 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling
May 24, 2026Physical world knowledge resides mainly in videos. Equipping Vision-Language-Action (VLA) models with such knowledge is fundamental for safe and generalizable planning. Predictive world modeling enables VLA to internalize physical dynamics and long-term causality by predicting future video from past observations. However, naive next-frame prediction faces two challenges: 1) unlike semantically distinct text tokens, video tokens are low-entropy and redundant, causing prediction to degenerate into trivial extrapolation. 2) world modeling poses a temporal dilemma: dense prediction captures instantaneous dynamics, but cannot efficiently model long-horizon causality. To learn world knowledge effectively, we introduce X-Foresight, a predictive world model integrated directly into the VLA architecture to jointly learn world modeling and real-time action control. At its core lies a long-horizon chunk-wise auto-regressive strategy that addresses both challenges: by predicting semantically distant chunks rather than adjacent frames, it escapes trivial extrapolation, while preserving dense intra-chunk frames for instantaneous dynamics and sparse inter-chunk transitions for long-term causality. A curriculum learning schedule progressively extends prediction horizons and stabilizes long-horizon training. To capture long-term causality effectively, we present temporal importance sampling, which concentrates supervision on safety-critical chunks identified by ego-motion and behavioral signals. We further delegate photorealistic synthesis to a diffusion-based multi-view renderer, improving photorealistic appearance. Comprehensive experiments demonstrate that X-Foresight significantly outperforms VLA baselines in planning performance while maintaining strong generative fidelity, establishing a robust paradigm for world-knowledge-driven autonomous systems.
IP-SAM: Prompt-Space Conditioning for Prompt-Absent Camouflaged Object Detection
Mar 28, 2026Prompt-conditioned foundation segmenters have emerged as a dominant paradigm for image segmentation, where explicit spatial prompts (e.g., points, boxes, masks) guide mask decoding. However, many real-world deployments require fully automatic segmentation, creating a structural mismatch: the decoder expects prompts that are unavailable at inference. Existing adaptations typically modify intermediate features, inadvertently bypassing the model's native prompt interface and weakening prompt-conditioned decoding. We propose IP-SAM, which revisits adaptation from a prompt-space perspective through prompt-space conditioning. Specifically, a Self-Prompt Generator (SPG) distills image context into complementary intrinsic prompts that serve as coarse regional anchors. These cues are projected through SAM2's frozen prompt encoder, restoring prompt-guided decoding without external intervention. To suppress background-induced false positives, Prompt-Space Gating (PSG) leverages the intrinsic background prompt as an asymmetric suppressive constraint prior to decoding. Under a deterministic no-external-prompt protocol, IP-SAM achieves state-of-the-art performance across four camouflaged object detection benchmarks (e.g., MAE 0.017 on COD10K) with only 21.26M trainable parameters (optimizing SPG, PSG, and a task-specific mask decoder trained from scratch, alongside image-encoder LoRA while keeping the prompt encoder frozen). Furthermore, the proposed conditioning strategy generalizes beyond COD to medical polyp segmentation, where a model trained solely on Kvasir-SEG exhibits strong zero-shot transfer to both CVC-ClinicDB and ETIS.
Physics Informed Deep Unfolded Full Waveform Inversion for Edema Detection
Mar 04, 2026Edema is a potential indicator of underlying pathological changes. However, its low-contrast signature is often masked in conventional B-mode imaging by strong scatterers, making reliable detection challenging. Ultrasound (US) provides a non-invasive, non-ionizing, and cost-efficient imaging option that is widely used. Conventional techniques, which rely on beamforming, often lack sufficient physical interpretability. Quantitative US (QUS) can estimate physical properties such as the speed of sound (SoS) and density by solving a physics-based inverse problem directly on the measured US wavefields, i.e., the raw per-element channel data (CD), to recover their spatial distribution. However, state-of-the-art physics-based inversion methods, including full waveform inversion (FWI) and model-based quantitative radar and US (MB-QRUS), are computationally intensive and susceptible to local minima, which constrains their clinical utility. We introduce deep unfolded FWI (DUFWI), a physics-faithful unfolded iterative inversion method that exhibits FWI-like refinement behavior while learning the update rule from data, requiring only a small number of iterations for real-time SoS reconstruction. Across both simulated datasets and hardware measurements acquired with a Verasonics US system, the DUFWI significantly outperforms classical FWI and MB-QRUS in reconstruction quality while maintaining high computational efficiency. These results demonstrate real-time edema diagnosis in both simulation and hardware experiments, with phantom-based validation using cylindrical rods, supporting practical deployment under typical US imaging setting.
Bayesian Signal Component Decomposition via Diffusion-within-Gibbs Sampling
Feb 11, 2026In signal processing, the data collected from sensing devices is often a noisy linear superposition of multiple components, and the estimation of components of interest constitutes a crucial pre-processing step. In this work, we develop a Bayesian framework for signal component decomposition, which combines Gibbs sampling with plug-and-play (PnP) diffusion priors to draw component samples from the posterior distribution. Unlike many existing methods, our framework supports incorporating model-driven and data-driven prior knowledge into the diffusion prior in a unified manner. Moreover, the proposed posterior sampler allows component priors to be learned separately and flexibly combined without retraining. Under suitable assumptions, the proposed DiG sampler provably produces samples from the posterior distribution. We also show that DiG can be interpreted as an extension of a class of recently proposed diffusion-based samplers, and that, for suitable classes of sensing operators, DiG better exploits the structure of the measurement model. Numerical experiments demonstrate the superior performance of our method over existing approaches.
Feature-based Inversion of 2.5D Controlled Source Electromagnetic Data using Generative Priors
Jan 05, 2026In this study, we investigate feature-based 2.5D controlled source marine electromagnetic (mCSEM) data inversion using generative priors. Two-and-half dimensional modeling using finite difference method (FDM) is adopted to compute the response of horizontal electric dipole (HED) excitation. Rather than using a neural network to approximate the entire inverse mapping in a black-box manner, we adopt a plug-andplay strategy in which a variational autoencoder (VAE) is used solely to learn prior information on conductivity distributions. During the inversion process, the conductivity model is iteratively updated using the Gauss Newton method, while the model space is constrained by projections onto the learned VAE decoder. This framework preserves explicit control over data misfit and enables flexible adaptation to different survey configurations. Numerical and field experiments demonstrate that the proposed approach effectively incorporates prior information, improves reconstruction accuracy, and exhibits good generalization performance.
Bayesian Signal Separation via Plug-and-Play Diffusion-Within-Gibbs Sampling
Sep 16, 2025We propose a posterior sampling algorithm for the problem of estimating multiple independent source signals from their noisy superposition. The proposed algorithm is a combination of Gibbs sampling method and plug-and-play (PnP) diffusion priors. Unlike most existing diffusion-model-based approaches for signal separation, our method allows source priors to be learned separately and flexibly combined without retraining. Moreover, under the assumption of perfect diffusion model training, the proposed method provably produces samples from the posterior distribution. Experiments on the task of heartbeat extraction from mixtures with synthetic motion artifacts demonstrate the superior performance of our method over existing approaches.
Plug-and-Play Latent Diffusion for Electromagnetic Inverse Scattering with Application to Brain Imaging
Sep 05, 2025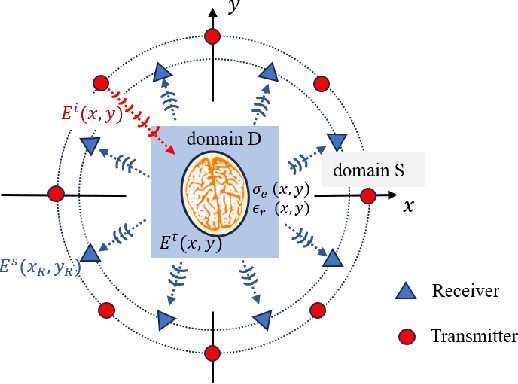
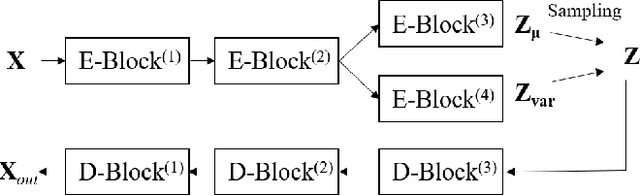
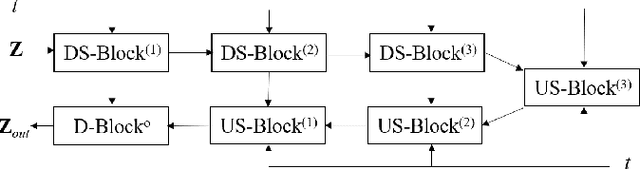
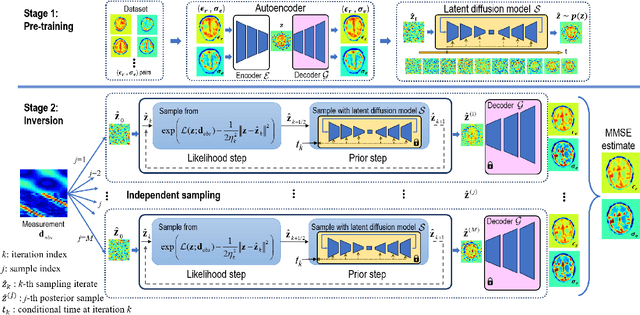
Electromagnetic (EM) imaging is an important tool for non-invasive sensing with low-cost and portable devices. One emerging application is EM stroke imaging, which enables early diagnosis and continuous monitoring of brain strokes. Quantitative imaging is achieved by solving an inverse scattering problem (ISP) that reconstructs permittivity and conductivity maps from measurements. In general, the reconstruction accuracy is limited by its inherent nonlinearity and ill-posedness. Existing methods, including learning-free and learning-based approaches, fail to either incorporate complicated prior distributions or provide theoretical guarantees, posing difficulties in balancing interpretability, distortion error, and reliability. To overcome these limitations, we propose a posterior sampling method based on latent diffusion for quantitative EM brain imaging, adapted from a generative plug-and-play (PnP) posterior sampling framework. Our approach allows to flexibly integrate prior knowledge into physics-based inversion without requiring paired measurement-label datasets. We first learn the prior distribution of targets from an unlabeled dataset, and then incorporate the learned prior into posterior sampling. In particular, we train a latent diffusion model on permittivity and conductivity maps to capture their prior distribution. Then, given measurements and the forward model describing EM wave physics, we perform posterior sampling by alternating between two samplers that respectively enforce the likelihood and prior distributions. Finally, reliable reconstruction is obtained through minimum mean squared error (MMSE) estimation based on the samples. Experimental results on brain imaging demonstrate that our approach achieves state-of-the-art performance in reconstruction accuracy and structural similarity while maintaining high measurement fidelity.
UNO: Unified Self-Supervised Monocular Odometry for Platform-Agnostic Deployment
Jun 08, 2025This work presents UNO, a unified monocular visual odometry framework that enables robust and adaptable pose estimation across diverse environments, platforms, and motion patterns. Unlike traditional methods that rely on deployment-specific tuning or predefined motion priors, our approach generalizes effectively across a wide range of real-world scenarios, including autonomous vehicles, aerial drones, mobile robots, and handheld devices. To this end, we introduce a Mixture-of-Experts strategy for local state estimation, with several specialized decoders that each handle a distinct class of ego-motion patterns. Moreover, we introduce a fully differentiable Gumbel-Softmax module that constructs a robust inter-frame correlation graph, selects the optimal expert decoder, and prunes erroneous estimates. These cues are then fed into a unified back-end that combines pre-trained, scale-independent depth priors with a lightweight bundling adjustment to enforce geometric consistency. We extensively evaluate our method on three major benchmark datasets: KITTI (outdoor/autonomous driving), EuRoC-MAV (indoor/aerial drones), and TUM-RGBD (indoor/handheld), demonstrating state-of-the-art performance.
LiDAR-based Quadrotor for Slope Inspection in Dense Vegetation
Sep 21, 2024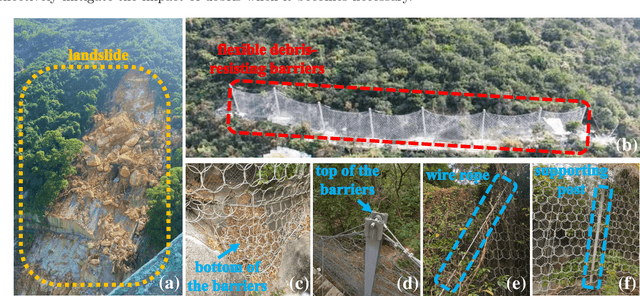
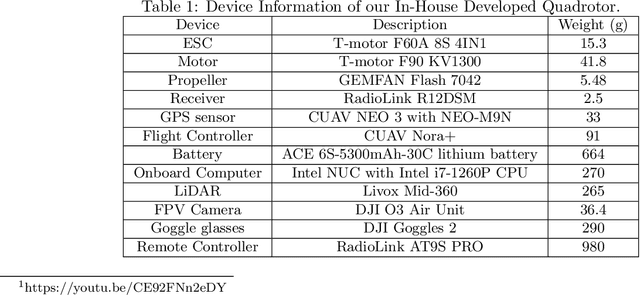


This work presents a LiDAR-based quadrotor system for slope inspection in dense vegetation environments. Cities like Hong Kong are vulnerable to climate hazards, which often result in landslides. To mitigate the landslide risks, the Civil Engineering and Development Department (CEDD) has constructed steel flexible debris-resisting barriers on vulnerable natural catchments to protect residents. However, it is necessary to carry out regular inspections to identify any anomalies, which may affect the proper functioning of the barriers. Traditional manual inspection methods face challenges and high costs due to steep terrain and dense vegetation. Compared to manual inspection, unmanned aerial vehicles (UAVs) equipped with LiDAR sensors and cameras have advantages such as maneuverability in complex terrain, and access to narrow areas and high spots. However, conducting slope inspections using UAVs in dense vegetation poses significant challenges. First, in terms of hardware, the overall design of the UAV must carefully consider its maneuverability in narrow spaces, flight time, and the types of onboard sensors required for effective inspection. Second, regarding software, navigation algorithms need to be designed to enable obstacle avoidance flight in dense vegetation environments. To overcome these challenges, we develop a LiDAR-based quadrotor, accompanied by a comprehensive software system. The goal is to deploy our quadrotor in field environments to achieve efficient slope inspection. To assess the feasibility of our hardware and software system, we conduct functional tests in non-operational scenarios. Subsequently, invited by CEDD, we deploy our quadrotor in six field environments, including five flexible debris-resisting barriers located in dense vegetation and one slope that experienced a landslide. These experiments demonstrated the superiority of our quadrotor in slope inspection.
QUB-Cirdan at "Discharge Me!": Zero shot discharge letter generation by open-source LLM
May 27, 2024
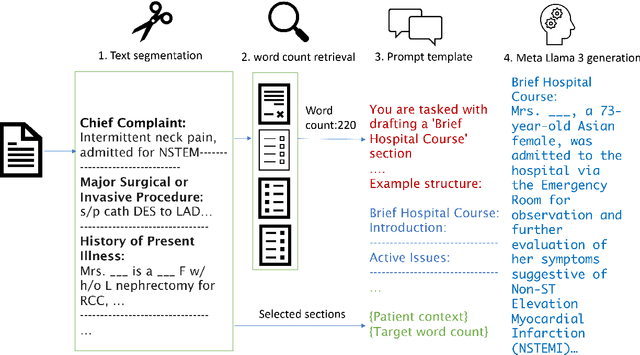

The BioNLP ACL'24 Shared Task on Streamlining Discharge Documentation aims to reduce the administrative burden on clinicians by automating the creation of critical sections of patient discharge letters. This paper presents our approach using the Llama3 8B quantized model to generate the "Brief Hospital Course" and "Discharge Instructions" sections. We employ a zero-shot method combined with Retrieval-Augmented Generation (RAG) to produce concise, contextually accurate summaries. Our contributions include the development of a curated template-based approach to ensure reliability and consistency, as well as the integration of RAG for word count prediction. We also describe several unsuccessful experiments to provide insights into our pathway for the competition. Our results demonstrate the effectiveness and efficiency of our approach, achieving high scores across multiple evaluation metrics.