 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountTRuCoLa: Rule Confidence Learning for Temporal Knowledge Graph Forecasting
Sep 11, 2025We address the task of temporal knowledge graph (TKG) forecasting by introducing a fully explainable method based on temporal rules. Motivated by recent work proposing a strong baseline using recurrent facts, our approach learns four simple types of rules with a confidence function that considers both recency and frequency. Evaluated on nine datasets, our method matches or surpasses the performance of eight state-of-the-art models and two baselines, while providing fully interpretable predictions.
TGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous Graphs
Jun 14, 2024Multi-relational temporal graphs are powerful tools for modeling real-world data, capturing the evolving and interconnected nature of entities over time. Recently, many novel models are proposed for ML on such graphs intensifying the need for robust evaluation and standardized benchmark datasets. However, the availability of such resources remains scarce and evaluation faces added complexity due to reproducibility issues in experimental protocols. To address these challenges, we introduce Temporal Graph Benchmark 2.0 (TGB 2.0), a novel benchmarking framework tailored for evaluating methods for predicting future links on Temporal Knowledge Graphs and Temporal Heterogeneous Graphs with a focus on large-scale datasets, extending the Temporal Graph Benchmark. TGB 2.0 facilitates comprehensive evaluations by presenting eight novel datasets spanning five domains with up to 53 million edges. TGB 2.0 datasets are significantly larger than existing datasets in terms of number of nodes, edges, or timestamps. In addition, TGB 2.0 provides a reproducible and realistic evaluation pipeline for multi-relational temporal graphs. Through extensive experimentation, we observe that 1) leveraging edge-type information is crucial to obtain high performance, 2) simple heuristic baselines are often competitive with more complex methods, 3) most methods fail to run on our largest datasets, highlighting the need for research on more scalable methods.
History repeats Itself: A Baseline for Temporal Knowledge Graph Forecasting
Apr 29, 2024


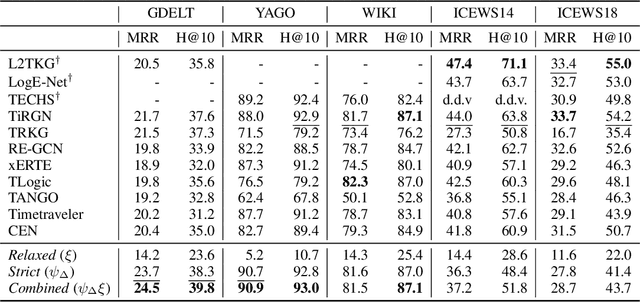
Temporal Knowledge Graph (TKG) Forecasting aims at predicting links in Knowledge Graphs for future timesteps based on a history of Knowledge Graphs. To this day, standardized evaluation protocols and rigorous comparison across TKG models are available, but the importance of simple baselines is often neglected in the evaluation, which prevents researchers from discerning actual and fictitious progress. We propose to close this gap by designing an intuitive baseline for TKG Forecasting based on predicting recurring facts. Compared to most TKG models, it requires little hyperparameter tuning and no iterative training. Further, it can help to identify failure modes in existing approaches. The empirical findings are quite unexpected: compared to 11 methods on five datasets, our baseline ranks first or third in three of them, painting a radically different picture of the predictive quality of the state of the art.
Human-Centric Research for NLP: Towards a Definition and Guiding Questions
Jul 10, 2022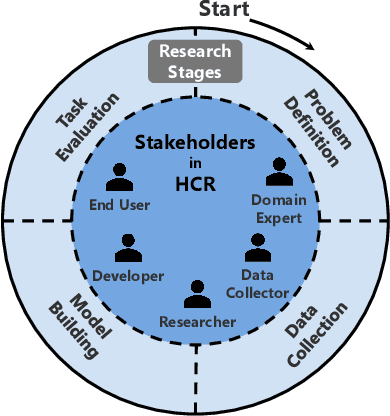

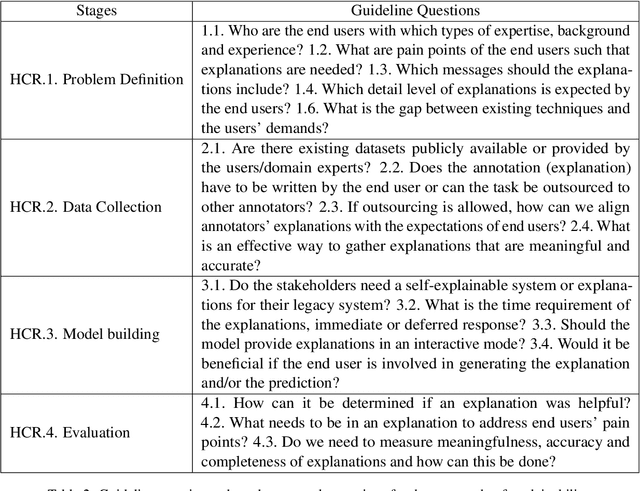
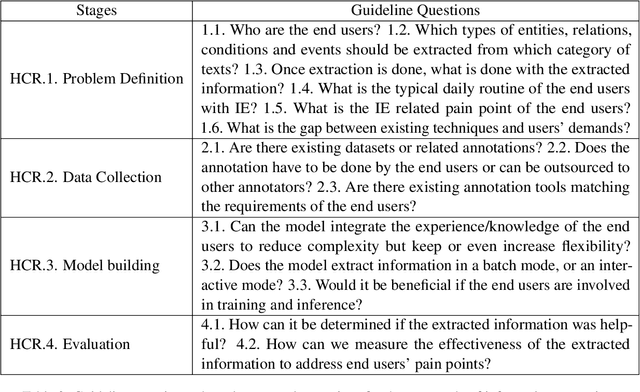
With Human-Centric Research (HCR) we can steer research activities so that the research outcome is beneficial for human stakeholders, such as end users. But what exactly makes research human-centric? We address this question by providing a working definition and define how a research pipeline can be split into different stages in which human-centric components can be added. Additionally, we discuss existing NLP with HCR components and define a series of guiding questions, which can serve as starting points for researchers interested in exploring human-centric research approaches. We hope that this work would inspire researchers to refine the proposed definition and to pose other questions that might be meaningful for achieving HCR.
ProcK: Machine Learning for Knowledge-Intensive Processes
Sep 10, 2021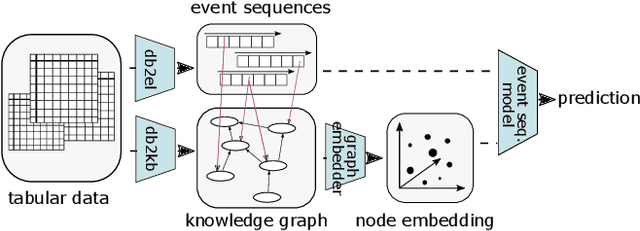
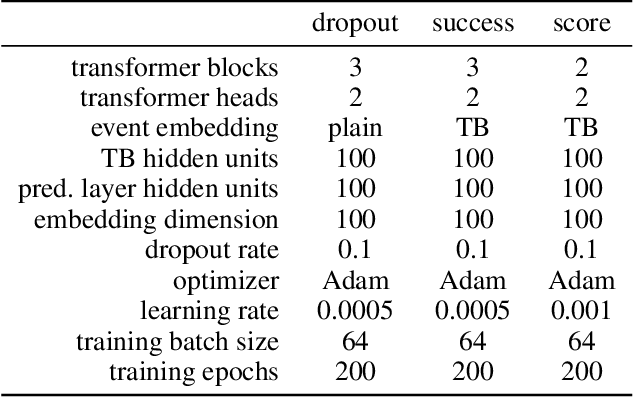
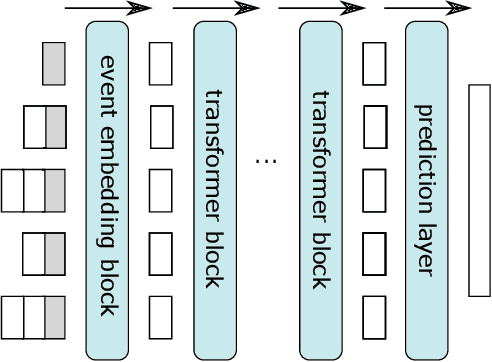
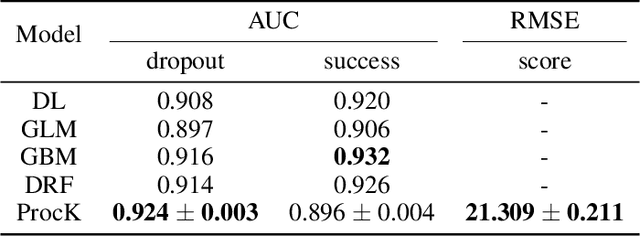
Process mining deals with extraction of knowledge from business process execution logs. Traditional process mining tasks, like process model generation or conformance checking, rely on a minimalistic feature set where each event is characterized only by its case identifier, activity type, and timestamp. In contrast, the success of modern machine learning is based on models that take any available data as direct input and build layers of features automatically during training. In this work, we introduce ProcK (Process & Knowledge), a novel pipeline to build business process prediction models that take into account both sequential data in the form of event logs and rich semantic information represented in a graph-structured knowledge base. The hybrid approach enables ProcK to flexibly make use of all information residing in the databases of organizations. Components to extract inter-linked event logs and knowledge bases from relational databases are part of the pipeline. We demonstrate the power of ProcK by training it for prediction tasks on the OULAD e-learning dataset, where we achieve state-of-the-art performance on the tasks of predicting student dropout from courses and predicting their success. We also apply our method on a number of additional machine learning tasks, including exam score prediction and early predictions that only take into account data recorded during the first weeks of the courses.
A study on Ensemble Learning for Time Series Forecasting and the need for Meta-Learning
Apr 23, 2021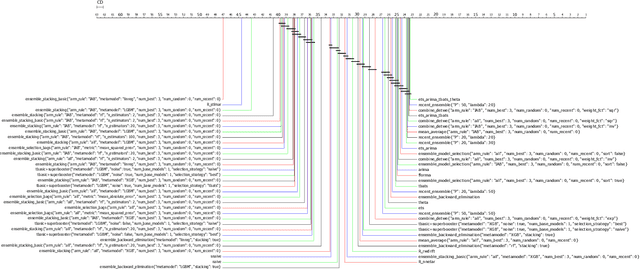
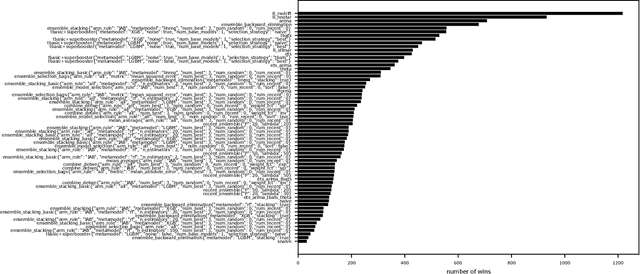

The contribution of this work is twofold: (1) We introduce a collection of ensemble methods for time series forecasting to combine predictions from base models. We demonstrate insights on the power of ensemble learning for forecasting, showing experiment results on about 16000 openly available datasets, from M4, M5, M3 competitions, as well as FRED (Federal Reserve Economic Data) datasets. Whereas experiments show that ensembles provide a benefit on forecasting results, there is no clear winning ensemble strategy (plus hyperparameter configuration). Thus, in addition, (2), we propose a meta-learning step to choose, for each dataset, the most appropriate ensemble method and their hyperparameter configuration to run based on dataset meta-features.
HAMLET -- A Learning Curve-Enabled Multi-Armed Bandit for Algorithm Selection
Jan 30, 2020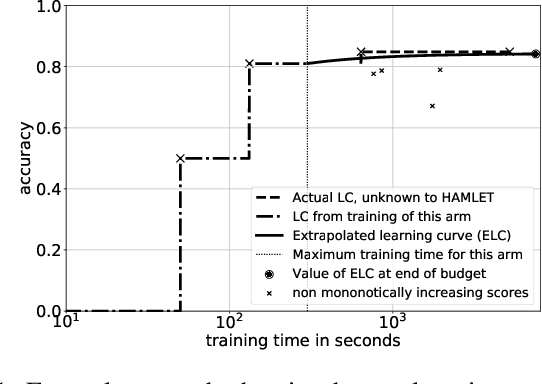
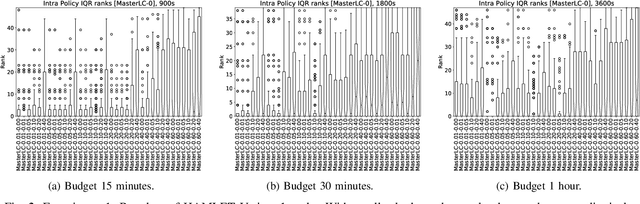
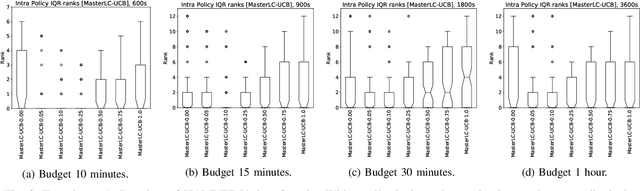
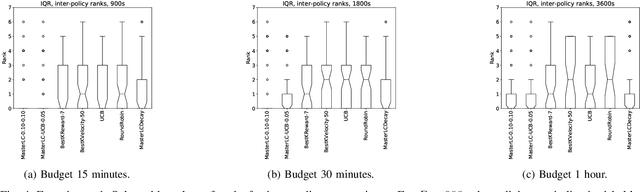
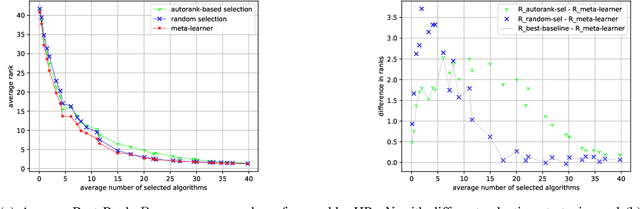
Automated algorithm selection and hyperparameter tuning facilitates the application of machine learning. Traditional multi-armed bandit strategies look to the history of observed rewards to identify the most promising arms for optimizing expected total reward in the long run. When considering limited time budgets and computational resources, this backward view of rewards is inappropriate as the bandit should look into the future for anticipating the highest final reward at the end of a specified time budget. This work addresses that insight by introducing HAMLET, which extends the bandit approach with learning curve extrapolation and computation time-awareness for selecting among a set of machine learning algorithms. Results show that the HAMLET Variants 1-3 exhibit equal or better performance than other bandit-based algorithm selection strategies in experiments with recorded hyperparameter tuning traces for the majority of considered time budgets. The best performing HAMLET Variant 3 combines learning curve extrapolation with the well-known upper confidence bound exploration bonus. That variant performs better than all non-HAMLET policies with statistical significance at the 95% level for 1,485 runs.
On the Performance of Differential Evolution for Hyperparameter Tuning
Apr 15, 2019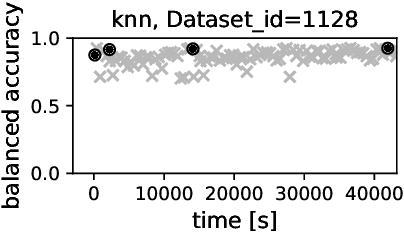
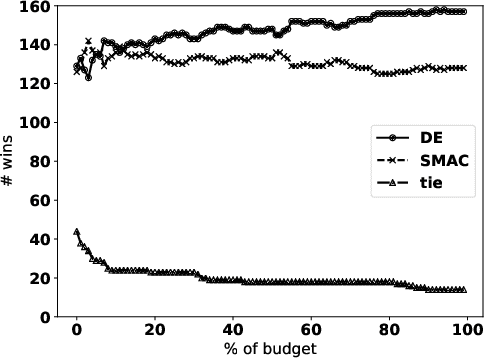

Automated hyperparameter tuning aspires to facilitate the application of machine learning for non-experts. In the literature, different optimization approaches are applied for that purpose. This paper investigates the performance of Differential Evolution for tuning hyperparameters of supervised learning algorithms for classification tasks. This empirical study involves a range of different machine learning algorithms and datasets with various characteristics to compare the performance of Differential Evolution with Sequential Model-based Algorithm Configuration (SMAC), a reference Bayesian Optimization approach. The results indicate that Differential Evolution outperforms SMAC for most datasets when tuning a given machine learning algorithm - particularly when breaking ties in a first-to-report fashion. Only for the tightest of computational budgets SMAC performs better. On small datasets, Differential Evolution outperforms SMAC by 19% (37% after tie-breaking). In a second experiment across a range of representative datasets taken from the literature, Differential Evolution scores 15% (23% after tie-breaking) more wins than SMAC.