 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Ontology Matching with Cost-Efficient Learning
Apr 11, 2024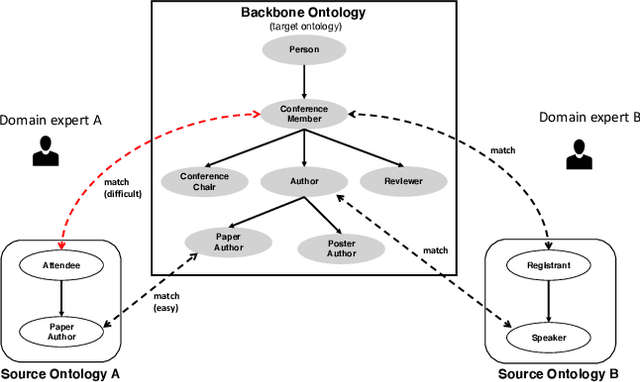
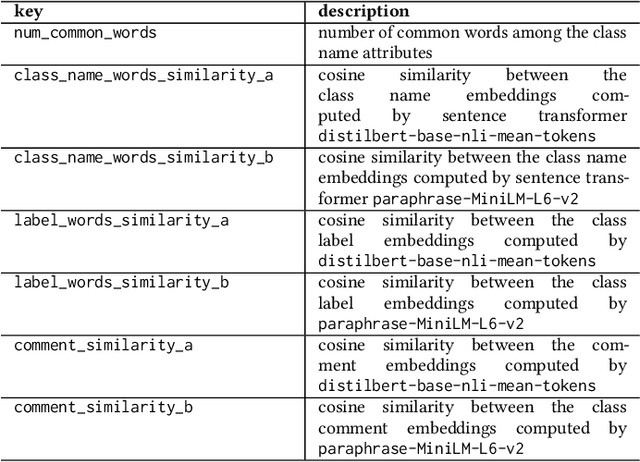
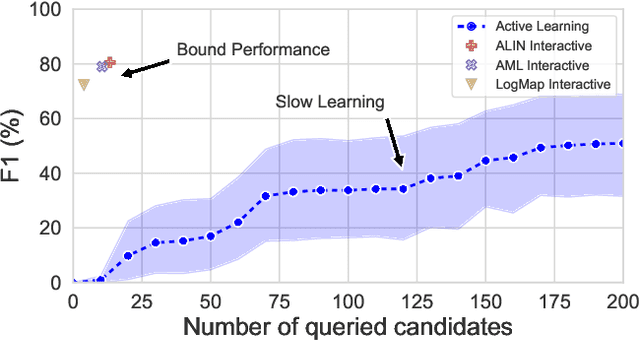
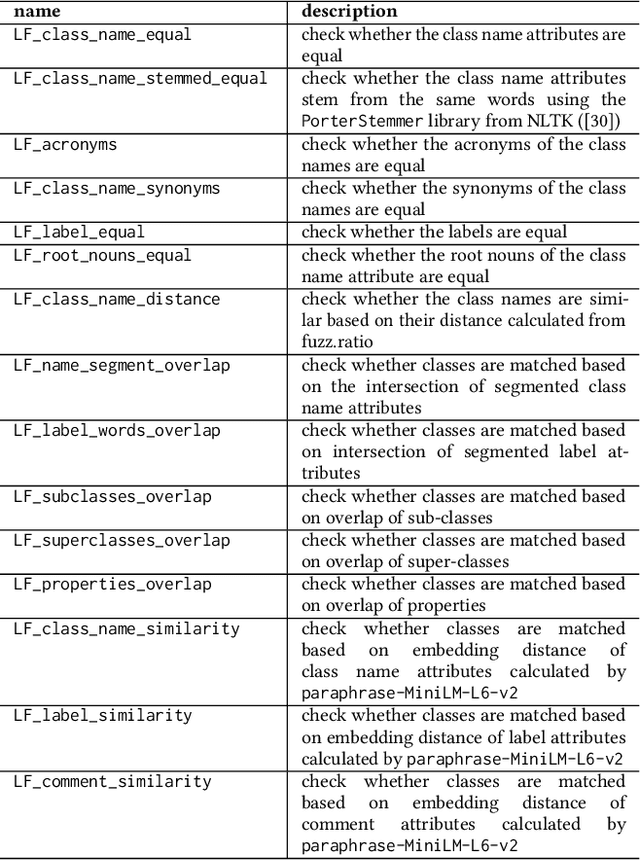
The creation of high-quality ontologies is crucial for data integration and knowledge-based reasoning, specifically in the context of the rising data economy. However, automatic ontology matchers are often bound to the heuristics they are based on, leaving many matches unidentified. Interactive ontology matching systems involving human experts have been introduced, but they do not solve the fundamental issue of flexibly finding additional matches outside the scope of the implemented heuristics, even though this is highly demanded in industrial settings. Active machine learning methods appear to be a promising path towards a flexible interactive ontology matcher. However, off-the-shelf active learning mechanisms suffer from low query efficiency due to extreme class imbalance, resulting in a last-mile problem where high human effort is required to identify the remaining matches. To address the last-mile problem, this work introduces DualLoop, an active learning method tailored to ontology matching. DualLoop offers three main contributions: (1) an ensemble of tunable heuristic matchers, (2) a short-term learner with a novel query strategy adapted to highly imbalanced data, and (3) long-term learners to explore potential matches by creating and tuning new heuristics. We evaluated DualLoop on three datasets of varying sizes and domains. Compared to existing active learning methods, we consistently achieved better F1 scores and recall, reducing the expected query cost spent on finding 90% of all matches by over 50%. Compared to traditional interactive ontology matchers, we are able to find additional, last-mile matches. Finally, we detail the successful deployment of our approach within an actual product and report its operational performance results within the Architecture, Engineering, and Construction (AEC) industry sector, showcasing its practical value and efficiency.
ProcK: Machine Learning for Knowledge-Intensive Processes
Sep 10, 2021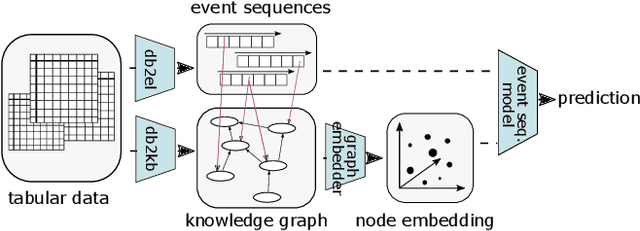
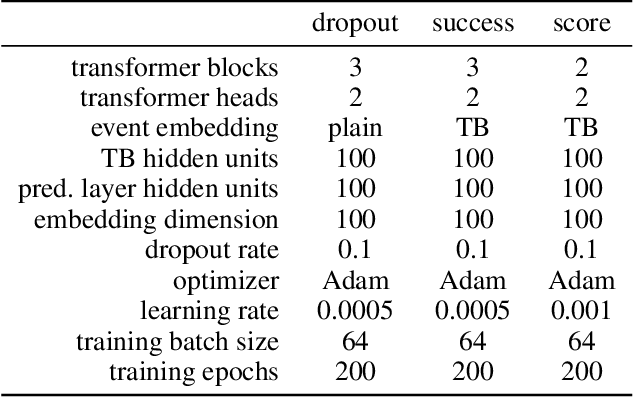
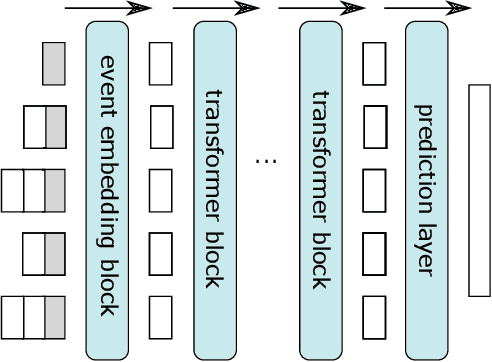
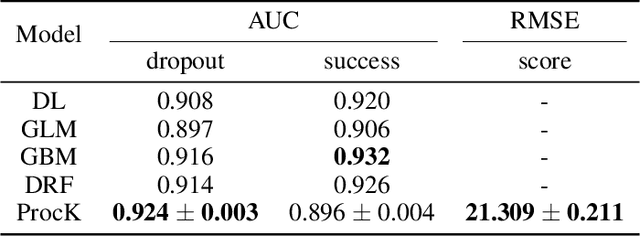
Process mining deals with extraction of knowledge from business process execution logs. Traditional process mining tasks, like process model generation or conformance checking, rely on a minimalistic feature set where each event is characterized only by its case identifier, activity type, and timestamp. In contrast, the success of modern machine learning is based on models that take any available data as direct input and build layers of features automatically during training. In this work, we introduce ProcK (Process & Knowledge), a novel pipeline to build business process prediction models that take into account both sequential data in the form of event logs and rich semantic information represented in a graph-structured knowledge base. The hybrid approach enables ProcK to flexibly make use of all information residing in the databases of organizations. Components to extract inter-linked event logs and knowledge bases from relational databases are part of the pipeline. We demonstrate the power of ProcK by training it for prediction tasks on the OULAD e-learning dataset, where we achieve state-of-the-art performance on the tasks of predicting student dropout from courses and predicting their success. We also apply our method on a number of additional machine learning tasks, including exam score prediction and early predictions that only take into account data recorded during the first weeks of the courses.
The Combinatorial Multi-Bandit Problem and its Application to Energy Management
Nov 04, 2020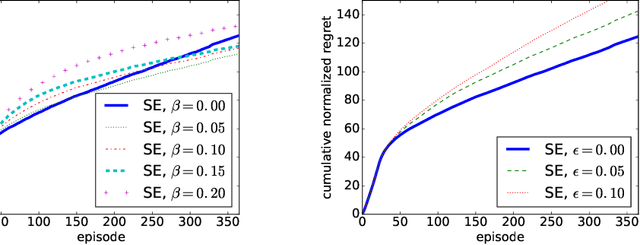
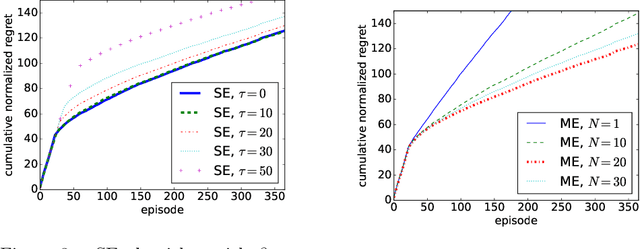
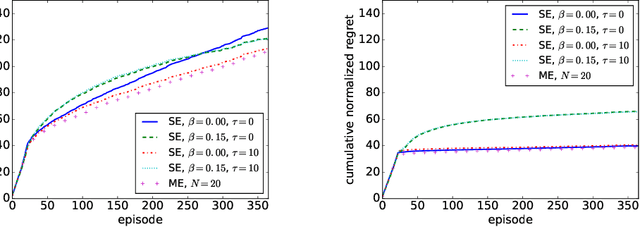
We study a Combinatorial Multi-Bandit Problem motivated by applications in energy systems management. Given multiple probabilistic multi-arm bandits with unknown outcome distributions, the task is to optimize the value of a combinatorial objective function mapping the vector of individual bandit outcomes to a single scalar reward. Unlike in single-bandit problems with multi-dimensional action space, the outcomes of the individual bandits are observable in our setting and the objective function is known. Guided by the hypothesis that individual observability enables better trade-offs between exploration and exploitation, we generalize the lower regret bound for single bandits, showing that indeed for multiple bandits it admits parallelized exploration. For our energy management application we propose a range of algorithms that combine exploration principles for multi-arm bandits with mathematical programming. In an experimental study we demonstrate the effectiveness of our approach to learn action assignments for 150 bandits, each having 24 actions, within a horizon of 365 episodes.
Large-Scale Cargo Distribution
Sep 29, 2020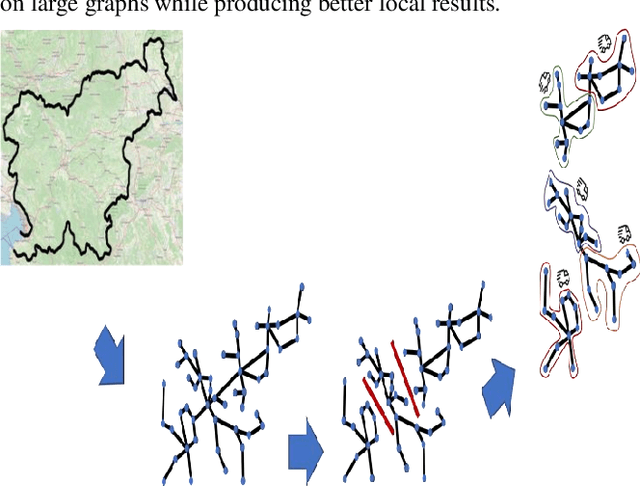

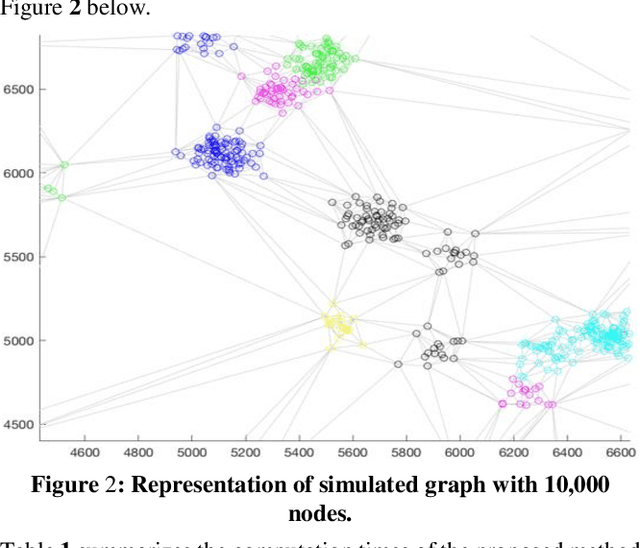

This study focuses on the design and development of methods for generating cargo distribution plans for large-scale logistics networks. It uses data from three large logistics operators while focusing on cross border logistics operations using one large graph. The approach uses a three-step methodology to first represent the logistic infrastructure as a graph, then partition the graph into smaller size regions, and finally generate cargo distribution plans for each individual region. The initial graph representation has been extracted from regional graphs by spectral clustering and is then further used for computing the distribution plan. The approach introduces methods for each of the modelling steps. The proposed approach on using regionalization of large logistics infrastructure for generating partial plans, enables scaling to thousands of drop-off locations. Results also show that the proposed approach scales better than the state-of-the-art, while preserving the quality of the solution. Our methodology is suited to address the main challenge in transforming rigid large logistics infrastructure into dynamic, just-in-time, and point-to-point delivery-oriented logistics operations.
A Study of the Learning Progress in Neural Architecture Search Techniques
Jun 18, 2019
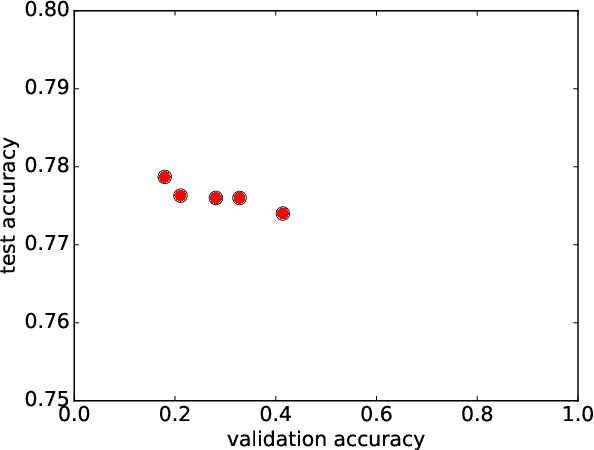
In neural architecture search, the structure of the neural network to best model a given dataset is determined by an automated search process. Efficient Neural Architecture Search (ENAS), proposed by Pham et al. (2018), has recently received considerable attention due to its ability to find excellent architectures within a comparably short search time. In this work, which is motivated by the quest to further improve the learning speed of architecture search, we evaluate the learning progress of the controller which generates the architectures in ENAS. We measure the progress by comparing the architectures generated by it at different controller training epochs, where architectures are evaluated after having re-trained them from scratch. As a surprising result, we find that the learning curves are completely flat, i.e., there is no observable progress of the controller in terms of the performance of its generated architectures. This observation is consistent across the CIFAR-10 and CIFAR-100 datasets and two different search spaces. We conclude that the high quality of the models generated by ENAS is a result of the search space design rather than the controller training, and our results indicate that one-shot architecture design is an efficient alternative to architecture search by ENAS.
On the Performance of Differential Evolution for Hyperparameter Tuning
Apr 15, 2019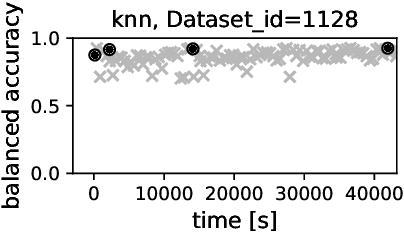
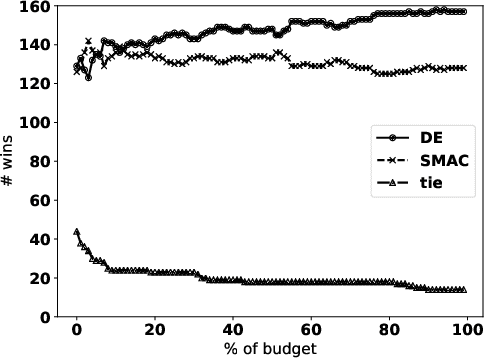
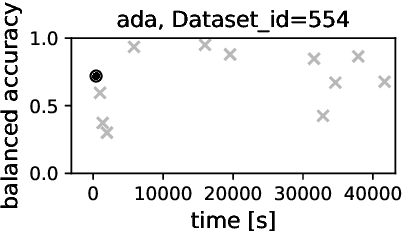

Automated hyperparameter tuning aspires to facilitate the application of machine learning for non-experts. In the literature, different optimization approaches are applied for that purpose. This paper investigates the performance of Differential Evolution for tuning hyperparameters of supervised learning algorithms for classification tasks. This empirical study involves a range of different machine learning algorithms and datasets with various characteristics to compare the performance of Differential Evolution with Sequential Model-based Algorithm Configuration (SMAC), a reference Bayesian Optimization approach. The results indicate that Differential Evolution outperforms SMAC for most datasets when tuning a given machine learning algorithm - particularly when breaking ties in a first-to-report fashion. Only for the tightest of computational budgets SMAC performs better. On small datasets, Differential Evolution outperforms SMAC by 19% (37% after tie-breaking). In a second experiment across a range of representative datasets taken from the literature, Differential Evolution scores 15% (23% after tie-breaking) more wins than SMAC.