 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextMine: LLM-Powered Knowledge Extraction for Humanitarian Mine Action
Sep 18, 2025Humanitarian Mine Action has generated extensive best-practice knowledge, but much remains locked in unstructured reports. We introduce TextMine, an ontology-guided pipeline that uses Large Language Models to extract knowledge triples from HMA texts. TextMine integrates document chunking, domain-aware prompting, triple extraction, and both reference-based and LLM-as-a-Judge evaluation. We also create the first HMA ontology and a curated dataset of real-world demining reports. Experiments show ontology-aligned prompts boost extraction accuracy by 44.2%, cut hallucinations by 22.5%, and improve format conformance by 20.9% over baselines. While validated on Cambodian reports, TextMine can adapt to global demining efforts or other domains, transforming unstructured data into structured knowledge.
Efficient and Reproducible Biomedical Question Answering using Retrieval Augmented Generation
May 12, 2025



Biomedical question-answering (QA) systems require effective retrieval and generation components to ensure accuracy, efficiency, and scalability. This study systematically examines a Retrieval-Augmented Generation (RAG) system for biomedical QA, evaluating retrieval strategies and response time trade-offs. We first assess state-of-the-art retrieval methods, including BM25, BioBERT, MedCPT, and a hybrid approach, alongside common data stores such as Elasticsearch, MongoDB, and FAISS, on a ~10% subset of PubMed (2.4M documents) to measure indexing efficiency, retrieval latency, and retriever performance in the end-to-end RAG system. Based on these insights, we deploy the final RAG system on the full 24M PubMed corpus, comparing different retrievers' impact on overall performance. Evaluations of the retrieval depth show that retrieving 50 documents with BM25 before reranking with MedCPT optimally balances accuracy (0.90), recall (0.90), and response time (1.91s). BM25 retrieval time remains stable (82ms), while MedCPT incurs the main computational cost. These results highlight previously not well-known trade-offs in retrieval depth, efficiency, and scalability for biomedical QA. With open-source code, the system is fully reproducible and extensible.
Problem Solved? Information Extraction Design Space for Layout-Rich Documents using LLMs
Feb 25, 2025



This paper defines and explores the design space for information extraction (IE) from layout-rich documents using large language models (LLMs). The three core challenges of layout-aware IE with LLMs are 1) data structuring, 2) model engagement, and 3) output refinement. Our study delves into the sub-problems within these core challenges, such as input representation, chunking, prompting, and selection of LLMs and multimodal models. It examines the outcomes of different design choices through a new layout-aware IE test suite, benchmarking against the state-of-art (SoA) model LayoutLMv3. The results show that the configuration from one-factor-at-a-time (OFAT) trial achieves near-optimal results with 14.1 points F1-score gain from the baseline model, while full factorial exploration yields only a slightly higher 15.1 points gain at around 36x greater token usage. We demonstrate that well-configured general-purpose LLMs can match the performance of specialized models, providing a cost-effective alternative. Our test-suite is freely available at https://github.com/gayecolakoglu/LayIE-LLM.
ASAG2024: A Combined Benchmark for Short Answer Grading
Sep 27, 2024Open-ended questions test a more thorough understanding than closed-ended questions and are often a preferred assessment method. However, open-ended questions are tedious to grade and subject to personal bias. Therefore, there have been efforts to speed up the grading process through automation. Short Answer Grading (SAG) systems aim to automatically score students' answers. Despite growth in SAG methods and capabilities, there exists no comprehensive short-answer grading benchmark across different subjects, grading scales, and distributions. Thus, it is hard to assess the capabilities of current automated grading methods in terms of their generalizability. In this preliminary work, we introduce the combined ASAG2024 benchmark to facilitate the comparison of automated grading systems. Combining seven commonly used short-answer grading datasets in a common structure and grading scale. For our benchmark, we evaluate a set of recent SAG methods, revealing that while LLM-based approaches reach new high scores, they still are far from reaching human performance. This opens up avenues for future research on human-machine SAG systems.
Interactive Ontology Matching with Cost-Efficient Learning
Apr 11, 2024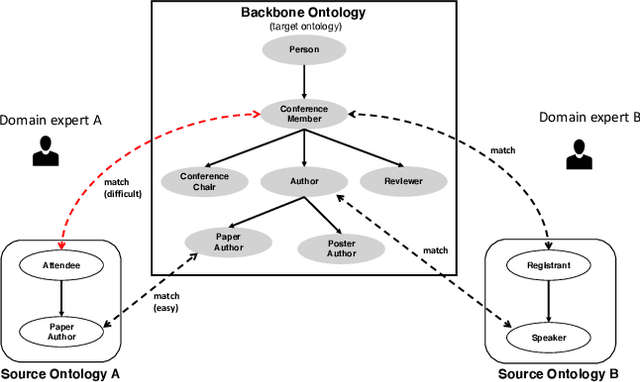
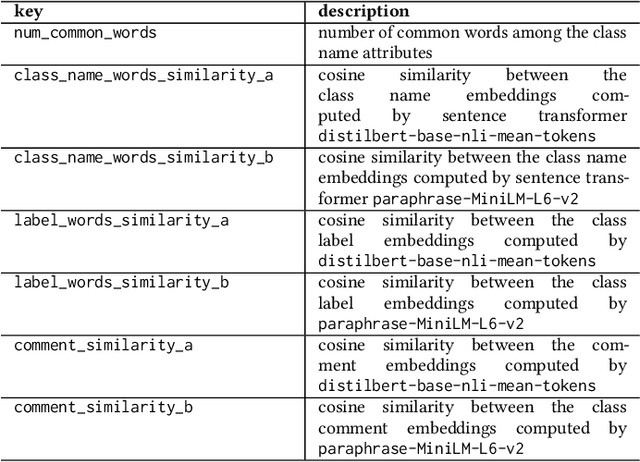
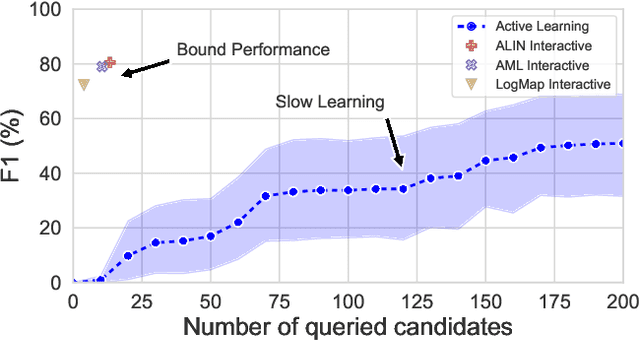
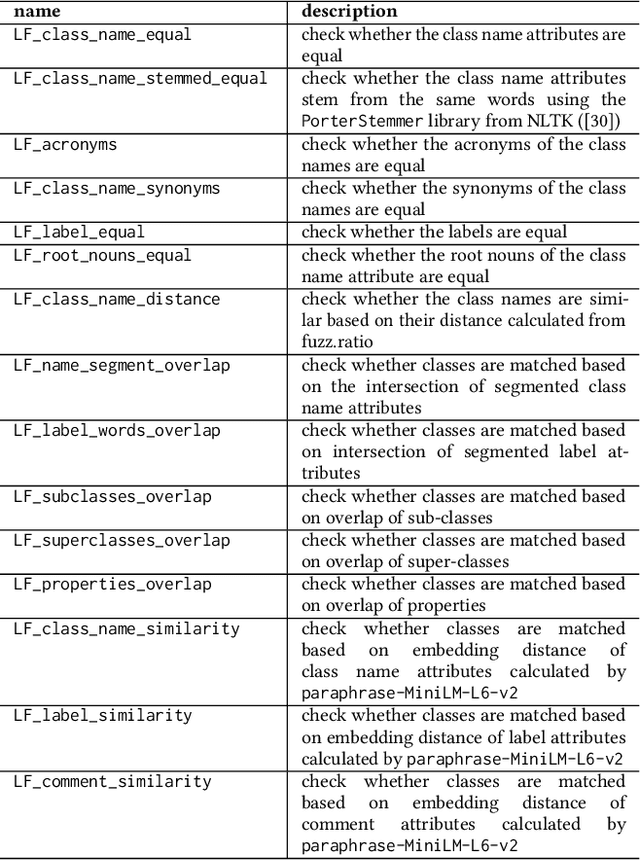
The creation of high-quality ontologies is crucial for data integration and knowledge-based reasoning, specifically in the context of the rising data economy. However, automatic ontology matchers are often bound to the heuristics they are based on, leaving many matches unidentified. Interactive ontology matching systems involving human experts have been introduced, but they do not solve the fundamental issue of flexibly finding additional matches outside the scope of the implemented heuristics, even though this is highly demanded in industrial settings. Active machine learning methods appear to be a promising path towards a flexible interactive ontology matcher. However, off-the-shelf active learning mechanisms suffer from low query efficiency due to extreme class imbalance, resulting in a last-mile problem where high human effort is required to identify the remaining matches. To address the last-mile problem, this work introduces DualLoop, an active learning method tailored to ontology matching. DualLoop offers three main contributions: (1) an ensemble of tunable heuristic matchers, (2) a short-term learner with a novel query strategy adapted to highly imbalanced data, and (3) long-term learners to explore potential matches by creating and tuning new heuristics. We evaluated DualLoop on three datasets of varying sizes and domains. Compared to existing active learning methods, we consistently achieved better F1 scores and recall, reducing the expected query cost spent on finding 90% of all matches by over 50%. Compared to traditional interactive ontology matchers, we are able to find additional, last-mile matches. Finally, we detail the successful deployment of our approach within an actual product and report its operational performance results within the Architecture, Engineering, and Construction (AEC) industry sector, showcasing its practical value and efficiency.
Evaluating the Data Model Robustness of Text-to-SQL Systems Based on Real User Queries
Feb 13, 2024



Text-to-SQL systems (also known as NL-to-SQL systems) have become an increasingly popular solution for bridging the gap between user capabilities and SQL-based data access. These systems translate user requests in natural language to valid SQL statements for a specific database. Recent Text-to-SQL systems have benefited from the rapid improvement of transformer-based language models. However, while Text-to-SQL systems that incorporate such models continuously reach new high scores on -- often synthetic -- benchmark datasets, a systematic exploration of their robustness towards different data models in a real-world, realistic scenario is notably missing. This paper provides the first in-depth evaluation of the data model robustness of Text-to-SQL systems in practice based on a multi-year international project focused on Text-to-SQL interfaces. Our evaluation is based on a real-world deployment of FootballDB, a system that was deployed over a 9 month period in the context of the FIFA World Cup 2022, during which about 6K natural language questions were asked and executed. All of our data is based on real user questions that were asked live to the system. We manually labeled and translated a subset of these questions for three different data models. For each data model, we explore the performance of representative Text-to-SQL systems and language models. We further quantify the impact of training data size, pre-, and post-processing steps as well as language model inference time. Our comprehensive evaluation sheds light on the design choices of real-world Text-to-SQL systems and their impact on moving from research prototypes to real deployments. Last, we provide a new benchmark dataset to the community, which is the first to enable the evaluation of different data models for the same dataset and is substantially more challenging than most previous datasets in terms of query complexity.