 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnLearning from Experience to Avoid Spurious Correlations
Sep 04, 2024



While deep neural networks can achieve state-of-the-art performance in many tasks, these models are more fragile than they appear. They are prone to learning spurious correlations in their training data, leading to surprising failure cases. In this paper, we propose a new approach that addresses the issue of spurious correlations: UnLearning from Experience (ULE). Our method is based on using two classification models trained in parallel: student and teacher models. Both models receive the same batches of training data. The student model is trained with no constraints and pursues the spurious correlations in the data. The teacher model is trained to solve the same classification problem while avoiding the mistakes of the student model. As training is done in parallel, the better the student model learns the spurious correlations, the more robust the teacher model becomes. The teacher model uses the gradient of the student's output with respect to its input to unlearn mistakes made by the student. We show that our method is effective on the Waterbirds, CelebA, Spawrious and UrbanCars datasets.
QUB-Cirdan at "Discharge Me!": Zero shot discharge letter generation by open-source LLM
May 27, 2024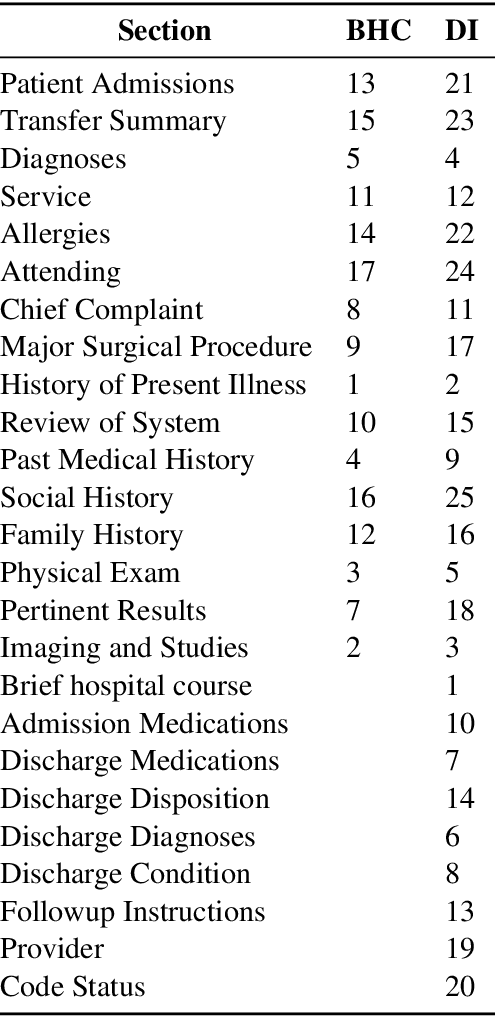
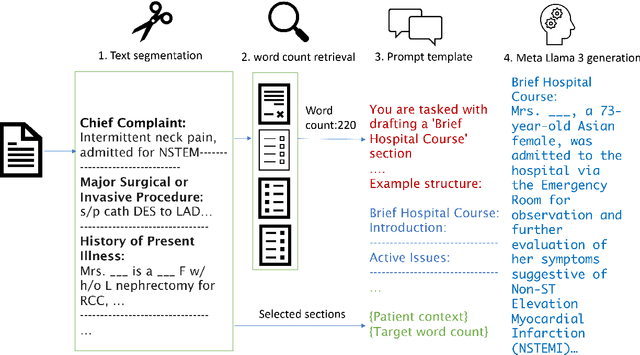
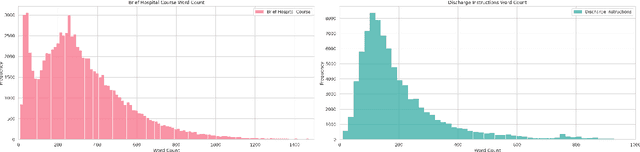

The BioNLP ACL'24 Shared Task on Streamlining Discharge Documentation aims to reduce the administrative burden on clinicians by automating the creation of critical sections of patient discharge letters. This paper presents our approach using the Llama3 8B quantized model to generate the "Brief Hospital Course" and "Discharge Instructions" sections. We employ a zero-shot method combined with Retrieval-Augmented Generation (RAG) to produce concise, contextually accurate summaries. Our contributions include the development of a curated template-based approach to ensure reliability and consistency, as well as the integration of RAG for word count prediction. We also describe several unsuccessful experiments to provide insights into our pathway for the competition. Our results demonstrate the effectiveness and efficiency of our approach, achieving high scores across multiple evaluation metrics.
Hard-label based Small Query Black-box Adversarial Attack
Mar 09, 2024We consider the hard label based black box adversarial attack setting which solely observes predicted classes from the target model. Most of the attack methods in this setting suffer from impractical number of queries required to achieve a successful attack. One approach to tackle this drawback is utilising the adversarial transferability between white box surrogate models and black box target model. However, the majority of the methods adopting this approach are soft label based to take the full advantage of zeroth order optimisation. Unlike mainstream methods, we propose a new practical setting of hard label based attack with an optimisation process guided by a pretrained surrogate model. Experiments show the proposed method significantly improves the query efficiency of the hard label based black-box attack across various target model architectures. We find the proposed method achieves approximately 5 times higher attack success rate compared to the benchmarks, especially at the small query budgets as 100 and 250.
* 11 pages, 3 figures
Malceiver: Perceiver with Hierarchical and Multi-modal Features for Android Malware Detection
Apr 12, 2022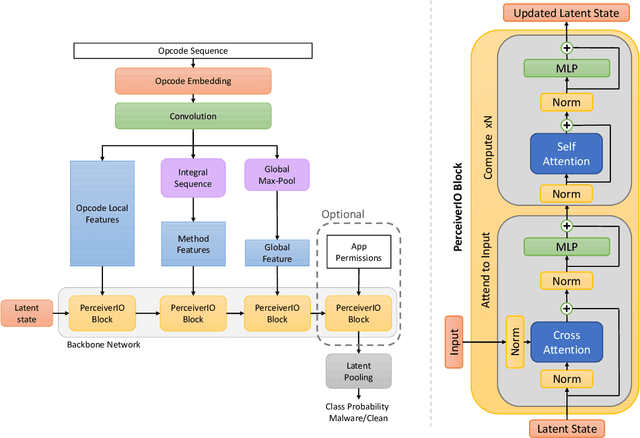



We propose the Malceiver, a hierarchical Perceiver model for Android malware detection that makes use of multi-modal features. The primary inputs are the opcode sequence and the requested permissions of a given Android APK file. To reach a malware classification decision the model combines hierarchical features extracted from the opcode sequence together with the requested permissions. The model's architecture is based on the Perceiver/PerceiverIO which allows for very long opcode sequences to be processed efficiently. Our proposed model can be easily extended to use multi-modal features. We show experimentally that this model outperforms a conventional CNN architecture for opcode sequence based malware detection. We then show that using additional modalities improves performance. Our proposed architecture opens new avenues for the use of Transformer-style networks in malware research.
Data Augmentation for Opcode Sequence Based Malware Detection
Jun 22, 2021

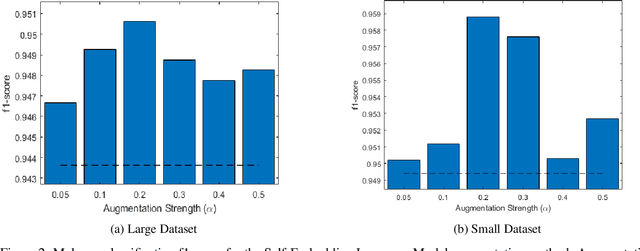
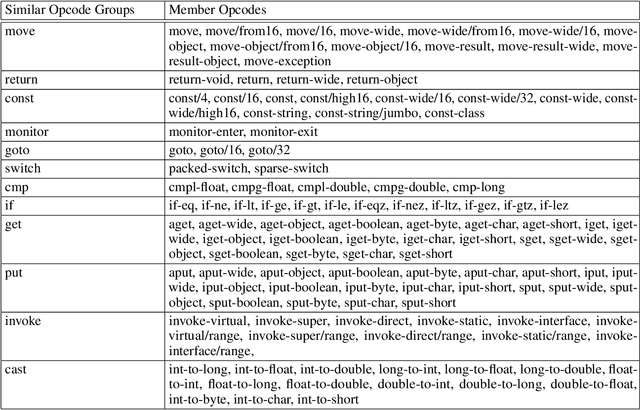
Data augmentation has been successfully used in many areas of deep-learning to significantly improve model performance. Typically data augmentation simulates realistic variations in data in order to increase the apparent diversity of the training-set. However, for opcode-based malware analysis, where deep learning methods are already achieving state of the art performance, it is not immediately clear how to apply data augmentation. In this paper we study different methods of data augmentation starting with basic methods using fixed transformations and moving to methods that adapt to the data. We propose a novel data augmentation method based on using an opcode embedding layer within the network and its corresponding opcode embedding matrix to perform adaptive data augmentation during training. To the best of our knowledge this is the first paper to carry out a systematic study of different augmentation methods applied to opcode sequence based malware classification.