Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Answering Resources Applied to Slot-Filling
Paper and Code
Apr 22, 2018

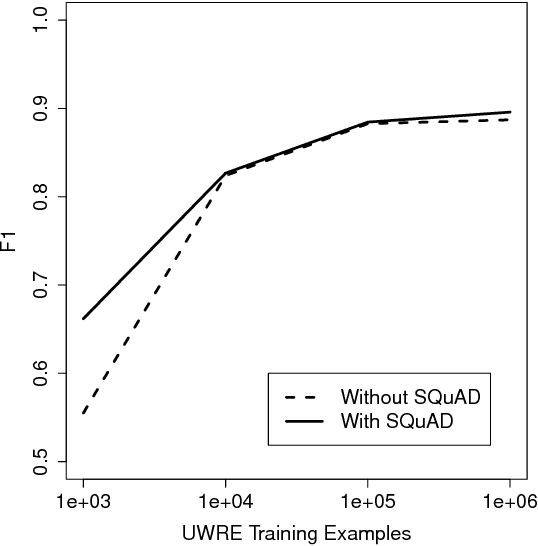
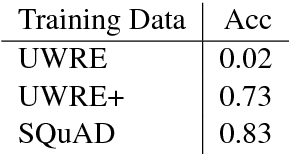
We investigate the utility of pre-existing question answering models and data for a recently proposed relation extraction task. We find that in the low-resource and zero-shot cases, such resources are surprisingly useful. Moreover, the resulting models show robust performance on a new test set we create from the task's original datasets.
View paper on