 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Based Learning for Healthcare: A Demonstration of Interpretable AI
Jan 05, 2026Despite recent advances in machine learning and explainable AI, a gap remains in personalized preventive healthcare: predictions, interventions, and recommendations should be both understandable and verifiable for all stakeholders in the healthcare sector. We present a demonstration of how prototype-based learning can address these needs. Our proposed framework, ProtoPal, features both front- and back-end modes; it achieves superior quantitative performance while also providing an intuitive presentation of interventions and their simulated outcomes.
A Robust Prototype-Based Network with Interpretable RBF Classifier Foundations
Dec 20, 2024Prototype-based classification learning methods are known to be inherently interpretable. However, this paradigm suffers from major limitations compared to deep models, such as lower performance. This led to the development of the so-called deep Prototype-Based Networks (PBNs), also known as prototypical parts models. In this work, we analyze these models with respect to different properties, including interpretability. In particular, we focus on the Classification-by-Components (CBC) approach, which uses a probabilistic model to ensure interpretability and can be used as a shallow or deep architecture. We show that this model has several shortcomings, like creating contradicting explanations. Based on these findings, we propose an extension of CBC that solves these issues. Moreover, we prove that this extension has robustness guarantees and derive a loss that optimizes robustness. Additionally, our analysis shows that most (deep) PBNs are related to (deep) RBF classifiers, which implies that our robustness guarantees generalize to shallow RBF classifiers. The empirical evaluation demonstrates that our deep PBN yields state-of-the-art classification accuracy on different benchmarks while resolving the interpretability shortcomings of other approaches. Further, our shallow PBN variant outperforms other shallow PBNs while being inherently interpretable and exhibiting provable robustness guarantees.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Robust Text Classification: Analyzing Prototype-Based Networks
Nov 11, 2023Downstream applications often require text classification models to be accurate, robust, and interpretable. While the accuracy of the stateof-the-art language models approximates human performance, they are not designed to be interpretable and often exhibit a drop in performance on noisy data. The family of PrototypeBased Networks (PBNs) that classify examples based on their similarity to prototypical examples of a class (prototypes) is natively interpretable and shown to be robust to noise, which enabled its wide usage for computer vision tasks. In this paper, we study whether the robustness properties of PBNs transfer to text classification tasks. We design a modular and comprehensive framework for studying PBNs, which includes different backbone architectures, backbone sizes, and objective functions. Our evaluation protocol assesses the robustness of models against character-, word-, and sentence-level perturbations. Our experiments on three benchmarks show that the robustness of PBNs transfers to NLP classification tasks facing realistic perturbations. Moreover, the robustness of PBNs is supported mostly by the objective function that keeps prototypes interpretable, while the robustness superiority of PBNs over vanilla models becomes more salient as datasets get more complex.
A Human-Centric Assessment Framework for AI
May 25, 2022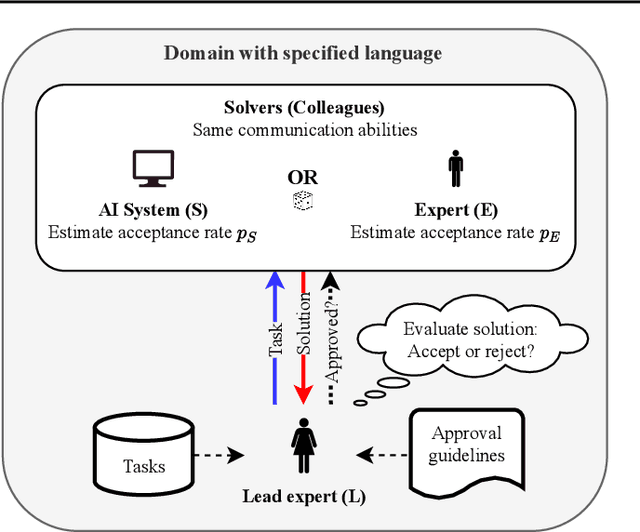
With the rise of AI systems in real-world applications comes the need for reliable and trustworthy AI. An important aspect for this are explainable AI systems. However, there is no agreed standard on how explainable AI systems should be assessed. Inspired by the Turing test, we introduce a human-centric assessment framework where a leading domain expert accepts or rejects the solutions of an AI system and another domain expert. By comparing the acceptance rates of provided solutions, we can assess how the AI system performs in comparison to the domain expert, and in turn whether or not the AI system's explanations (if provided) are human understandable. This setup -- comparable to the Turing test -- can serve as framework for a wide range of human-centric AI system assessments. We demonstrate this by presenting two instantiations: (1) an assessment that measures the classification accuracy of a system with the option to incorporate label uncertainties; (2) an assessment where the usefulness of provided explanations is determined in a human-centric manner.
Combining Visual Saliency Methods and Sparse Keypoint Annotations to Providently Detect Vehicles at Night
Apr 25, 2022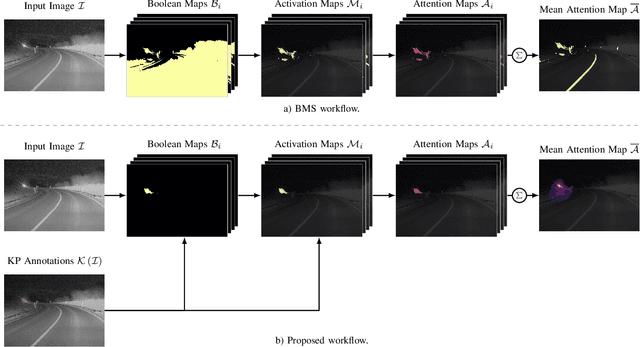



Provident detection of other road users at night has the potential for increasing road safety. For this purpose, humans intuitively use visual cues, such as light cones and light reflections emitted by other road users to be able to react to oncoming traffic at an early stage. This behavior can be imitated by computer vision methods by predicting the appearance of vehicles based on emitted light reflections caused by the vehicle's headlights. Since current object detection algorithms are mainly based on detecting directly visible objects annotated via bounding boxes, the detection and annotation of light reflections without sharp boundaries is challenging. For this reason, the extensive open-source dataset PVDN (Provident Vehicle Detection at Night) was published, which includes traffic scenarios at night with light reflections annotated via keypoints. In this paper, we explore the potential of saliency-based approaches to create different object representations based on the visual saliency and sparse keypoint annotations of the PVDN dataset. For that, we extend the general idea of Boolean map saliency towards a context-aware approach by taking into consideration sparse keypoint annotations by humans. We show that this approach allows for an automated derivation of different object representations, such as binary maps or bounding boxes so that detection models can be trained on different annotation variants and the problem of providently detecting vehicles at night can be tackled from different perspectives. With that, we provide further powerful tools and methods to study the problem of detecting vehicles at night before they are actually visible.
Provident Vehicle Detection at Night for Advanced Driver Assistance Systems
Aug 11, 2021

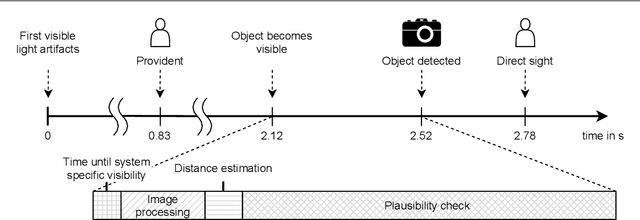

In recent years, computer vision algorithms have become more and more powerful, which enabled technologies such as autonomous driving to evolve with rapid pace. However, current algorithms mainly share one limitation: They rely on directly visible objects. This is a major drawback compared to human behavior, where indirect visual cues caused by the actual object (e.g., shadows) are already used intuitively to retrieve information or anticipate occurring objects. While driving at night, this performance deficit becomes even more obvious: Humans already process the light artifacts caused by oncoming vehicles to assume their future appearance, whereas current object detection systems rely on the oncoming vehicle's direct visibility. Based on previous work in this subject, we present with this paper a complete system capable of solving the task to providently detect oncoming vehicles at nighttime based on their caused light artifacts. For that, we outline the full algorithm architecture ranging from the detection of light artifacts in the image space, localizing the objects in the three-dimensional space, and verifying the objects over time. To demonstrate the applicability, we deploy the system in a test vehicle and use the information of providently detected vehicles to control the glare-free high beam system proactively. Using this experimental setting, we quantify the time benefit that the provident vehicle detection system provides compared to an in-production computer vision system. Additionally, the glare-free high beam use case provides a real-time and real-world visualization interface of the detection results. With this contribution, we want to put awareness on the unconventional sensing task of provident object detection and further close the performance gap between human behavior and computer vision algorithms in order to bring autonomous and automated driving a step forward.
A Dataset for Provident Vehicle Detection at Night
May 27, 2021

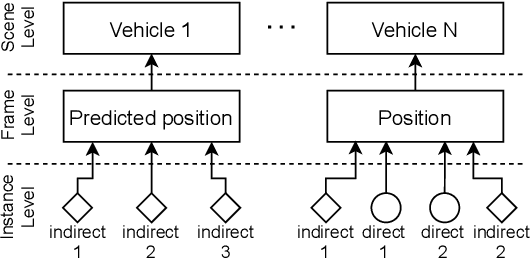

In current object detection, algorithms require the object to be directly visible in order to be detected. As humans, however, we intuitively use visual cues caused by the respective object to already make assumptions about its appearance. In the context of driving, such cues can be shadows during the day and often light reflections at night. In this paper, we study the problem of how to map this intuitive human behavior to computer vision algorithms to detect oncoming vehicles at night just from the light reflections they cause by their headlights. For that, we present an extensive open-source dataset containing 59746 annotated grayscale images out of 346 different scenes in a rural environment at night. In these images, all oncoming vehicles, their corresponding light objects (e.g., headlamps), and their respective light reflections (e.g., light reflections on guardrails) are labeled. In this context, we discuss the characteristics of the dataset and the challenges in objectively describing visual cues such as light reflections. We provide different metrics for different ways to approach the task and report the results we achieved using state-of-the-art and custom object detection models as a first benchmark. With that, we want to bring attention to a new and so far neglected field in computer vision research, encourage more researchers to tackle the problem, and thereby further close the gap between human performance and computer vision systems.
Provident Vehicle Detection at Night: The PVDN Dataset
Jan 23, 2021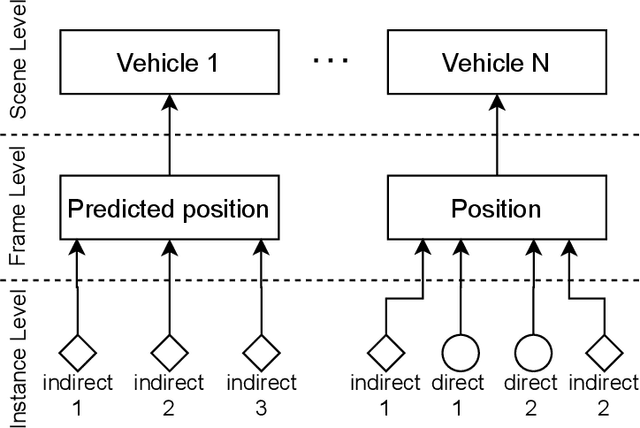
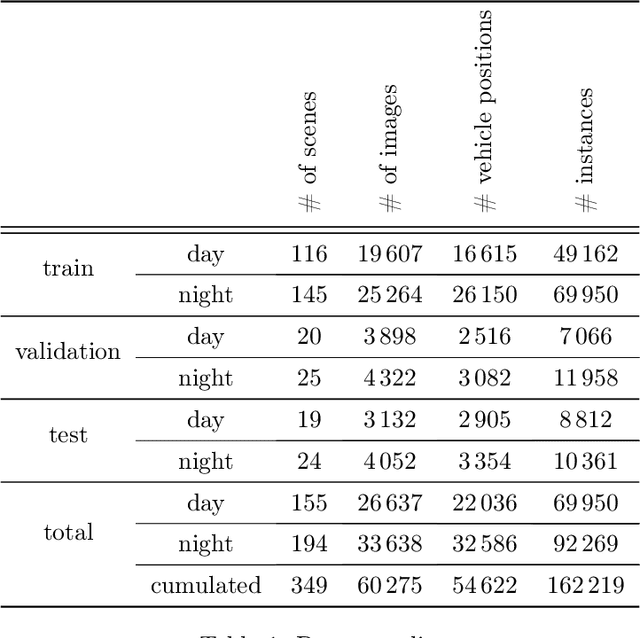

For advanced driver assistance systems, it is crucial to have information about oncoming vehicles as early as possible. At night, this task is especially difficult due to poor lighting conditions. For that, during nighttime, every vehicle uses headlamps to improve sight and therefore ensure safe driving. As humans, we intuitively assume oncoming vehicles before the vehicles are actually physically visible by detecting light reflections caused by their headlamps. In this paper, we present a novel dataset containing 59746 annotated grayscale images out of 346 different scenes in a rural environment at night. In these images, all oncoming vehicles, their corresponding light objects (e.g., headlamps), and their respective light reflections (e.g., light reflections on guardrails) are labeled. This is accompanied by an in-depth analysis of the dataset characteristics. With that, we are providing the first open-source dataset with comprehensive ground truth data to enable research into new methods of detecting oncoming vehicles based on the light reflections they cause, long before they are directly visible. We consider this as an essential step to further close the performance gap between current advanced driver assistance systems and human behavior.
Radar Artifact Labeling Framework (RALF): Method for Plausible Radar Detections in Datasets
Dec 03, 2020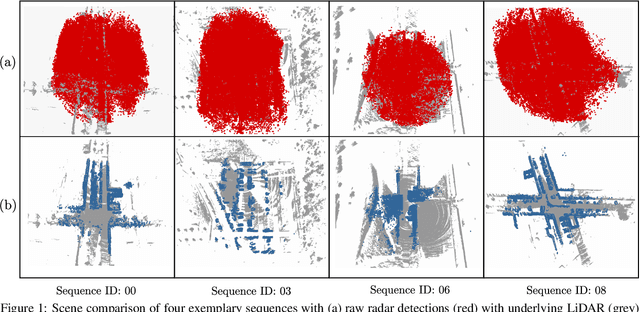
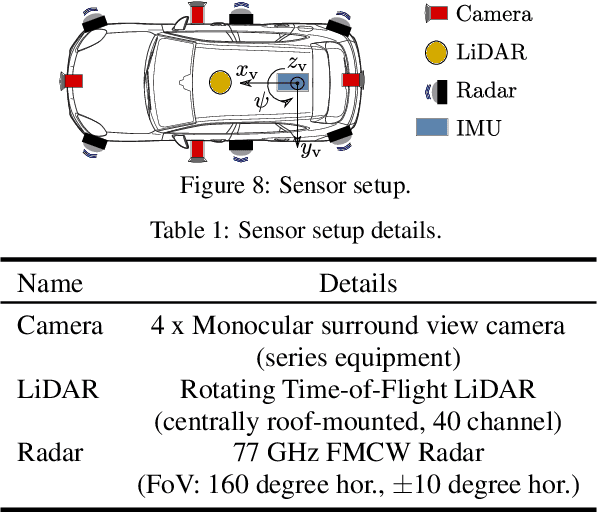
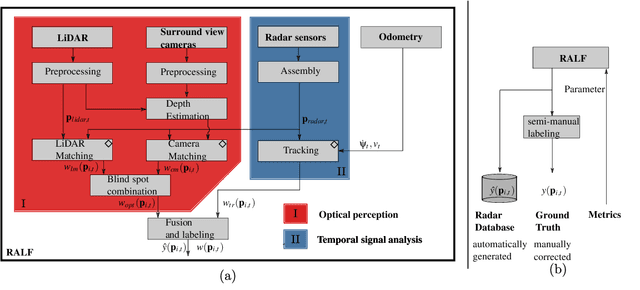
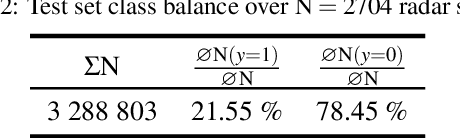
Research on localization and perception for Autonomous Driving is mainly focused on camera and LiDAR datasets, rarely on radar data. Manually labeling sparse radar point clouds is challenging. For a dataset generation, we propose the cross sensor Radar Artifact Labeling Framework (RALF). Automatically generated labels for automotive radar data help to cure radar shortcomings like artifacts for the application of artificial intelligence. RALF provides plausibility labels for radar raw detections, distinguishing between artifacts and targets. The optical evaluation backbone consists of a generalized monocular depth image estimation of surround view cameras plus LiDAR scans. Modern car sensor sets of cameras and LiDAR allow to calibrate image-based relative depth information in overlapping sensing areas. K-Nearest Neighbors matching relates the optical perception point cloud with raw radar detections. In parallel, a temporal tracking evaluation part considers the radar detections' transient behavior. Based on the distance between matches, respecting both sensor and model uncertainties, we propose a plausibility rating of every radar detection. We validate the results by evaluating error metrics on semi-manually labeled ground truth dataset of $3.28\cdot10^6$ points. Besides generating plausible radar detections, the framework enables further labeled low-level radar signal datasets for applications of perception and Autonomous Driving learning tasks.