 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudies with impossible languages falsify LMs as models of human language
Nov 14, 2025According to Futrell and Mahowald [arXiv:2501.17047], both infants and language models (LMs) find attested languages easier to learn than impossible languages that have unnatural structures. We review the literature and show that LMs often learn attested and many impossible languages equally well. Difficult to learn impossible languages are simply more complex (or random). LMs are missing human inductive biases that support language acquisition.
UnLearning from Experience to Avoid Spurious Correlations
Sep 04, 2024



While deep neural networks can achieve state-of-the-art performance in many tasks, these models are more fragile than they appear. They are prone to learning spurious correlations in their training data, leading to surprising failure cases. In this paper, we propose a new approach that addresses the issue of spurious correlations: UnLearning from Experience (ULE). Our method is based on using two classification models trained in parallel: student and teacher models. Both models receive the same batches of training data. The student model is trained with no constraints and pursues the spurious correlations in the data. The teacher model is trained to solve the same classification problem while avoiding the mistakes of the student model. As training is done in parallel, the better the student model learns the spurious correlations, the more robust the teacher model becomes. The teacher model uses the gradient of the student's output with respect to its input to unlearn mistakes made by the student. We show that our method is effective on the Waterbirds, CelebA, Spawrious and UrbanCars datasets.
Generalisation in Neural Networks Does not Require Feature Overlap
Jul 04, 2021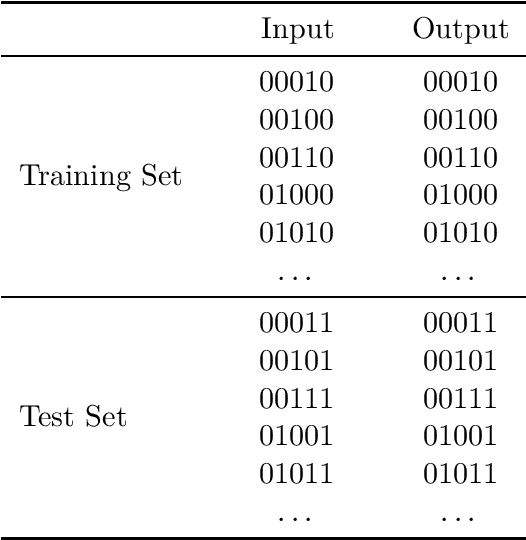


That shared features between train and test data are required for generalisation in artificial neural networks has been a common assumption of both proponents and critics of these models. Here, we show that convolutional architectures avoid this limitation by applying them to two well known challenges, based on learning the identity function and learning rules governing sequences of words. In each case, successful performance on the test set requires generalising to features that were not present in the training data, which is typically not feasible for standard connectionist models. However, our experiments demonstrate that neural networks can succeed on such problems when they incorporate the weight sharing employed by convolutional architectures. In the image processing domain, such architectures are intended to reflect the symmetry under spatial translations of the natural world that such images depict. We discuss the role of symmetry in the two tasks and its connection to generalisation.
Jack the Reader - A Machine Reading Framework
Jun 20, 2018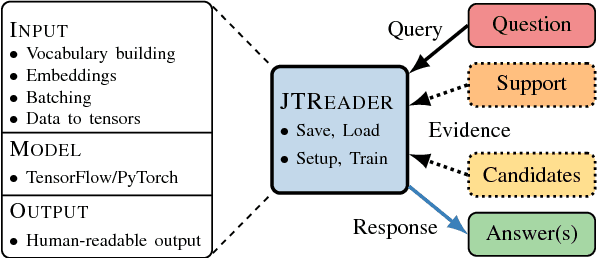
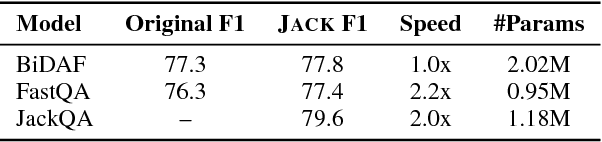

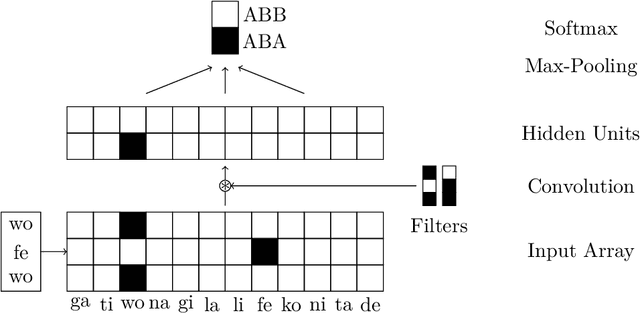
Many Machine Reading and Natural Language Understanding tasks require reading supporting text in order to answer questions. For example, in Question Answering, the supporting text can be newswire or Wikipedia articles; in Natural Language Inference, premises can be seen as the supporting text and hypotheses as questions. Providing a set of useful primitives operating in a single framework of related tasks would allow for expressive modelling, and easier model comparison and replication. To that end, we present Jack the Reader (Jack), a framework for Machine Reading that allows for quick model prototyping by component reuse, evaluation of new models on existing datasets as well as integrating new datasets and applying them on a growing set of implemented baseline models. Jack is currently supporting (but not limited to) three tasks: Question Answering, Natural Language Inference, and Link Prediction. It is developed with the aim of increasing research efficiency and code reuse.
Extrapolation in NLP
May 17, 2018



We argue that extrapolation to examples outside the training space will often be easier for models that capture global structures, rather than just maximise their local fit to the training data. We show that this is true for two popular models: the Decomposable Attention Model and word2vec.
Behavior Analysis of NLI Models: Uncovering the Influence of Three Factors on Robustness
May 11, 2018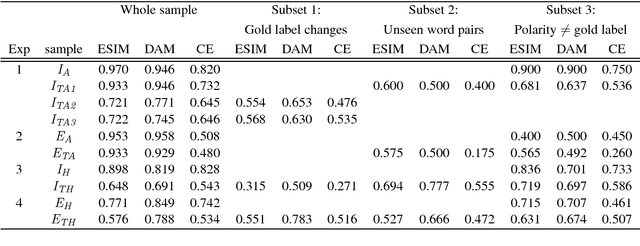

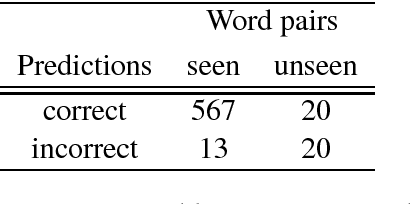
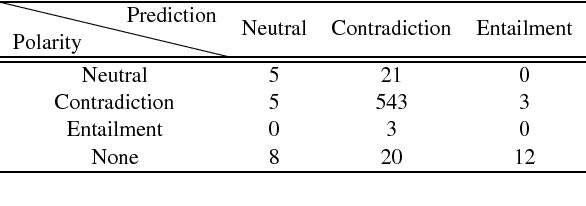
Natural Language Inference is a challenging task that has received substantial attention, and state-of-the-art models now achieve impressive test set performance in the form of accuracy scores. Here, we go beyond this single evaluation metric to examine robustness to semantically-valid alterations to the input data. We identify three factors - insensitivity, polarity and unseen pairs - and compare their impact on three SNLI models under a variety of conditions. Our results demonstrate a number of strengths and weaknesses in the models' ability to generalise to new in-domain instances. In particular, while strong performance is possible on unseen hypernyms, unseen antonyms are more challenging for all the models. More generally, the models suffer from an insensitivity to certain small but semantically significant alterations, and are also often influenced by simple statistical correlations between words and training labels. Overall, we show that evaluations of NLI models can benefit from studying the influence of factors intrinsic to the models or found in the dataset used.
Question Answering Resources Applied to Slot-Filling
Apr 22, 2018

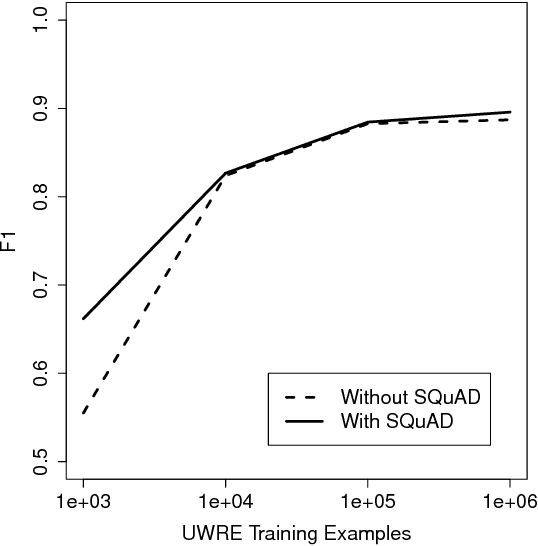
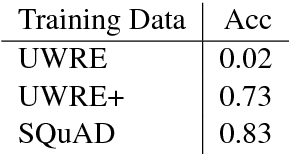
We investigate the utility of pre-existing question answering models and data for a recently proposed relation extraction task. We find that in the low-resource and zero-shot cases, such resources are surprisingly useful. Moreover, the resulting models show robust performance on a new test set we create from the task's original datasets.