 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAP3D: NeRF Assisted 3D-3D Pose Alignment for Autonomous Vehicles
Dec 17, 2025Accurate localization is essential for autonomous vehicles, yet sensor noise and drift over time can lead to significant pose estimation errors, particularly in long-horizon environments. A common strategy for correcting accumulated error is visual loop closure in SLAM, which adjusts the pose graph when the agent revisits previously mapped locations. These techniques typically rely on identifying visual mappings between the current view and previously observed scenes and often require fusing data from multiple sensors. In contrast, this work introduces NeRF-Assisted 3D-3D Pose Alignment (NAP3D), a complementary approach that leverages 3D-3D correspondences between the agent's current depth image and a pre-trained Neural Radiance Field (NeRF). By directly aligning 3D points from the observed scene with synthesized points from the NeRF, NAP3D refines the estimated pose even from novel viewpoints, without relying on revisiting previously observed locations. This robust 3D-3D formulation provides advantages over conventional 2D-3D localization methods while remaining comparable in accuracy and applicability. Experiments demonstrate that NAP3D achieves camera pose correction within 5 cm on a custom dataset, robustly outperforming a 2D-3D Perspective-N-Point baseline. On TUM RGB-D, NAP3D consistently improves 3D alignment RMSE by approximately 6 cm compared to this baseline given varying noise, despite PnP achieving lower raw rotation and translation parameter error in some regimes, highlighting NAP3D's improved geometric consistency in 3D space. By providing a lightweight, dataset-agnostic tool, NAP3D complements existing SLAM and localization pipelines when traditional loop closure is unavailable.
$S^3$Net: Semantic-Aware Self-supervised Depth Estimation with Monocular Videos and Synthetic Data
Jul 28, 2020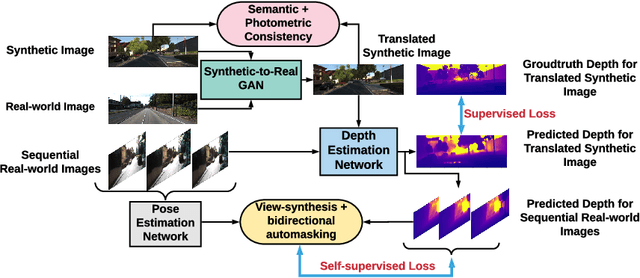
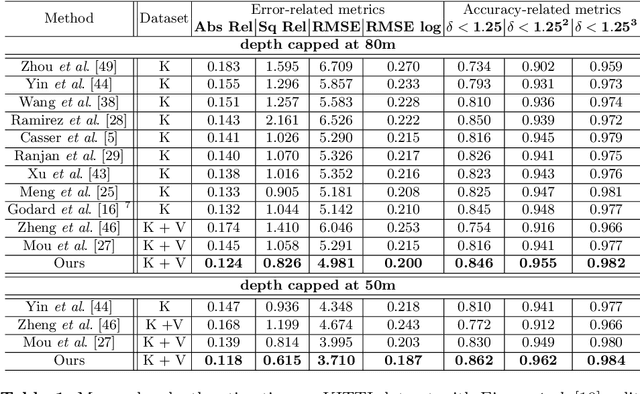
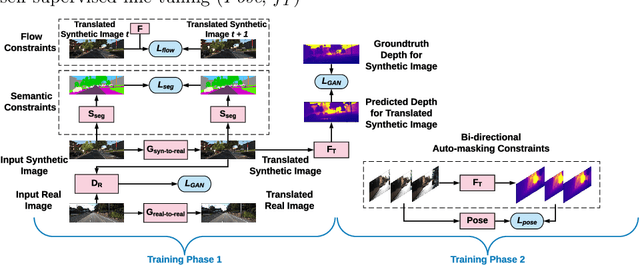
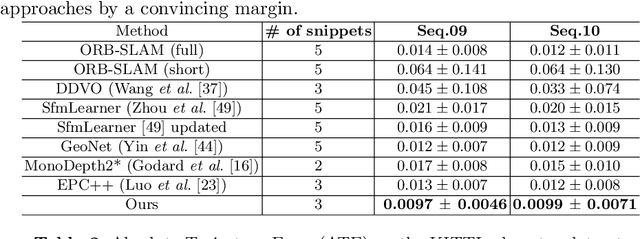
Solving depth estimation with monocular cameras enables the possibility of widespread use of cameras as low-cost depth estimation sensors in applications such as autonomous driving and robotics. However, learning such a scalable depth estimation model would require a lot of labeled data which is expensive to collect. There are two popular existing approaches which do not require annotated depth maps: (i) using labeled synthetic and unlabeled real data in an adversarial framework to predict more accurate depth, and (ii) unsupervised models which exploit geometric structure across space and time in monocular video frames. Ideally, we would like to leverage features provided by both approaches as they complement each other; however, existing methods do not adequately exploit these additive benefits. We present $S^3$Net, a self-supervised framework which combines these complementary features: we use synthetic and real-world images for training while exploiting geometric, temporal, as well as semantic constraints. Our novel consolidated architecture provides a new state-of-the-art in self-supervised depth estimation using monocular videos. We present a unique way to train this self-supervised framework, and achieve (i) more than $15\%$ improvement over previous synthetic supervised approaches that use domain adaptation and (ii) more than $10\%$ improvement over previous self-supervised approaches which exploit geometric constraints from the real data.
SIGNet: Semantic Instance Aided Unsupervised 3D Geometry Perception
Dec 13, 2018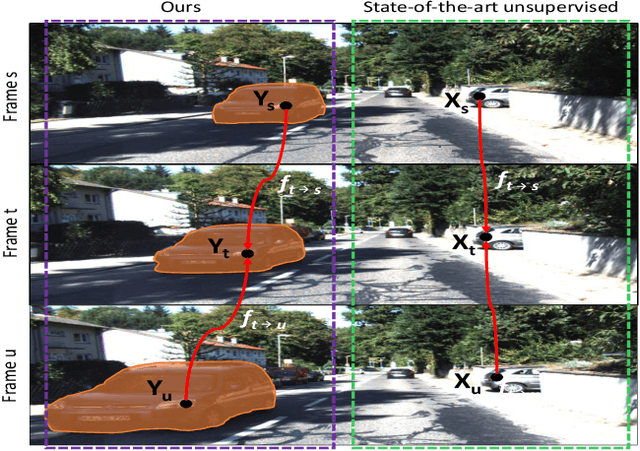
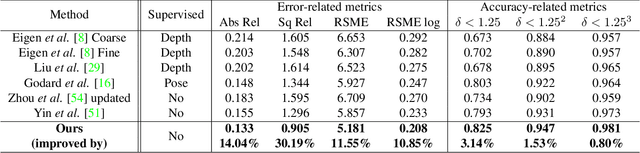
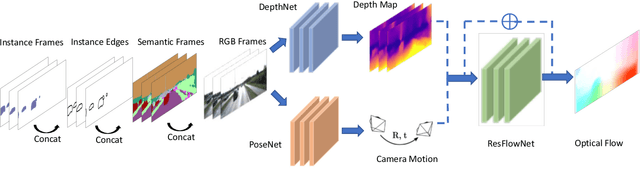
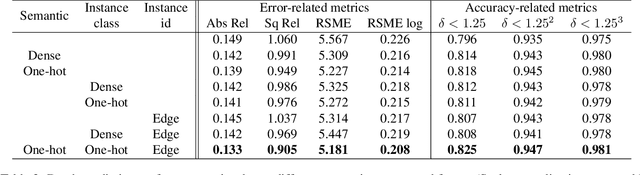
Unsupervised learning for visual perception of 3D geometry is of great interest to autonomous systems. Recent works on unsupervised learning have made considerable progress on geometry perception; however, they perform poorly on dynamic objects and scenarios with dark and noisy environments. In contrast, supervised learning algorithms, which are robust, require large labeled geometric data-set. This paper introduces SIGNet, a novel framework that provides robust geometry perception without requiring geometrically informative labels. Specifically, SIGNet integrates semantic information to make unsupervised robust geometric predictions for dynamic objects in low lighting and noisy environments. SIGNet is shown to improve upon the state of art unsupervised learning for geometry perception by 30% (in squared relative error for depth prediction). In particular, SIGNet improves the dynamic object class performance by 39% in depth prediction and 29% in flow prediction.