 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of the Learning Progress in Neural Architecture Search Techniques
Jun 18, 2019
In neural architecture search, the structure of the neural network to best model a given dataset is determined by an automated search process. Efficient Neural Architecture Search (ENAS), proposed by Pham et al. (2018), has recently received considerable attention due to its ability to find excellent architectures within a comparably short search time. In this work, which is motivated by the quest to further improve the learning speed of architecture search, we evaluate the learning progress of the controller which generates the architectures in ENAS. We measure the progress by comparing the architectures generated by it at different controller training epochs, where architectures are evaluated after having re-trained them from scratch. As a surprising result, we find that the learning curves are completely flat, i.e., there is no observable progress of the controller in terms of the performance of its generated architectures. This observation is consistent across the CIFAR-10 and CIFAR-100 datasets and two different search spaces. We conclude that the high quality of the models generated by ENAS is a result of the search space design rather than the controller training, and our results indicate that one-shot architecture design is an efficient alternative to architecture search by ENAS.
On the Performance of Differential Evolution for Hyperparameter Tuning
Apr 15, 2019
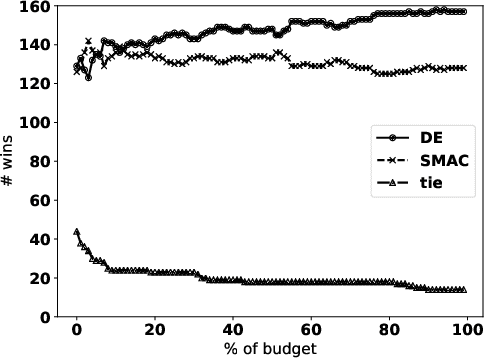

Automated hyperparameter tuning aspires to facilitate the application of machine learning for non-experts. In the literature, different optimization approaches are applied for that purpose. This paper investigates the performance of Differential Evolution for tuning hyperparameters of supervised learning algorithms for classification tasks. This empirical study involves a range of different machine learning algorithms and datasets with various characteristics to compare the performance of Differential Evolution with Sequential Model-based Algorithm Configuration (SMAC), a reference Bayesian Optimization approach. The results indicate that Differential Evolution outperforms SMAC for most datasets when tuning a given machine learning algorithm - particularly when breaking ties in a first-to-report fashion. Only for the tightest of computational budgets SMAC performs better. On small datasets, Differential Evolution outperforms SMAC by 19% (37% after tie-breaking). In a second experiment across a range of representative datasets taken from the literature, Differential Evolution scores 15% (23% after tie-breaking) more wins than SMAC.