 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Based Learning for Healthcare: A Demonstration of Interpretable AI
Jan 05, 2026Despite recent advances in machine learning and explainable AI, a gap remains in personalized preventive healthcare: predictions, interventions, and recommendations should be both understandable and verifiable for all stakeholders in the healthcare sector. We present a demonstration of how prototype-based learning can address these needs. Our proposed framework, ProtoPal, features both front- and back-end modes; it achieves superior quantitative performance while also providing an intuitive presentation of interventions and their simulated outcomes.
A Robust Prototype-Based Network with Interpretable RBF Classifier Foundations
Dec 20, 2024Prototype-based classification learning methods are known to be inherently interpretable. However, this paradigm suffers from major limitations compared to deep models, such as lower performance. This led to the development of the so-called deep Prototype-Based Networks (PBNs), also known as prototypical parts models. In this work, we analyze these models with respect to different properties, including interpretability. In particular, we focus on the Classification-by-Components (CBC) approach, which uses a probabilistic model to ensure interpretability and can be used as a shallow or deep architecture. We show that this model has several shortcomings, like creating contradicting explanations. Based on these findings, we propose an extension of CBC that solves these issues. Moreover, we prove that this extension has robustness guarantees and derive a loss that optimizes robustness. Additionally, our analysis shows that most (deep) PBNs are related to (deep) RBF classifiers, which implies that our robustness guarantees generalize to shallow RBF classifiers. The empirical evaluation demonstrates that our deep PBN yields state-of-the-art classification accuracy on different benchmarks while resolving the interpretability shortcomings of other approaches. Further, our shallow PBN variant outperforms other shallow PBNs while being inherently interpretable and exhibiting provable robustness guarantees.
Uncertainty Propagation in Node Classification
Apr 03, 2023Quantifying predictive uncertainty of neural networks has recently attracted increasing attention. In this work, we focus on measuring uncertainty of graph neural networks (GNNs) for the task of node classification. Most existing GNNs model message passing among nodes. The messages are often deterministic. Questions naturally arise: Does there exist uncertainty in the messages? How could we propagate such uncertainty over a graph together with messages? To address these issues, we propose a Bayesian uncertainty propagation (BUP) method, which embeds GNNs in a Bayesian modeling framework, and models predictive uncertainty of node classification with Bayesian confidence of predictive probability and uncertainty of messages. Our method proposes a novel uncertainty propagation mechanism inspired by Gaussian models. Moreover, we present an uncertainty oriented loss for node classification that allows the GNNs to clearly integrate predictive uncertainty in learning procedure. Consequently, the training examples with large predictive uncertainty will be penalized. We demonstrate the BUP with respect to prediction reliability and out-of-distribution (OOD) predictions. The learned uncertainty is also analyzed in depth. The relations between uncertainty and graph topology, as well as predictive uncertainty in the OOD cases are investigated with extensive experiments. The empirical results with popular benchmark datasets demonstrate the superior performance of the proposed method.
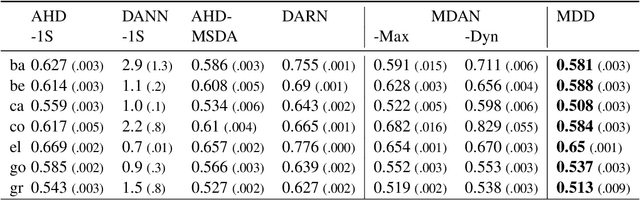
Multi-Source Survival Domain Adaptation
Dec 01, 2022Survival analysis is the branch of statistics that studies the relation between the characteristics of living entities and their respective survival times, taking into account the partial information held by censored cases. A good analysis can, for example, determine whether one medical treatment for a group of patients is better than another. With the rise of machine learning, survival analysis can be modeled as learning a function that maps studied patients to their survival times. To succeed with that, there are three crucial issues to be tackled. First, some patient data is censored: we do not know the true survival times for all patients. Second, data is scarce, which led past research to treat different illness types as domains in a multi-task setup. Third, there is the need for adaptation to new or extremely rare illness types, where little or no labels are available. In contrast to previous multi-task setups, we want to investigate how to efficiently adapt to a new survival target domain from multiple survival source domains. For this, we introduce a new survival metric and the corresponding discrepancy measure between survival distributions. These allow us to define domain adaptation for survival analysis while incorporating censored data, which would otherwise have to be dropped. Our experiments on two cancer data sets reveal a superb performance on target domains, a better treatment recommendation, and a weight matrix with a plausible explanation.
Human-Centric Research for NLP: Towards a Definition and Guiding Questions
Jul 10, 2022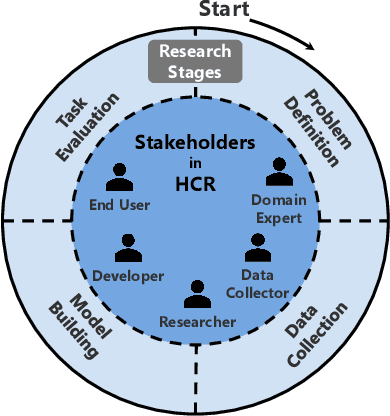

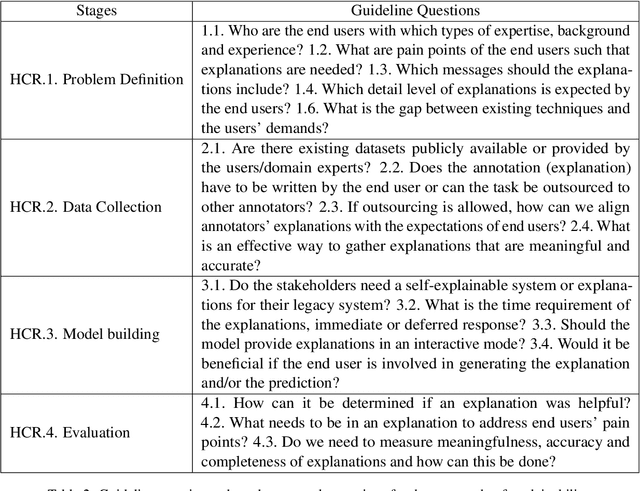
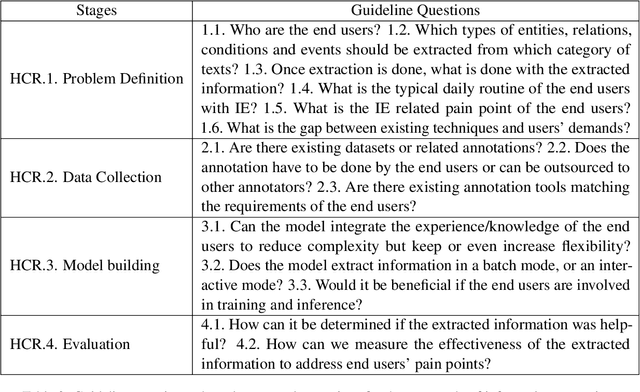
With Human-Centric Research (HCR) we can steer research activities so that the research outcome is beneficial for human stakeholders, such as end users. But what exactly makes research human-centric? We address this question by providing a working definition and define how a research pipeline can be split into different stages in which human-centric components can be added. Additionally, we discuss existing NLP with HCR components and define a series of guiding questions, which can serve as starting points for researchers interested in exploring human-centric research approaches. We hope that this work would inspire researchers to refine the proposed definition and to pose other questions that might be meaningful for achieving HCR.
A Human-Centric Assessment Framework for AI
May 25, 2022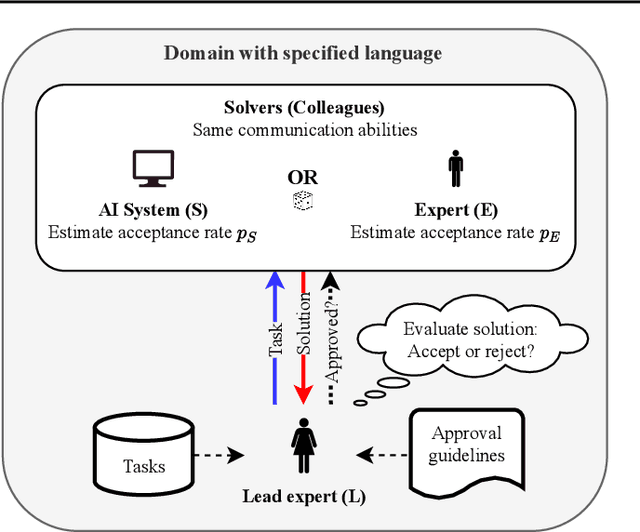
With the rise of AI systems in real-world applications comes the need for reliable and trustworthy AI. An important aspect for this are explainable AI systems. However, there is no agreed standard on how explainable AI systems should be assessed. Inspired by the Turing test, we introduce a human-centric assessment framework where a leading domain expert accepts or rejects the solutions of an AI system and another domain expert. By comparing the acceptance rates of provided solutions, we can assess how the AI system performs in comparison to the domain expert, and in turn whether or not the AI system's explanations (if provided) are human understandable. This setup -- comparable to the Turing test -- can serve as framework for a wide range of human-centric AI system assessments. We demonstrate this by presenting two instantiations: (1) an assessment that measures the classification accuracy of a system with the option to incorporate label uncertainties; (2) an assessment where the usefulness of provided explanations is determined in a human-centric manner.
Learning to Transfer with von Neumann Conditional Divergence
Aug 07, 2021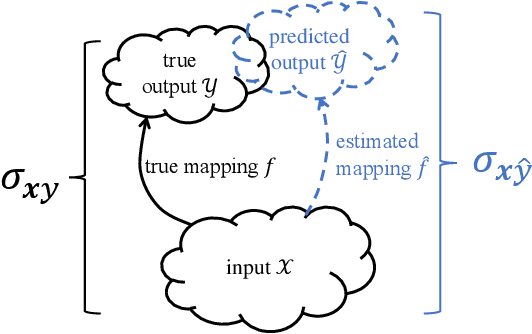
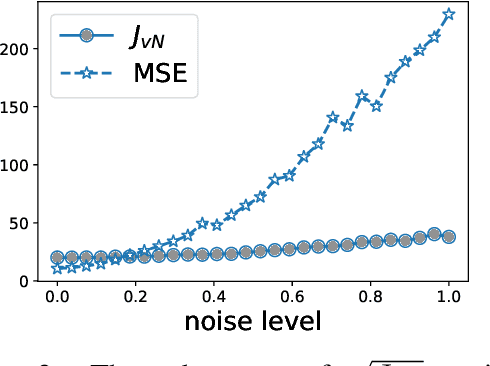
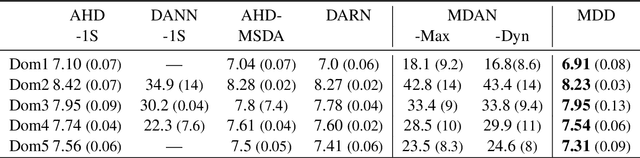
The similarity of feature representations plays a pivotal role in the success of domain adaptation and generalization. Feature similarity includes both the invariance of marginal distributions and the closeness of conditional distributions given the desired response $y$ (e.g., class labels). Unfortunately, traditional methods always learn such features without fully taking into consideration the information in $y$, which in turn may lead to a mismatch of the conditional distributions or the mix-up of discriminative structures underlying data distributions. In this work, we introduce the recently proposed von Neumann conditional divergence to improve the transferability across multiple domains. We show that this new divergence is differentiable and eligible to easily quantify the functional dependence between features and $y$. Given multiple source tasks, we integrate this divergence to capture discriminative information in $y$ and design novel learning objectives assuming those source tasks are observed either simultaneously or sequentially. In both scenarios, we obtain favorable performance against state-of-the-art methods in terms of smaller generalization error on new tasks and less catastrophic forgetting on source tasks (in the sequential setup).
Modular-Relatedness for Continual Learning
Nov 02, 2020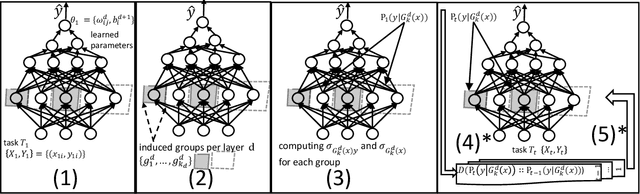
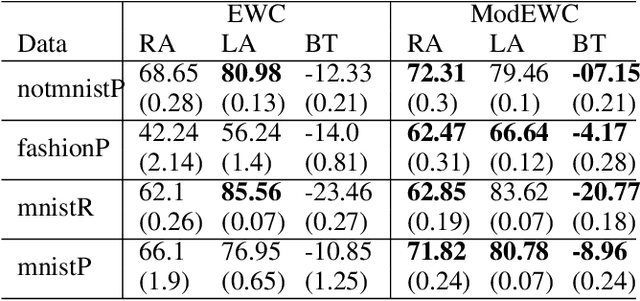
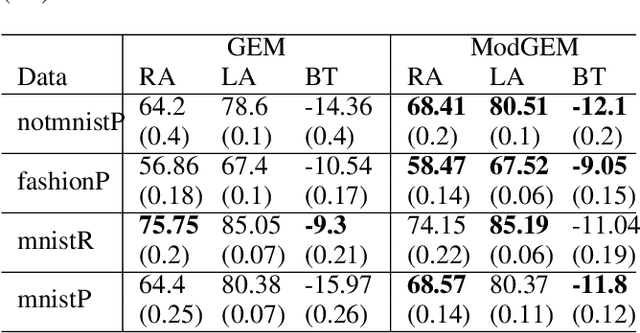
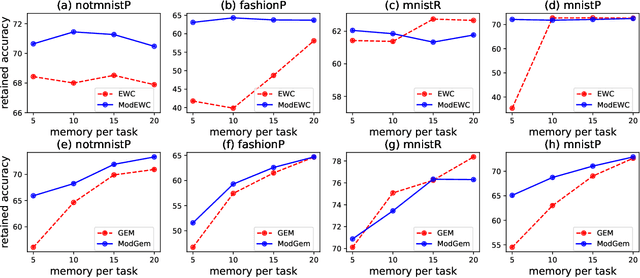
In this paper, we propose a continual learning (CL) technique that is beneficial to sequential task learners by improving their retained accuracy and reducing catastrophic forgetting. The principal target of our approach is the automatic extraction of modular parts of the neural network and then estimating the relatedness between the tasks given these modular components. This technique is applicable to different families of CL methods such as regularization-based (e.g., the Elastic Weight Consolidation) or the rehearsal-based (e.g., the Gradient Episodic Memory) approaches where episodic memory is needed. Empirical results demonstrate remarkable performance gain (in terms of robustness to forgetting) for methods such as EWC and GEM based on our technique, especially when the memory budget is very limited.
Bilevel Continual Learning
Nov 02, 2020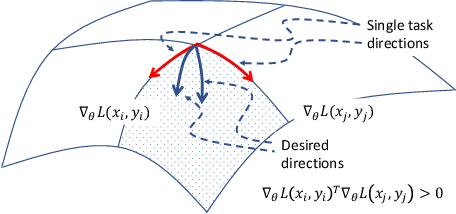
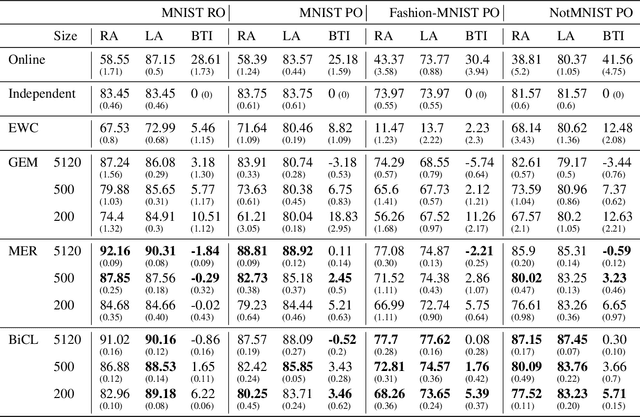
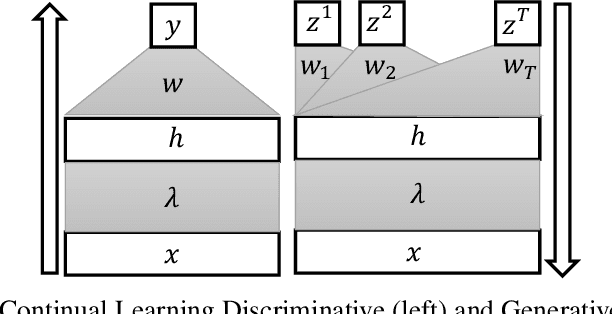

Continual learning (CL) studies the problem of learning a sequence of tasks, one at a time, such that the learning of each new task does not lead to the deterioration in performance on the previously seen ones while exploiting previously learned features. This paper presents Bilevel Continual Learning (BiCL), a general framework for continual learning that fuses bilevel optimization and recent advances in meta-learning for deep neural networks. BiCL is able to train both deep discriminative and generative models under the conservative setting of the online continual learning. Experimental results show that BiCL provides competitive performance in terms of accuracy for the current task while reducing the effect of catastrophic forgetting. This is a concurrent work with [1]. We submitted it to AAAI 2020 and IJCAI 2020. Now we put it on the arxiv for record. Different from [1], we also consider continual generative model as well. At the same time, the authors are aware of a recent proposal on bilevel optimization based coreset construction for continual learning [2]. [1] Q. Pham, D. Sahoo, C. Liu, and S. C. Hoi. Bilevel continual learning. arXiv preprint arXiv:2007.15553, 2020. [2] Z. Borsos, M. Mutny, and A. Krause. Coresets via bilevel optimization for continual learning and streaming. arXiv preprint arXiv:2006.03875, 2020
Learning an Interpretable Graph Structure in Multi-Task Learning
Sep 11, 2020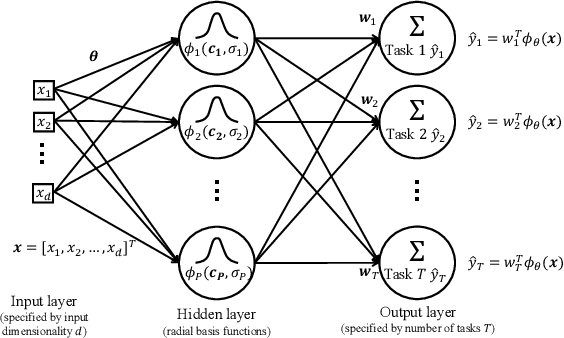
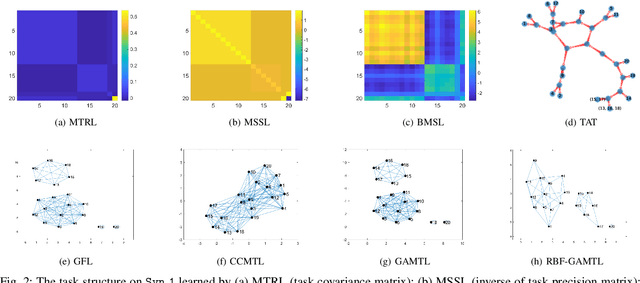
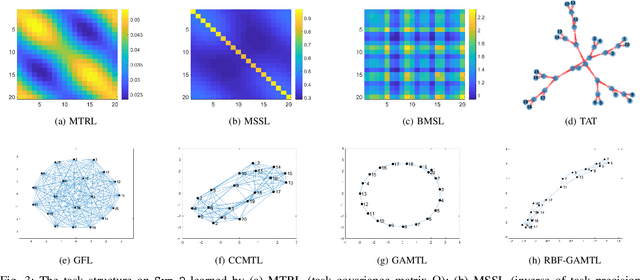
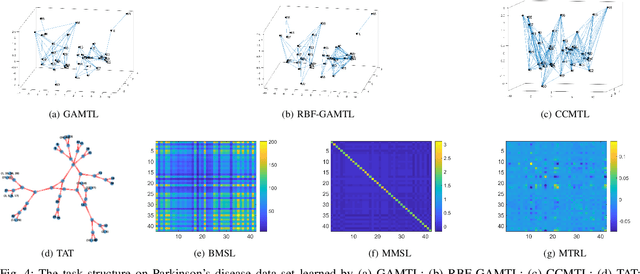
We present a novel methodology to jointly perform multi-task learning and infer intrinsic relationship among tasks by an interpretable and sparse graph. Unlike existing multi-task learning methodologies, the graph structure is not assumed to be known a priori or estimated separately in a preprocessing step. Instead, our graph is learned simultaneously with model parameters of each task, thus it reflects the critical relationship among tasks in the specific prediction problem. We characterize graph structure with its weighted adjacency matrix and show that the overall objective can be optimized alternatively until convergence. We also show that our methodology can be simply extended to a nonlinear form by being embedded into a multi-head radial basis function network (RBFN). Extensive experiments, against six state-of-the-art methodologies, on both synthetic data and real-world applications suggest that our methodology is able to reduce generalization error, and, at the same time, reveal a sparse graph over tasks that is much easier to interpret.