 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudies with impossible languages falsify LMs as models of human language
Nov 14, 2025According to Futrell and Mahowald [arXiv:2501.17047], both infants and language models (LMs) find attested languages easier to learn than impossible languages that have unnatural structures. We review the literature and show that LMs often learn attested and many impossible languages equally well. Difficult to learn impossible languages are simply more complex (or random). LMs are missing human inductive biases that support language acquisition.
Successes and Limitations of Object-centric Models at Compositional Generalisation
Dec 25, 2024In recent years, it has been shown empirically that standard disentangled latent variable models do not support robust compositional learning in the visual domain. Indeed, in spite of being designed with the goal of factorising datasets into their constituent factors of variations, disentangled models show extremely limited compositional generalisation capabilities. On the other hand, object-centric architectures have shown promising compositional skills, albeit these have 1) not been extensively tested and 2) experiments have been limited to scene composition -- where models must generalise to novel combinations of objects in a visual scene instead of novel combinations of object properties. In this work, we show that these compositional generalisation skills extend to this later setting. Furthermore, we present evidence pointing to the source of these skills and how they can be improved through careful training. Finally, we point to one important limitation that still exists which suggests new directions of research.
Adapting to time: why nature evolved a diverse set of neurons
Apr 22, 2024Evolution has yielded a diverse set of neurons with varying morphologies and physiological properties that impact their processing of temporal information. In addition, it is known empirically that spike timing is a significant factor in neural computations. However, despite these two observations, most neural network models deal with spatially structured inputs with synchronous time steps, while restricting variation to parameters like weights and biases. In this study, we investigate the relevance of adapting temporal parameters, like time constants and delays, in feedforward networks that map spatio-temporal spike patterns. In this context, we show that networks with richer potential dynamics are able to more easily and robustly learn tasks with temporal structure. Indeed, when adaptation was restricted to weights, networks were unable to solve most problems. We also show strong interactions between the various parameters and the advantages of adapting temporal parameters when dealing with noise in inputs and weights, which might prove useful in neuromorphic hardware design.
MindSet: Vision. A toolbox for testing DNNs on key psychological experiments
Apr 08, 2024



Multiple benchmarks have been developed to assess the alignment between deep neural networks (DNNs) and human vision. In almost all cases these benchmarks are observational in the sense they are composed of behavioural and brain responses to naturalistic images that have not been manipulated to test hypotheses regarding how DNNs or humans perceive and identify objects. Here we introduce the toolbox MindSet: Vision, consisting of a collection of image datasets and related scripts designed to test DNNs on 30 psychological findings. In all experimental conditions, the stimuli are systematically manipulated to test specific hypotheses regarding human visual perception and object recognition. In addition to providing pre-generated datasets of images, we provide code to regenerate these datasets, offering many configurable parameters which greatly extend the dataset versatility for different research contexts, and code to facilitate the testing of DNNs on these image datasets using three different methods (similarity judgments, out-of-distribution classification, and decoder method), accessible at https://github.com/MindSetVision/mindset-vision. We test ResNet-152 on each of these methods as an example of how the toolbox can be used.
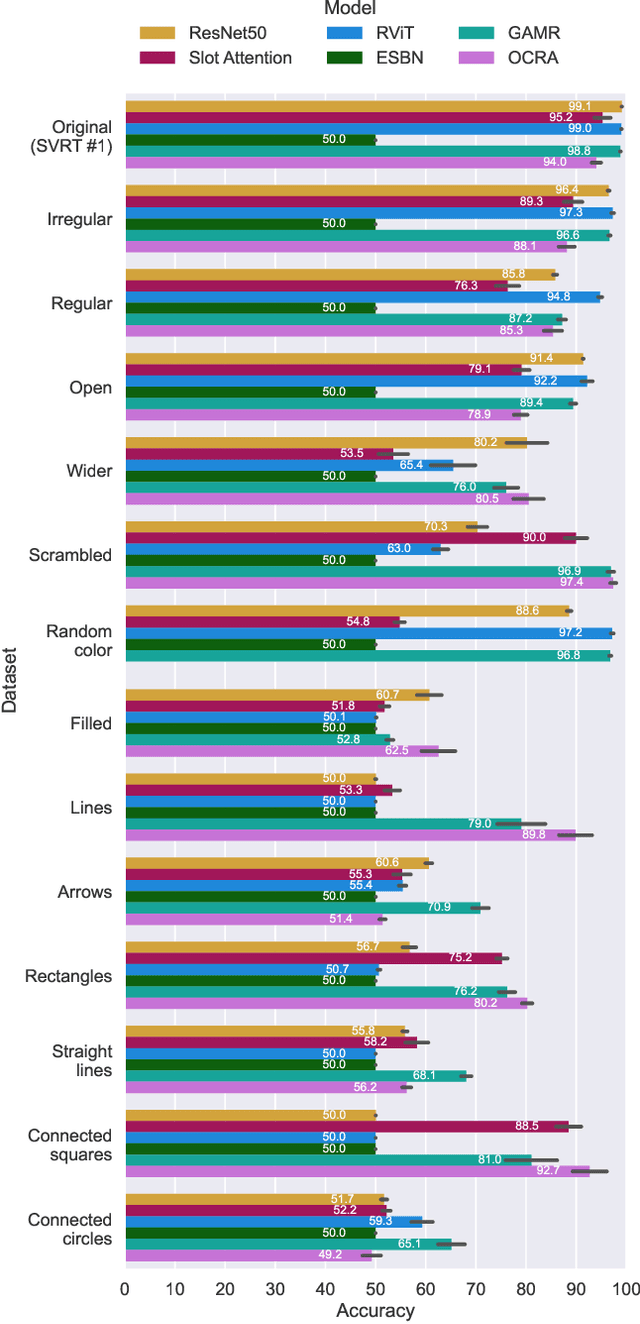
Visual Reasoning in Object-Centric Deep Neural Networks: A Comparative Cognition Approach
Feb 20, 2024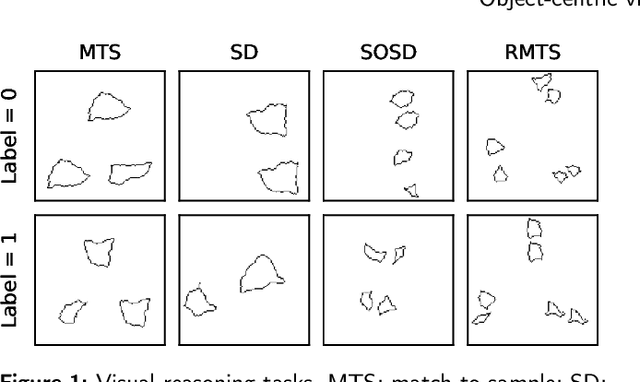

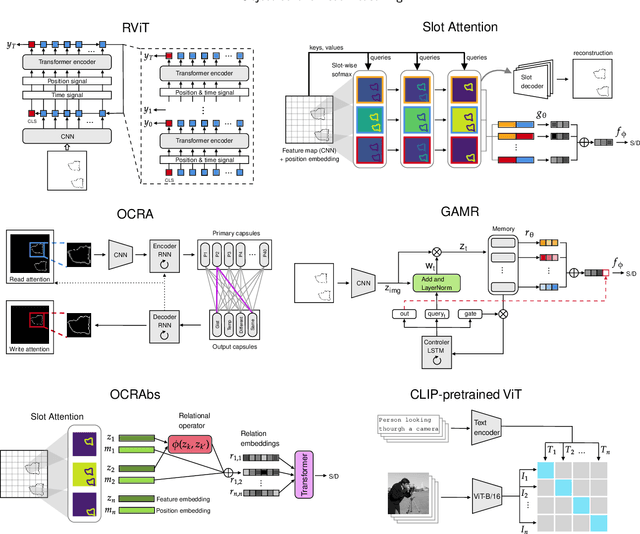
Achieving visual reasoning is a long-term goal of artificial intelligence. In the last decade, several studies have applied deep neural networks (DNNs) to the task of learning visual relations from images, with modest results in terms of generalization of the relations learned. However, in recent years, object-centric representation learning has been put forward as a way to achieve visual reasoning within the deep learning framework. Object-centric models attempt to model input scenes as compositions of objects and relations between them. To this end, these models use several kinds of attention mechanisms to segregate the individual objects in a scene from the background and from other objects. In this work we tested relation learning and generalization in several object-centric models, as well as a ResNet-50 baseline. In contrast to previous research, which has focused heavily in the same-different task in order to asses relational reasoning in DNNs, we use a set of tasks -- with varying degrees of difficulty -- derived from the comparative cognition literature. Our results show that object-centric models are able to segregate the different objects in a scene, even in many out-of-distribution cases. In our simpler tasks, this improves their capacity to learn and generalize visual relations in comparison to the ResNet-50 baseline. However, object-centric models still struggle in our more difficult tasks and conditions. We conclude that abstract visual reasoning remains an open challenge for DNNs, including object-centric models.
The role of object-centric representations, guided attention, and external memory on generalizing visual relations
Apr 14, 2023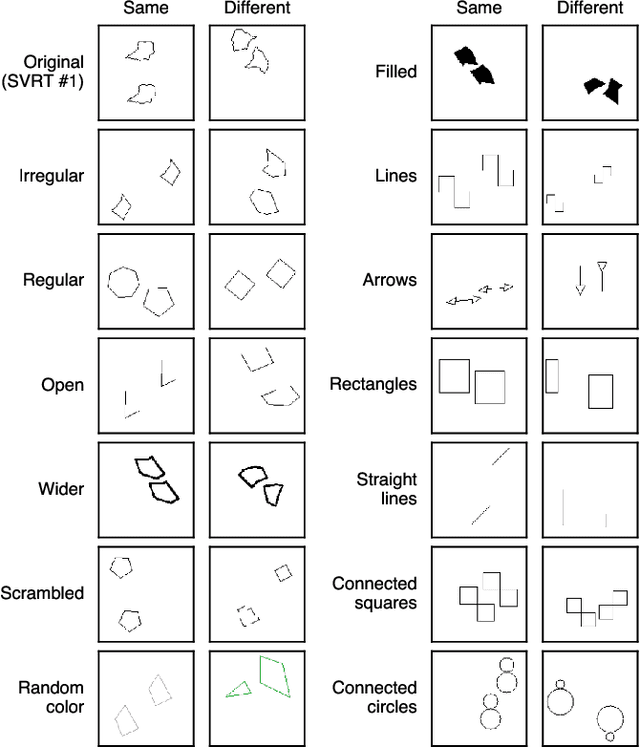
Visual reasoning is a long-term goal of vision research. In the last decade, several works have attempted to apply deep neural networks (DNNs) to the task of learning visual relations from images, with modest results in terms of the generalization of the relations learned. In recent years, several innovations in DNNs have been developed in order to enable learning abstract relation from images. In this work, we systematically evaluate a series of DNNs that integrate mechanism such as slot attention, recurrently guided attention, and external memory, in the simplest possible visual reasoning task: deciding whether two objects are the same or different. We found that, although some models performed better than others in generalizing the same-different relation to specific types of images, no model was able to generalize this relation across the board. We conclude that abstract visual reasoning remains largely an unresolved challenge for DNNs.
Do DNNs trained on Natural Images organize visual features into Gestalts?
Apr 06, 2022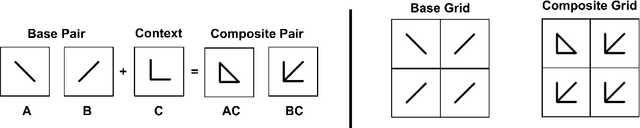
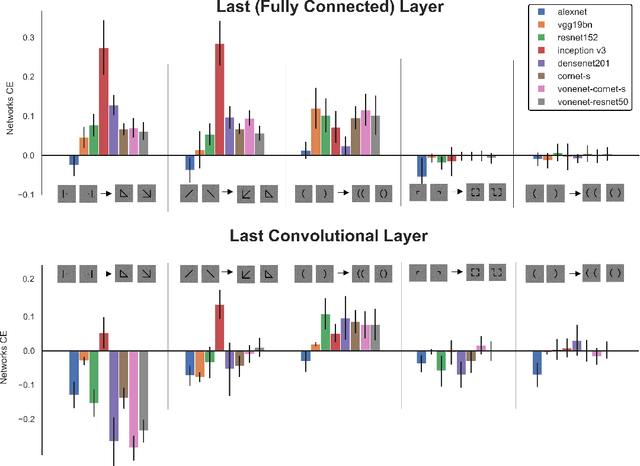
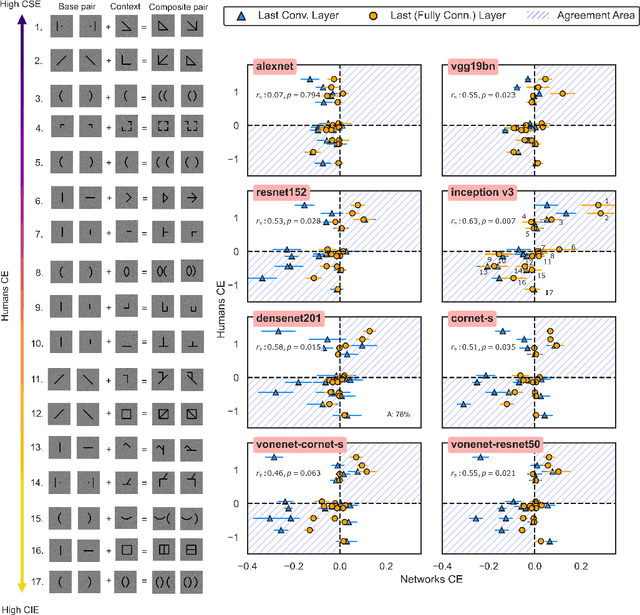
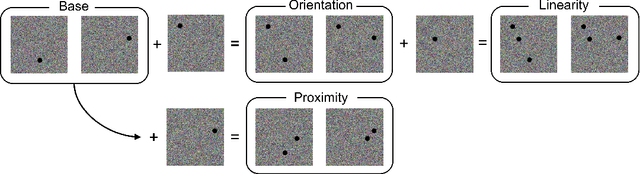
Gestalt psychologists have identified a range of conditions in which humans organize elements of a scene into a group or whole, and these perceptual grouping principles play an important role in scene perception and object identification. More recently, Deep Neural Networks (DNNs) trained on natural images have been proposed as compelling models of human vision based on reports that they perform well on various brain and behavioral benchmarks. Here we compared human and DNNs responses in discrimination judgments that assess a range of Gestalt organization principles. We found that most networks exhibited a moderate degree of Gestalt grouping for some complex stimuli at the last fully connected layer. However, in contrast with human neural data, this sensitivity vanishes at earlier visual processing layers. In a second experiment, by using simple dots configuration patterns, we found that all networks were only weakly sensitive to the grouping properties of proximity, and completely insensitive to orientation and linearity, three principles that have been shown to have a strong and robust effect on humans. Even top-performing models on the behavioral and brain benchmark Brain-Score miss these fundamental properties of human vision. Our overall conclusion is that, even when exhibiting Gestalt grouping, networks trained on 2D images use perceptual principles fundamentally different than humans.
Successes and critical failures of neural networks in capturing human-like speech recognition
Apr 06, 2022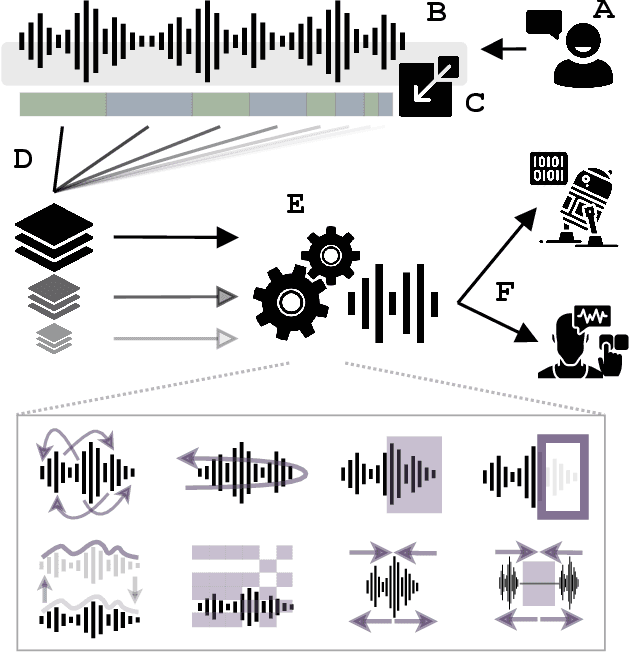
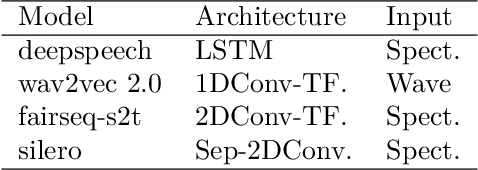
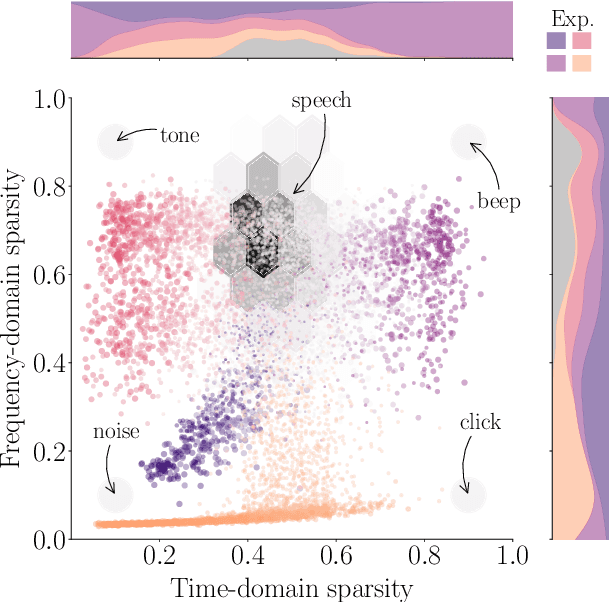
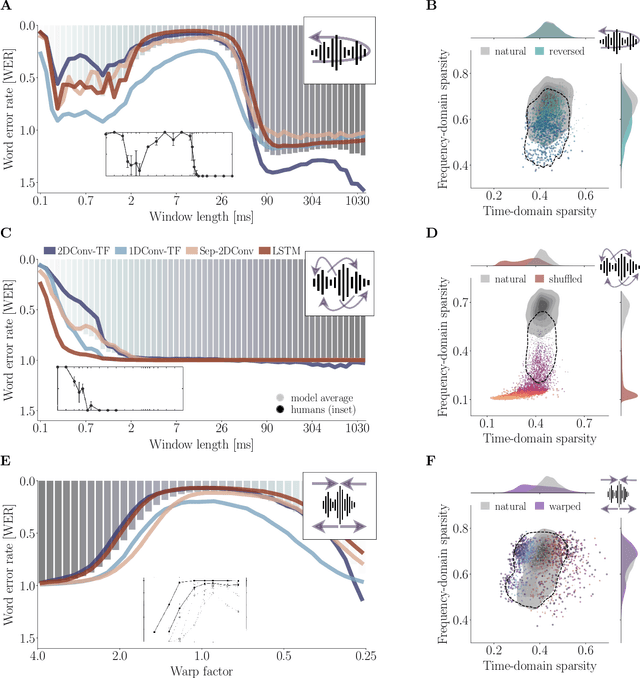
Natural and artificial audition can in principle evolve different solutions to a given problem. The constraints of the task, however, can nudge the cognitive science and engineering of audition to qualitatively converge, suggesting that a closer mutual examination would improve artificial hearing systems and process models of the mind and brain. Speech recognition - an area ripe for such exploration - is inherently robust in humans to a number transformations at various spectrotemporal granularities. To what extent are these robustness profiles accounted for by high-performing neural network systems? We bring together experiments in speech recognition under a single synthesis framework to evaluate state-of-the-art neural networks as stimulus-computable, optimized observers. In a series of experiments, we (1) clarify how influential speech manipulations in the literature relate to each other and to natural speech, (2) show the granularities at which machines exhibit out-of-distribution robustness, reproducing classical perceptual phenomena in humans, (3) identify the specific conditions where model predictions of human performance differ, and (4) demonstrate a crucial failure of all artificial systems to perceptually recover where humans do, suggesting a key specification for theory and model building. These findings encourage a tighter synergy between the cognitive science and engineering of audition.
Lost in Latent Space: Disentangled Models and the Challenge of Combinatorial Generalisation
Apr 05, 2022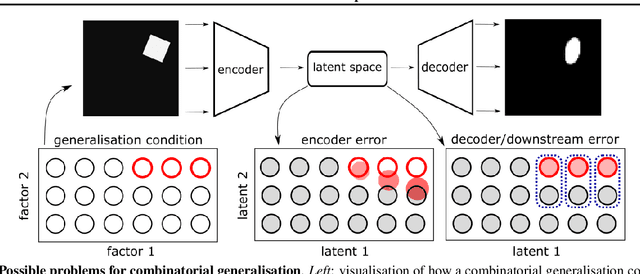
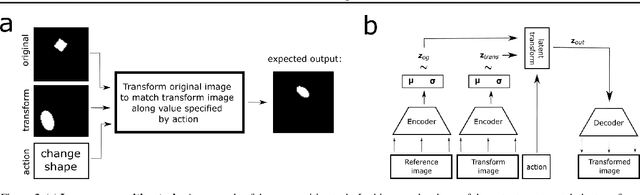
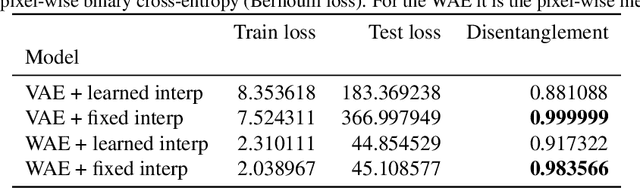
Recent research has shown that generative models with highly disentangled representations fail to generalise to unseen combination of generative factor values. These findings contradict earlier research which showed improved performance in out-of-training distribution settings when compared to entangled representations. Additionally, it is not clear if the reported failures are due to (a) encoders failing to map novel combinations to the proper regions of the latent space or (b) novel combinations being mapped correctly but the decoder/downstream process is unable to render the correct output for the unseen combinations. We investigate these alternatives by testing several models on a range of datasets and training settings. We find that (i) when models fail, their encoders also fail to map unseen combinations to correct regions of the latent space and (ii) when models succeed, it is either because the test conditions do not exclude enough examples, or because excluded generative factors determine independent parts of the output image. Based on these results, we argue that to generalise properly, models not only need to capture factors of variation, but also understand how to invert the generative process that was used to generate the data.
Convolutional Neural Networks Are Not Invariant to Translation, but They Can Learn to Be
Oct 12, 2021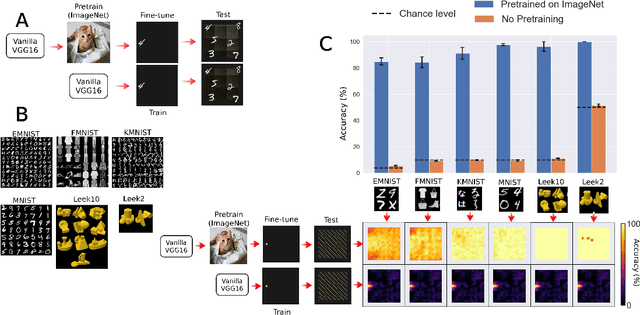
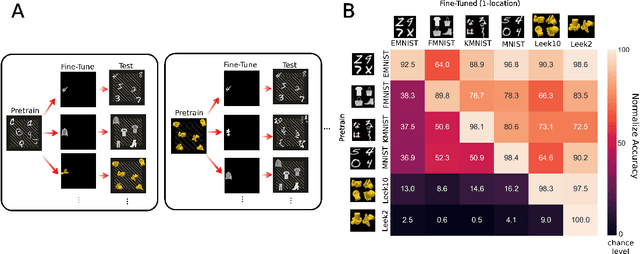

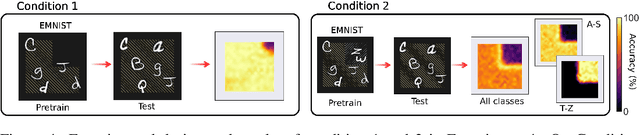
When seeing a new object, humans can immediately recognize it across different retinal locations: the internal object representation is invariant to translation. It is commonly believed that Convolutional Neural Networks (CNNs) are architecturally invariant to translation thanks to the convolution and/or pooling operations they are endowed with. In fact, several studies have found that these networks systematically fail to recognise new objects on untrained locations. In this work, we test a wide variety of CNNs architectures showing how, apart from DenseNet-121, none of the models tested was architecturally invariant to translation. Nevertheless, all of them could learn to be invariant to translation. We show how this can be achieved by pretraining on ImageNet, and it is sometimes possible with much simpler data sets when all the items are fully translated across the input canvas. At the same time, this invariance can be disrupted by further training due to catastrophic forgetting/interference. These experiments show how pretraining a network on an environment with the right `latent' characteristics (a more naturalistic environment) can result in the network learning deep perceptual rules which would dramatically improve subsequent generalization.