 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLM: Unified Decision Language Models for Offline Multi-Agent Sequential Decision Making
Apr 26, 2026Building scalable and reusable multi-agent decision policies from offline datasets remains a challenge in offline multi-agent reinforcement learning (MARL), as existing methods often rely on fixed observation formats and action spaces that limit generalization. In contrast, large language models (LLMs) offer a flexible modeling interface that can naturally accommodate heterogeneous observations and actions. Motivated by this, we propose the Decision Language Model (DLM), which formulates multi-agent decision making as a dialogue-style sequence prediction problem under the centralized training with decentralized execution paradigm. DLM is trained in two stages: a supervised fine-tuning phase, which leverages dialogue-style datasets for centralized training with inter-agent context and generates executable actions from offline trajectories, followed by a group relative policy optimization phase to enhance robustness to out-of-distribution actions through lightweight reward functions. Experiments on multiple benchmarks show that a unified DLM outperforms strong offline MARL baselines and LLM-based conversational decision-making methods, while demonstrating strong zero-shot generalization to unseen scenarios across tasks.
Scalable Quantum Error Mitigation with Neighbor-Informed Learning
Dec 14, 2025Noise in quantum hardware is the primary obstacle to realizing the transformative potential of quantum computing. Quantum error mitigation (QEM) offers a promising pathway to enhance computational accuracy on near-term devices, yet existing methods face a difficult trade-off between performance, resource overhead, and theoretical guarantees. In this work, we introduce neighbor-informed learning (NIL), a versatile and scalable QEM framework that unifies and strengthens existing methods such as zero-noise extrapolation (ZNE) and probabilistic error cancellation (PEC), while offering improved flexibility, accuracy, efficiency, and robustness. NIL learns to predict the ideal output of a target quantum circuit from the noisy outputs of its structurally related ``neighbor'' circuits. A key innovation is our 2-design training method, which generates training data for our machine learning model. In contrast to conventional learning-based QEM protocols that create training circuits by replacing non-Clifford gates with uniformly random Clifford gates, our approach achieves higher accuracy and efficiency, as demonstrated by both theoretical analysis and numerical simulation. Furthermore, we prove that the required size of the training set scales only \emph{logarithmically} with the total number of neighbor circuits, enabling NIL to be applied to problems involving large-scale quantum circuits. Our work establishes a theoretically grounded and practically efficient framework for QEM, paving a viable path toward achieving quantum advantage on noisy hardware.
Multi-Modal Parameter-Efficient Fine-tuning via Graph Neural Network
Aug 01, 2024



With the advent of the era of foundation models, pre-training and fine-tuning have become common paradigms. Recently, parameter-efficient fine-tuning has garnered widespread attention due to its better balance between the number of learnable parameters and performance. However, some current parameter-efficient fine-tuning methods only model a single modality and lack the utilization of structural knowledge in downstream tasks. To address this issue, this paper proposes a multi-modal parameter-efficient fine-tuning method based on graph networks. Each image is fed into a multi-modal large language model (MLLM) to generate a text description. The image and its corresponding text description are then processed by a frozen image encoder and text encoder to generate image features and text features, respectively. A graph is constructed based on the similarity of the multi-modal feature nodes, and knowledge and relationships relevant to these features are extracted from each node. Additionally, Elastic Weight Consolidation (EWC) regularization is incorporated into the loss function to mitigate the problem of forgetting during task learning. The proposed model achieves test accuracies on the OxfordPets, Flowers102, and Food101 datasets that improve by 4.45%, 2.92%, and 0.23%, respectively. The code is available at https://github.com/yunche0/GA-Net/tree/master.
Interactive Ontology Matching with Cost-Efficient Learning
Apr 11, 2024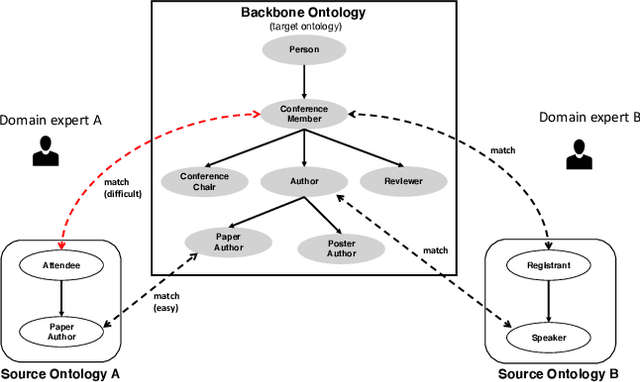
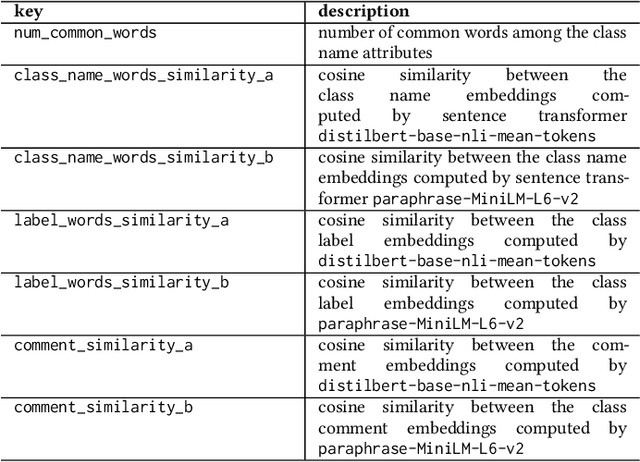
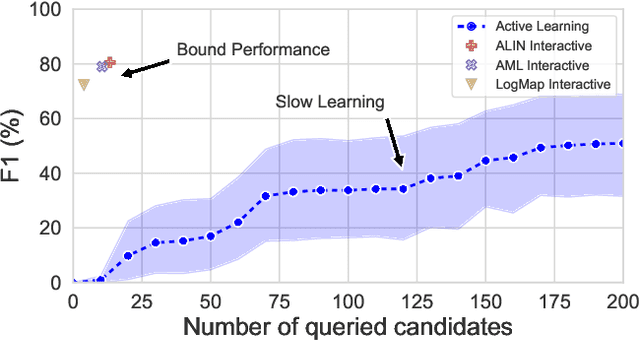
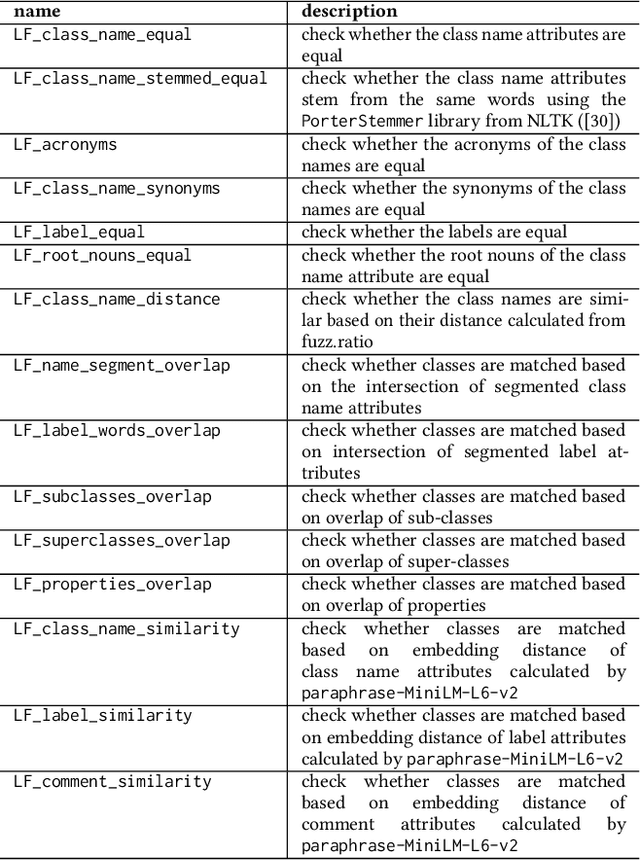
The creation of high-quality ontologies is crucial for data integration and knowledge-based reasoning, specifically in the context of the rising data economy. However, automatic ontology matchers are often bound to the heuristics they are based on, leaving many matches unidentified. Interactive ontology matching systems involving human experts have been introduced, but they do not solve the fundamental issue of flexibly finding additional matches outside the scope of the implemented heuristics, even though this is highly demanded in industrial settings. Active machine learning methods appear to be a promising path towards a flexible interactive ontology matcher. However, off-the-shelf active learning mechanisms suffer from low query efficiency due to extreme class imbalance, resulting in a last-mile problem where high human effort is required to identify the remaining matches. To address the last-mile problem, this work introduces DualLoop, an active learning method tailored to ontology matching. DualLoop offers three main contributions: (1) an ensemble of tunable heuristic matchers, (2) a short-term learner with a novel query strategy adapted to highly imbalanced data, and (3) long-term learners to explore potential matches by creating and tuning new heuristics. We evaluated DualLoop on three datasets of varying sizes and domains. Compared to existing active learning methods, we consistently achieved better F1 scores and recall, reducing the expected query cost spent on finding 90% of all matches by over 50%. Compared to traditional interactive ontology matchers, we are able to find additional, last-mile matches. Finally, we detail the successful deployment of our approach within an actual product and report its operational performance results within the Architecture, Engineering, and Construction (AEC) industry sector, showcasing its practical value and efficiency.
Friends Across Time: Multi-Scale Action Segmentation Transformer for Surgical Phase Recognition
Jan 22, 2024



Automatic surgical phase recognition is a core technology for modern operating rooms and online surgical video assessment platforms. Current state-of-the-art methods use both spatial and temporal information to tackle the surgical phase recognition task. Building on this idea, we propose the Multi-Scale Action Segmentation Transformer (MS-AST) for offline surgical phase recognition and the Multi-Scale Action Segmentation Causal Transformer (MS-ASCT) for online surgical phase recognition. We use ResNet50 or EfficientNetV2-M for spatial feature extraction. Our MS-AST and MS-ASCT can model temporal information at different scales with multi-scale temporal self-attention and multi-scale temporal cross-attention, which enhances the capture of temporal relationships between frames and segments. We demonstrate that our method can achieve 95.26% and 96.15% accuracy on the Cholec80 dataset for online and offline surgical phase recognition, respectively, which achieves new state-of-the-art results. Our method can also achieve state-of-the-art results on non-medical datasets in the video action segmentation domain.
General Image-to-Image Translation with One-Shot Image Guidance
Aug 05, 2023Large-scale text-to-image models pre-trained on massive text-image pairs show excellent performance in image synthesis recently. However, image can provide more intuitive visual concepts than plain text. People may ask: how can we integrate the desired visual concept into an existing image, such as our portrait? Current methods are inadequate in meeting this demand as they lack the ability to preserve content or translate visual concepts effectively. Inspired by this, we propose a novel framework named visual concept translator (VCT) with the ability to preserve content in the source image and translate the visual concepts guided by a single reference image. The proposed VCT contains a content-concept inversion (CCI) process to extract contents and concepts, and a content-concept fusion (CCF) process to gather the extracted information to obtain the target image. Given only one reference image, the proposed VCT can complete a wide range of general image-to-image translation tasks with excellent results. Extensive experiments are conducted to prove the superiority and effectiveness of the proposed methods. Codes are available at https://github.com/CrystalNeuro/visual-concept-translator.
DiscreteCommunication and ControlUpdating in Event-Triggered Consensus
Oct 26, 2022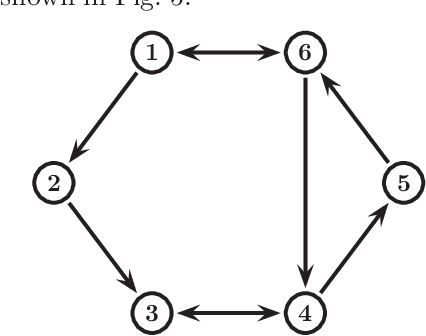
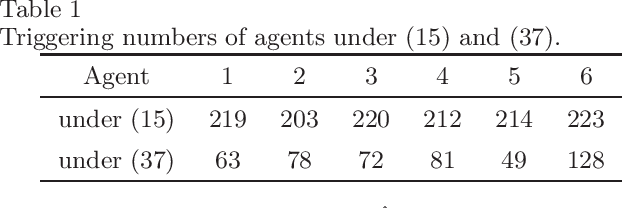
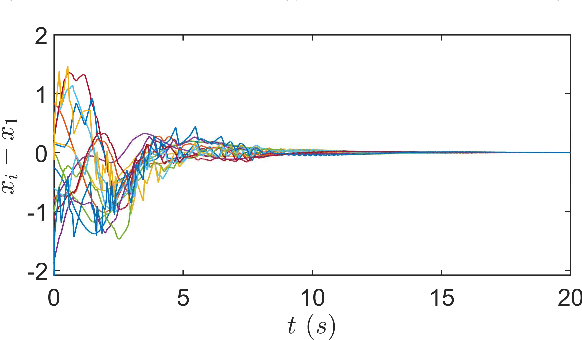
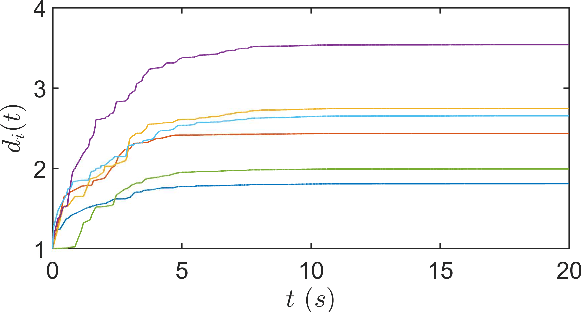
This paper studies the consensus control problem faced with three essential demands, namely, discrete control updating for each agent, discrete-time communications among neighboring agents, and the fully distributed fashion of the controller implementation without requiring any global information of the whole network topology. Noting that the existing related results only meeting one or two demands at most are essentially not applicable, in this paper we establish a novel framework to solve the problem of fully distributed consensus with discrete communication and control. The first key point in this framework is the design of controllers that are only updated at discrete event instants and do not depend on global information by introducing time-varying gains inspired by the adaptive control technique. Another key point is the invention of novel dynamic triggering functions that are independent of relative information among neighboring agents. Under the established framework, we propose fully distributed state-feedback event-triggered protocols for undirected graphs and also further study the more complexed cases of output-feedback control and directed graphs. Finally, numerical examples are provided to verify the effectiveness of the proposed event-triggered protocols.
$S^3$Net: Semantic-Aware Self-supervised Depth Estimation with Monocular Videos and Synthetic Data
Jul 28, 2020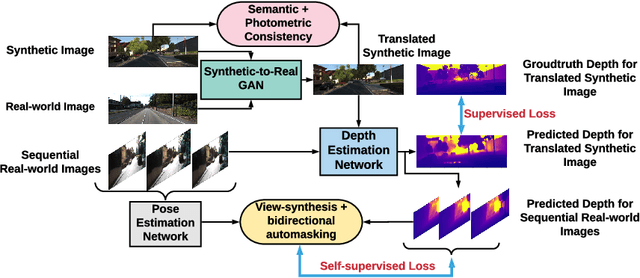
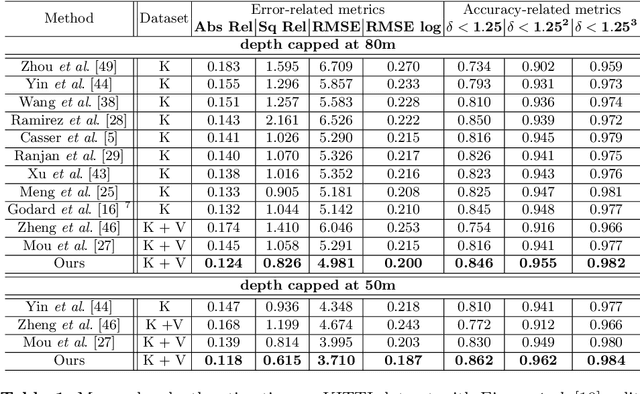
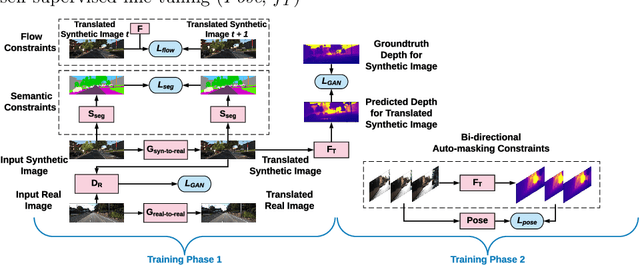
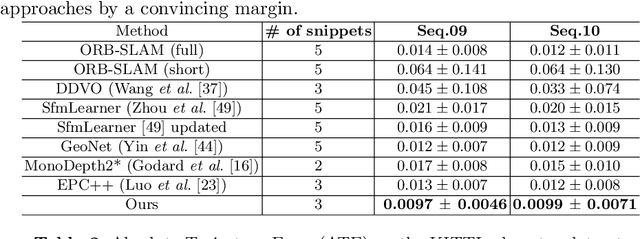
Solving depth estimation with monocular cameras enables the possibility of widespread use of cameras as low-cost depth estimation sensors in applications such as autonomous driving and robotics. However, learning such a scalable depth estimation model would require a lot of labeled data which is expensive to collect. There are two popular existing approaches which do not require annotated depth maps: (i) using labeled synthetic and unlabeled real data in an adversarial framework to predict more accurate depth, and (ii) unsupervised models which exploit geometric structure across space and time in monocular video frames. Ideally, we would like to leverage features provided by both approaches as they complement each other; however, existing methods do not adequately exploit these additive benefits. We present $S^3$Net, a self-supervised framework which combines these complementary features: we use synthetic and real-world images for training while exploiting geometric, temporal, as well as semantic constraints. Our novel consolidated architecture provides a new state-of-the-art in self-supervised depth estimation using monocular videos. We present a unique way to train this self-supervised framework, and achieve (i) more than $15\%$ improvement over previous synthetic supervised approaches that use domain adaptation and (ii) more than $10\%$ improvement over previous self-supervised approaches which exploit geometric constraints from the real data.