 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Based Learning for Healthcare: A Demonstration of Interpretable AI
Jan 05, 2026Despite recent advances in machine learning and explainable AI, a gap remains in personalized preventive healthcare: predictions, interventions, and recommendations should be both understandable and verifiable for all stakeholders in the healthcare sector. We present a demonstration of how prototype-based learning can address these needs. Our proposed framework, ProtoPal, features both front- and back-end modes; it achieves superior quantitative performance while also providing an intuitive presentation of interventions and their simulated outcomes.
A Robust Prototype-Based Network with Interpretable RBF Classifier Foundations
Dec 20, 2024Prototype-based classification learning methods are known to be inherently interpretable. However, this paradigm suffers from major limitations compared to deep models, such as lower performance. This led to the development of the so-called deep Prototype-Based Networks (PBNs), also known as prototypical parts models. In this work, we analyze these models with respect to different properties, including interpretability. In particular, we focus on the Classification-by-Components (CBC) approach, which uses a probabilistic model to ensure interpretability and can be used as a shallow or deep architecture. We show that this model has several shortcomings, like creating contradicting explanations. Based on these findings, we propose an extension of CBC that solves these issues. Moreover, we prove that this extension has robustness guarantees and derive a loss that optimizes robustness. Additionally, our analysis shows that most (deep) PBNs are related to (deep) RBF classifiers, which implies that our robustness guarantees generalize to shallow RBF classifiers. The empirical evaluation demonstrates that our deep PBN yields state-of-the-art classification accuracy on different benchmarks while resolving the interpretability shortcomings of other approaches. Further, our shallow PBN variant outperforms other shallow PBNs while being inherently interpretable and exhibiting provable robustness guarantees.
GOV-REK: Governed Reward Engineering Kernels for Designing Robust Multi-Agent Reinforcement Learning Systems
Apr 14, 2024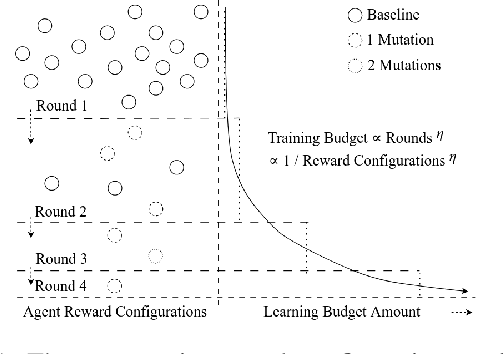
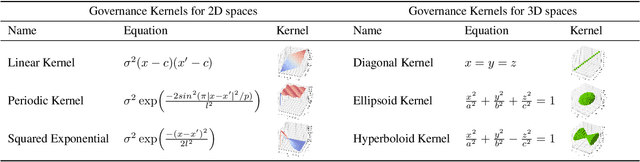
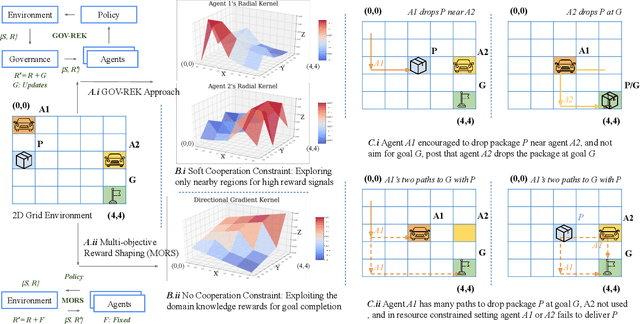
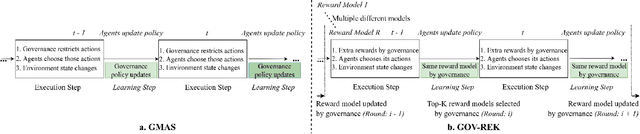
For multi-agent reinforcement learning systems (MARLS), the problem formulation generally involves investing massive reward engineering effort specific to a given problem. However, this effort often cannot be translated to other problems; worse, it gets wasted when system dynamics change drastically. This problem is further exacerbated in sparse reward scenarios, where a meaningful heuristic can assist in the policy convergence task. We propose GOVerned Reward Engineering Kernels (GOV-REK), which dynamically assign reward distributions to agents in MARLS during its learning stage. We also introduce governance kernels, which exploit the underlying structure in either state or joint action space for assigning meaningful agent reward distributions. During the agent learning stage, it iteratively explores different reward distribution configurations with a Hyperband-like algorithm to learn ideal agent reward models in a problem-agnostic manner. Our experiments demonstrate that our meaningful reward priors robustly jumpstart the learning process for effectively learning different MARL problems.
RerrFact: Reduced Evidence Retrieval Representations for Scientific Claim Verification
Feb 05, 2022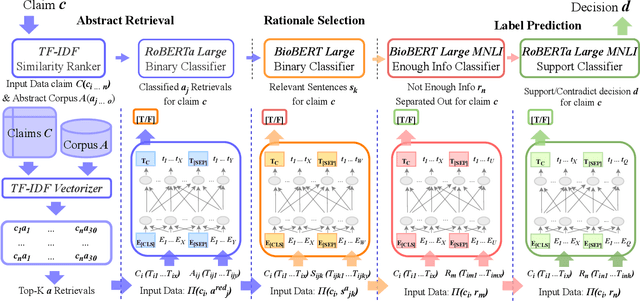



Exponential growth in digital information outlets and the race to publish has made scientific misinformation more prevalent than ever. However, the task to fact-verify a given scientific claim is not straightforward even for researchers. Scientific claim verification requires in-depth knowledge and great labor from domain experts to substantiate supporting and refuting evidence from credible scientific sources. The SciFact dataset and corresponding task provide a benchmarking leaderboard to the community to develop automatic scientific claim verification systems via extracting and assimilating relevant evidence rationales from source abstracts. In this work, we propose a modular approach that sequentially carries out binary classification for every prediction subtask as in the SciFact leaderboard. Our simple classifier-based approach uses reduced abstract representations to retrieve relevant abstracts. These are further used to train the relevant rationale-selection model. Finally, we carry out two-step stance predictions that first differentiate non-relevant rationales and then identify supporting or refuting rationales for a given claim. Experimentally, our system RerrFact with no fine-tuning, simple design, and a fraction of model parameters fairs competitively on the leaderboard against large-scale, modular, and joint modeling approaches. We make our codebase available at https://github.com/ashishrana160796/RerrFact.
Building Safer Autonomous Agents by Leveraging Risky Driving Behavior Knowledge
Mar 31, 2021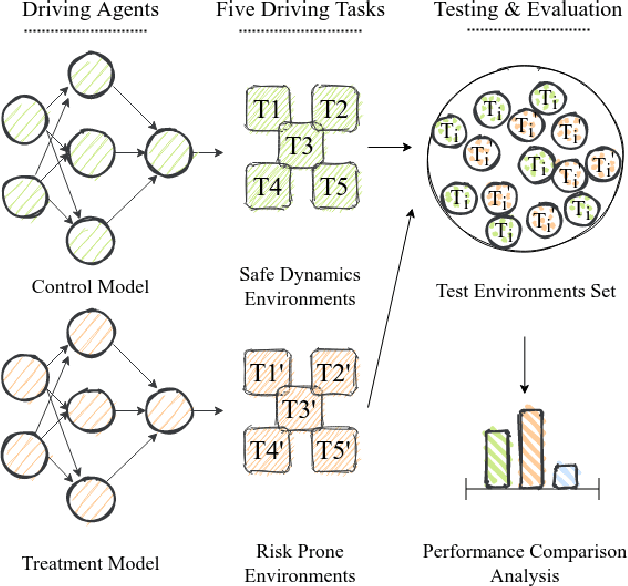
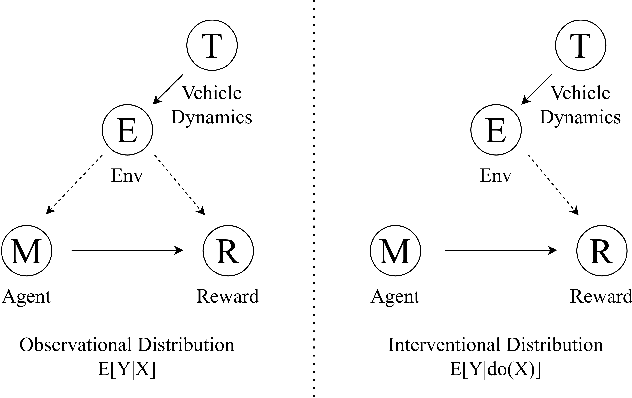


Simulation environments are good for learning different driving tasks like lane changing, parking or handling intersections etc. in an abstract manner. However, these simulation environments often restrict themselves to operate under conservative interactions behavior amongst different vehicles. But, as we know that the real driving tasks often involves very high risk scenarios where other drivers often don't behave in the expected sense. There can be many reasons for this behavior like being tired or inexperienced. The simulation environments doesn't take this information into account while training the navigation agent. Therefore, in this study we especially focus on systematically creating these risk prone scenarios with heavy traffic and unexpected random behavior for creating better model-free learning agents. We generate multiple autonomous driving scenarios by creating new custom Markov Decision Process (MDP) environment iterations in highway-env simulation package. The behavior policy is learnt by agents trained with the help from deep reinforcement learning models. Our behavior policy is deliberated to handle collisions and risky randomized driver behavior. We train model free learning agents with supplement information of risk prone driving scenarios and compare their performance with baseline agents. Finally, we casually measure the impact of adding these perturbations in the training process to precisely account for the performance improvement attained from utilizing the learnings from these scenarios.
Exploring Cell counting with Neural Arithmetic Logic Units
Apr 14, 2020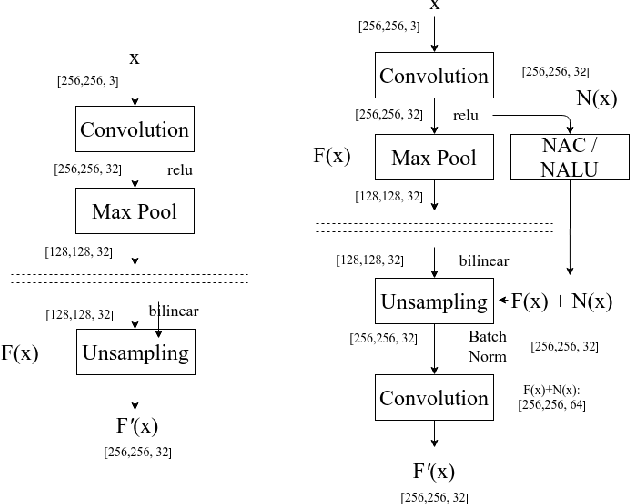
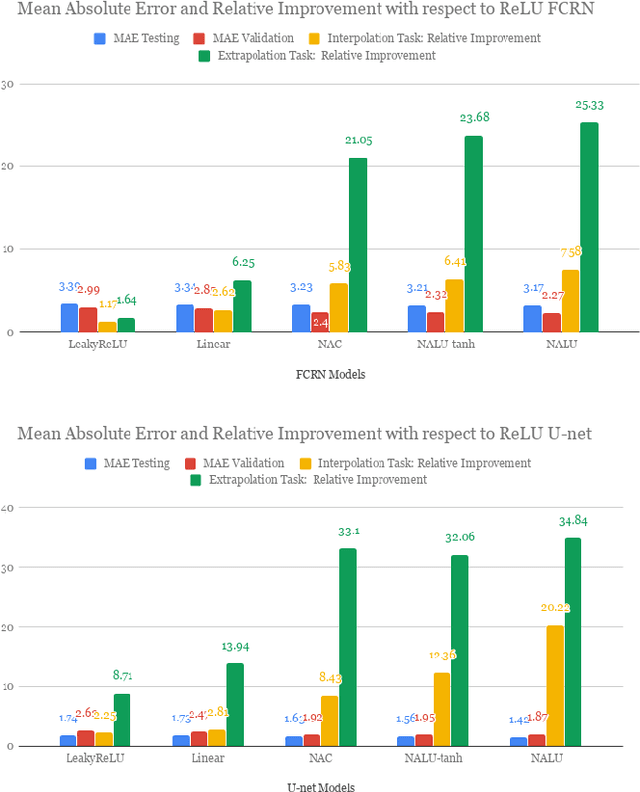
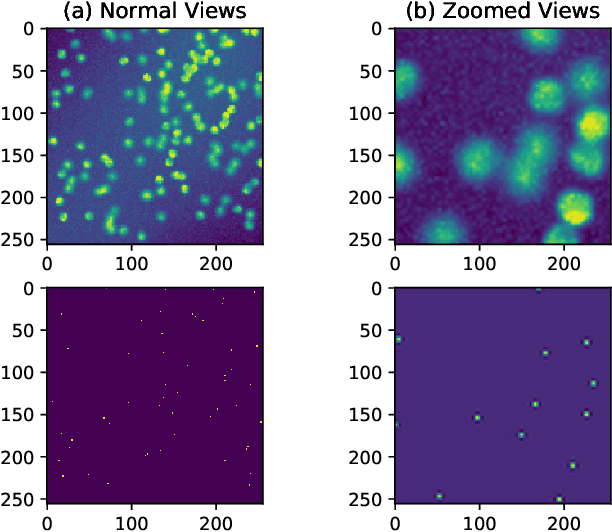
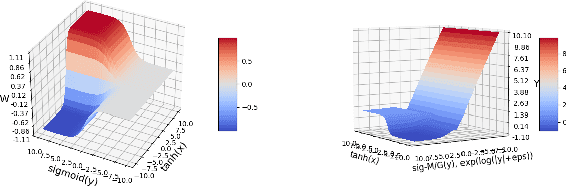
The big problem for neural network models which are trained to count instances is that whenever test range goes high training range generalization error increases i.e. they are not good generalizers outside training range. Consider the case of automating cell counting process where more dense images with higher cell counts are commonly encountered as compared to images used in training data. By making better predictions for higher ranges of cell count we are aiming to create better generalization systems for cell counting. With architecture proposal of neural arithmetic logic units (NALU) for arithmetic operations, task of counting has become feasible for higher numeric ranges which were not included in training data with better accuracy. As a part of our study we used these units and different other activation functions for learning cell counting task with two different architectures namely Fully Convolutional Regression Network and U-Net. These numerically biased units are added in the form of residual concatenated layers to original architectures and a comparative experimental study is done with these newly proposed changes . This comparative study is described in terms of optimizing regression loss problem from these models trained with extensive data augmentation techniques. We were able to achieve better results in our experiments of cell counting tasks with introduction of these numerically biased units to already existing architectures in the form of residual layer concatenation connections. Our results confirm that above stated numerically biased units does help models to learn numeric quantities for better generalization results.