 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Basic Affordances to Symbolic Thought: A Computational Phylogenesis of Biological Intelligence
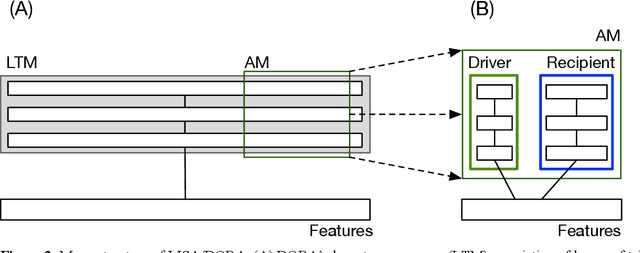
Aug 20, 2025What is it about human brains that allows us to reason symbolically whereas most other animals cannot? There is evidence that dynamic binding, the ability to combine neurons into groups on the fly, is necessary for symbolic thought, but there is also evidence that it is not sufficient. We propose that two kinds of hierarchical integration (integration of multiple role-bindings into multiplace predicates, and integration of multiple correspondences into structure mappings) are minimal requirements, on top of basic dynamic binding, to realize symbolic thought. We tested this hypothesis in a systematic collection of 17 simulations that explored the ability of cognitive architectures with and without the capacity for multi-place predicates and structure mapping to perform various kinds of tasks. The simulations were as generic as possible, in that no task could be performed based on any diagnostic features, depending instead on the capacity for multi-place predicates and structure mapping. The results are consistent with the hypothesis that, along with dynamic binding, multi-place predicates and structure mapping are minimal requirements for basic symbolic thought. These results inform our understanding of how human brains give rise to symbolic thought and speak to the differences between biological intelligence, which tends to generalize broadly from very few training examples, and modern approaches to machine learning, which typically require millions or billions of training examples. The results we report also have important implications for bio-inspired artificial intelligence.
MindSet: Vision. A toolbox for testing DNNs on key psychological experiments
Apr 08, 2024



Multiple benchmarks have been developed to assess the alignment between deep neural networks (DNNs) and human vision. In almost all cases these benchmarks are observational in the sense they are composed of behavioural and brain responses to naturalistic images that have not been manipulated to test hypotheses regarding how DNNs or humans perceive and identify objects. Here we introduce the toolbox MindSet: Vision, consisting of a collection of image datasets and related scripts designed to test DNNs on 30 psychological findings. In all experimental conditions, the stimuli are systematically manipulated to test specific hypotheses regarding human visual perception and object recognition. In addition to providing pre-generated datasets of images, we provide code to regenerate these datasets, offering many configurable parameters which greatly extend the dataset versatility for different research contexts, and code to facilitate the testing of DNNs on these image datasets using three different methods (similarity judgments, out-of-distribution classification, and decoder method), accessible at https://github.com/MindSetVision/mindset-vision. We test ResNet-152 on each of these methods as an example of how the toolbox can be used.
Relation learning in a neurocomputational architecture supports cross-domain transfer
Oct 11, 2019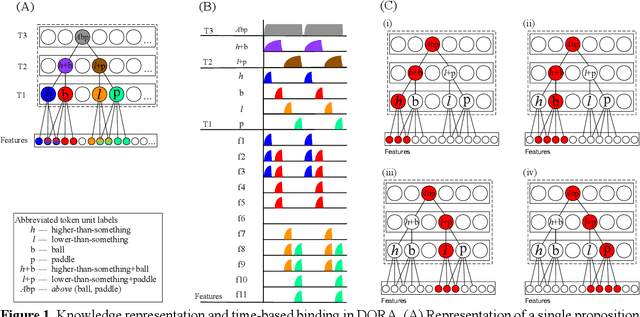


People readily generalise prior knowledge to novel situations and stimuli. Advances in machine learning and artificial intelligence have begun to approximate and even surpass human performance in specific domains, but machine learning systems struggle to generalise information to untrained situations. We present and model that demonstrates human-like extrapolatory generalisation by learning and explicitly representing an open-ended set of relations characterising regularities within the domains it is exposed to. First, when trained to play one video game (e.g., Breakout). the model generalises to a new game (e.g., Pong) with different rules, dimensions, and characteristics in a single shot. Second, the model can learn representations from a different domain (e.g., 3D shape images) that support learning a video game and generalising to a new game in one shot. By exploiting well-established principles from cognitive psychology and neuroscience, the model learns structured representations without feedback, and without requiring knowledge of the relevant relations to be given a priori. We present additional simulations showing that the representations that the model learns support cross-domain generalisation. The model's ability to generalise between different games demonstrates the flexible generalisation afforded by a capacity to learn not only statistical relations, but also other relations that are useful for characterising the domain to be learned. In turn, this kind of flexible, relational generalisation is only possible because the model is capable of representing relations explicitly, a capacity that is notably absent in extant statistical machine learning algorithms.