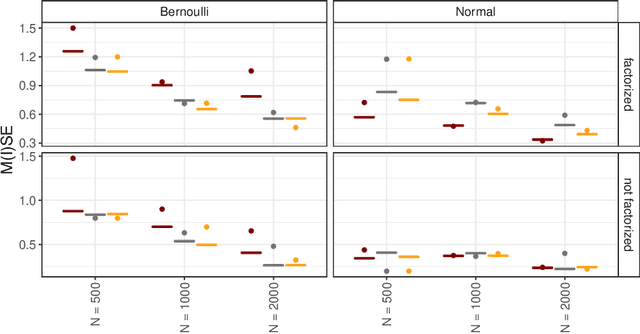
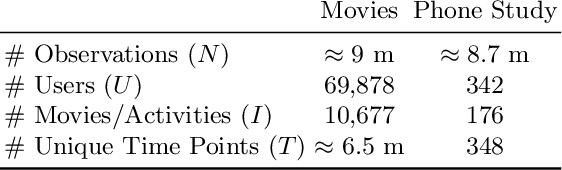
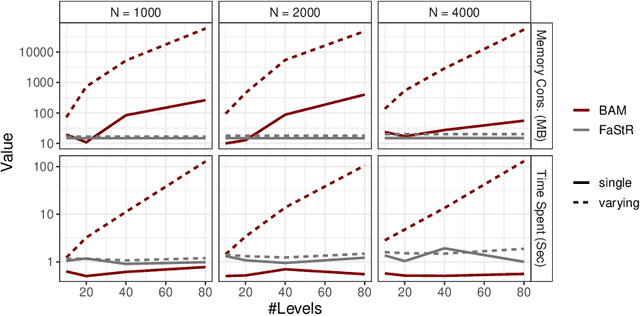
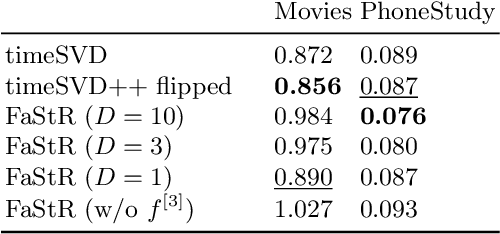
Recommender Systems (RS) pervade many aspects of our everyday digital life. Proposed to work at scale, state-of-the-art RS allow the modeling of thousands of interactions and facilitate highly individualized recommendations. Conceptually, many RS can be viewed as instances of statistical regression models that incorporate complex feature effects and potentially non-Gaussian outcomes. Such structured regression models, including time-aware varying coefficients models, are, however, limited in their applicability to categorical effects and inclusion of a large number of interactions. Here, we propose Factorized Structured Regression (FaStR) for scalable varying coefficient models. FaStR overcomes limitations of general regression models for large-scale data by combining structured additive regression and factorization approaches in a neural network-based model implementation. This fusion provides a scalable framework for the estimation of statistical models in previously infeasible data settings. Empirical results confirm that the estimation of varying coefficients of our approach is on par with state-of-the-art regression techniques, while scaling notably better and also being competitive with other time-aware RS in terms of prediction performance. We illustrate FaStR's performance and interpretability on a large-scale behavioral study with smartphone user data.
Digital Voodoo Dolls
May 07, 2021
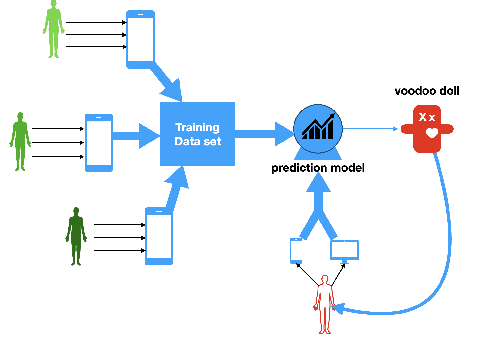
An institution, be it a body of government, commercial enterprise, or a service, cannot interact directly with a person. Instead, a model is created to represent us. We argue the existence of a new high-fidelity type of person model which we call a digital voodoo doll. We conceptualize it and compare its features with existing models of persons. Digital voodoo dolls are distinguished by existing completely beyond the influence and control of the person they represent. We discuss the ethical issues that such a lack of accountability creates and argue how these concerns can be mitigated.
Grouped Feature Importance and Combined Features Effect Plot
Apr 23, 2021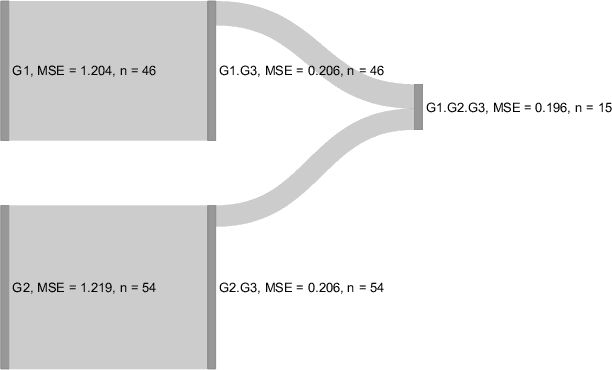

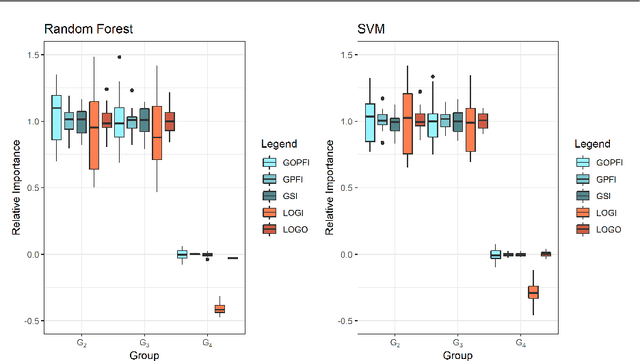

Interpretable machine learning has become a very active area of research due to the rising popularity of machine learning algorithms and their inherently challenging interpretability. Most work in this area has been focused on the interpretation of single features in a model. However, for researchers and practitioners, it is often equally important to quantify the importance or visualize the effect of feature groups. To address this research gap, we provide a comprehensive overview of how existing model-agnostic techniques can be defined for feature groups to assess the grouped feature importance, focusing on permutation-based, refitting, and Shapley-based methods. We also introduce an importance-based sequential procedure that identifies a stable and well-performing combination of features in the grouped feature space. Furthermore, we introduce the combined features effect plot, which is a technique to visualize the effect of a group of features based on a sparse, interpretable linear combination of features. We used simulation studies and a real data example from computational psychology to analyze, compare, and discuss these methods.
Component-Wise Boosting of Targets for Multi-Output Prediction
Apr 08, 2019
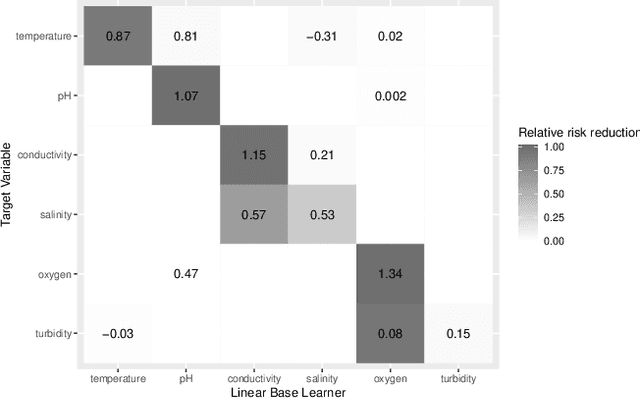

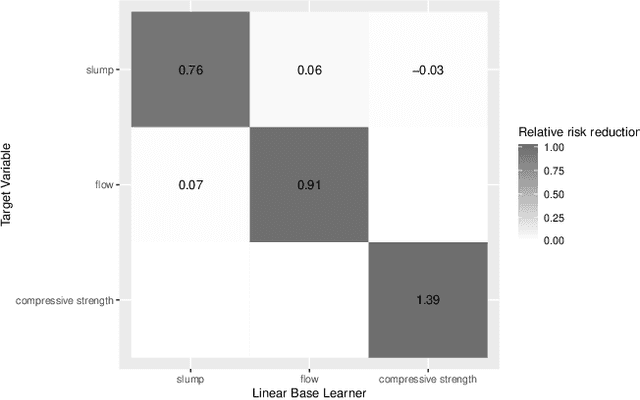
Multi-output prediction deals with the prediction of several targets of possibly diverse types. One way to address this problem is the so called problem transformation method. This method is often used in multi-label learning, but can also be used for multi-output prediction due to its generality and simplicity. In this paper, we introduce an algorithm that uses the problem transformation method for multi-output prediction, while simultaneously learning the dependencies between target variables in a sparse and interpretable manner. In a first step, predictions are obtained for each target individually. Target dependencies are then learned via a component-wise boosting approach. We compare our new method with similar approaches in a benchmark using multi-label, multivariate regression and mixed-type datasets.
Multilabel Classification with R Package mlr
Apr 03, 2017

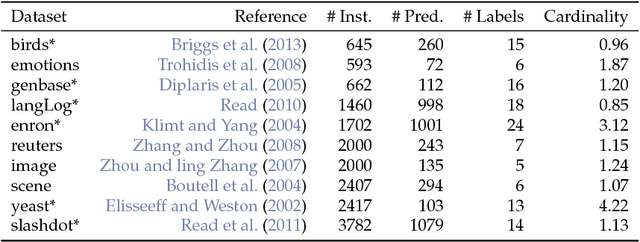

We implemented several multilabel classification algorithms in the machine learning package mlr. The implemented methods are binary relevance, classifier chains, nested stacking, dependent binary relevance and stacking, which can be used with any base learner that is accessible in mlr. Moreover, there is access to the multilabel classification versions of randomForestSRC and rFerns. All these methods can be easily compared by different implemented multilabel performance measures and resampling methods in the standardized mlr framework. In a benchmark experiment with several multilabel datasets, the performance of the different methods is evaluated.
* 18 pages, 2 figures, to be published in R Journal; reference corrected