 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGNet: Semantic Instance Aided Unsupervised 3D Geometry Perception
Paper and Code
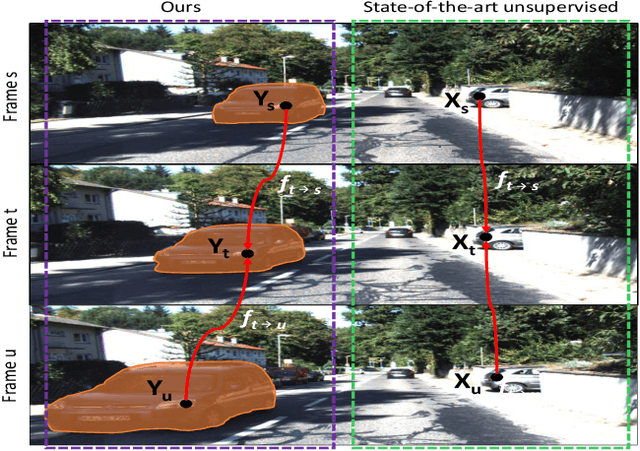
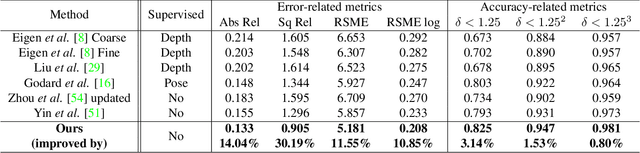
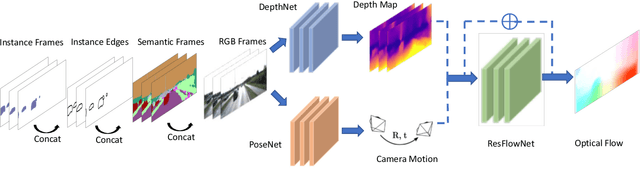
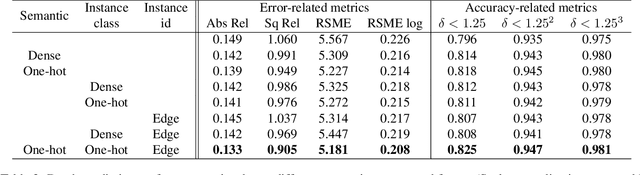
Unsupervised learning for visual perception of 3D geometry is of great interest to autonomous systems. Recent works on unsupervised learning have made considerable progress on geometry perception; however, they perform poorly on dynamic objects and scenarios with dark and noisy environments. In contrast, supervised learning algorithms, which are robust, require large labeled geometric data-set. This paper introduces SIGNet, a novel framework that provides robust geometry perception without requiring geometrically informative labels. Specifically, SIGNet integrates semantic information to make unsupervised robust geometric predictions for dynamic objects in low lighting and noisy environments. SIGNet is shown to improve upon the state of art unsupervised learning for geometry perception by 30% (in squared relative error for depth prediction). In particular, SIGNet improves the dynamic object class performance by 39% in depth prediction and 29% in flow prediction.