 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and Generative AI Transforming Disaster Management: A Survey of Damage Assessment and Response Techniques
May 13, 2025
Natural disasters, including earthquakes, wildfires and cyclones, bear a huge risk on human lives as well as infrastructure assets. An effective response to disaster depends on the ability to rapidly and efficiently assess the intensity of damage. Artificial Intelligence (AI) and Generative Artificial Intelligence (GenAI) presents a breakthrough solution, capable of combining knowledge from multiple types and sources of data, simulating realistic scenarios of disaster, and identifying emerging trends at a speed previously unimaginable. In this paper, we present a comprehensive review on the prospects of AI and GenAI in damage assessment for various natural disasters, highlighting both its strengths and limitations. We talk about its application to multimodal data such as text, image, video, and audio, and also cover major issues of data privacy, security, and ethical use of the technology during crises. The paper also recognizes the threat of Generative AI misuse, in the form of dissemination of misinformation and for adversarial attacks. Finally, we outline avenues of future research, emphasizing the need for secure, reliable, and ethical Generative AI systems for disaster management in general. We believe that this work represents the first comprehensive survey of Gen-AI techniques being used in the field of Disaster Assessment and Response.
Adversarial Attacks in Multimodal Systems: A Practitioner's Survey
May 06, 2025The introduction of multimodal models is a huge step forward in Artificial Intelligence. A single model is trained to understand multiple modalities: text, image, video, and audio. Open-source multimodal models have made these breakthroughs more accessible. However, considering the vast landscape of adversarial attacks across these modalities, these models also inherit vulnerabilities of all the modalities, and ultimately, the adversarial threat amplifies. While broad research is available on possible attacks within or across these modalities, a practitioner-focused view that outlines attack types remains absent in the multimodal world. As more Machine Learning Practitioners adopt, fine-tune, and deploy open-source models in real-world applications, it's crucial that they can view the threat landscape and take the preventive actions necessary. This paper addresses the gap by surveying adversarial attacks targeting all four modalities: text, image, video, and audio. This survey provides a view of the adversarial attack landscape and presents how multimodal adversarial threats have evolved. To the best of our knowledge, this survey is the first comprehensive summarization of the threat landscape in the multimodal world.
Optimizing LLMs for Resource-Constrained Environments: A Survey of Model Compression Techniques
May 05, 2025Large Language Models (LLMs) have revolutionized many areas of artificial intelligence (AI), but their substantial resource requirements limit their deployment on mobile and edge devices. This survey paper provides a comprehensive overview of techniques for compressing LLMs to enable efficient inference in resource-constrained environments. We examine three primary approaches: Knowledge Distillation, Model Quantization, and Model Pruning. For each technique, we discuss the underlying principles, present different variants, and provide examples of successful applications. We also briefly discuss complementary techniques such as mixture-of-experts and early-exit strategies. Finally, we highlight promising future directions, aiming to provide a valuable resource for both researchers and practitioners seeking to optimize LLMs for edge deployment.
SIGNet: Semantic Instance Aided Unsupervised 3D Geometry Perception
Dec 13, 2018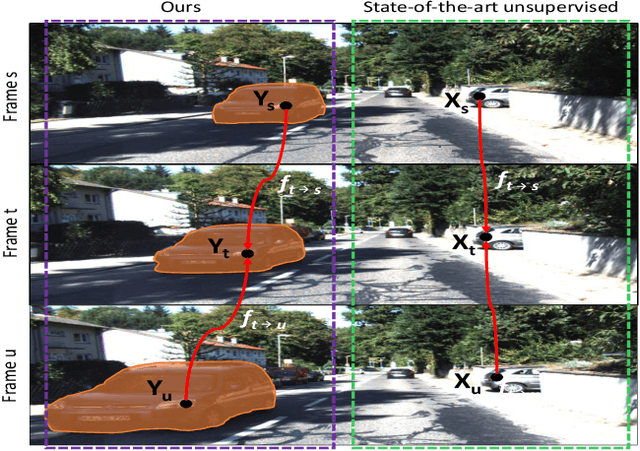
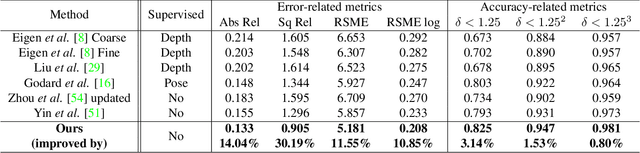
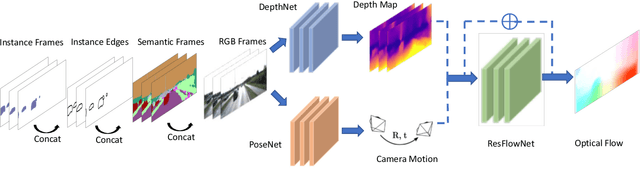
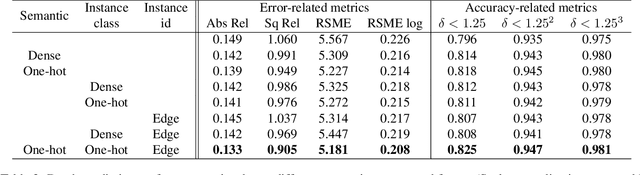
Unsupervised learning for visual perception of 3D geometry is of great interest to autonomous systems. Recent works on unsupervised learning have made considerable progress on geometry perception; however, they perform poorly on dynamic objects and scenarios with dark and noisy environments. In contrast, supervised learning algorithms, which are robust, require large labeled geometric data-set. This paper introduces SIGNet, a novel framework that provides robust geometry perception without requiring geometrically informative labels. Specifically, SIGNet integrates semantic information to make unsupervised robust geometric predictions for dynamic objects in low lighting and noisy environments. SIGNet is shown to improve upon the state of art unsupervised learning for geometry perception by 30% (in squared relative error for depth prediction). In particular, SIGNet improves the dynamic object class performance by 39% in depth prediction and 29% in flow prediction.