 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuccesses and Limitations of Object-centric Models at Compositional Generalisation
Dec 25, 2024In recent years, it has been shown empirically that standard disentangled latent variable models do not support robust compositional learning in the visual domain. Indeed, in spite of being designed with the goal of factorising datasets into their constituent factors of variations, disentangled models show extremely limited compositional generalisation capabilities. On the other hand, object-centric architectures have shown promising compositional skills, albeit these have 1) not been extensively tested and 2) experiments have been limited to scene composition -- where models must generalise to novel combinations of objects in a visual scene instead of novel combinations of object properties. In this work, we show that these compositional generalisation skills extend to this later setting. Furthermore, we present evidence pointing to the source of these skills and how they can be improved through careful training. Finally, we point to one important limitation that still exists which suggests new directions of research.
MindSet: Vision. A toolbox for testing DNNs on key psychological experiments
Apr 08, 2024



Multiple benchmarks have been developed to assess the alignment between deep neural networks (DNNs) and human vision. In almost all cases these benchmarks are observational in the sense they are composed of behavioural and brain responses to naturalistic images that have not been manipulated to test hypotheses regarding how DNNs or humans perceive and identify objects. Here we introduce the toolbox MindSet: Vision, consisting of a collection of image datasets and related scripts designed to test DNNs on 30 psychological findings. In all experimental conditions, the stimuli are systematically manipulated to test specific hypotheses regarding human visual perception and object recognition. In addition to providing pre-generated datasets of images, we provide code to regenerate these datasets, offering many configurable parameters which greatly extend the dataset versatility for different research contexts, and code to facilitate the testing of DNNs on these image datasets using three different methods (similarity judgments, out-of-distribution classification, and decoder method), accessible at https://github.com/MindSetVision/mindset-vision. We test ResNet-152 on each of these methods as an example of how the toolbox can be used.
Lost in Latent Space: Disentangled Models and the Challenge of Combinatorial Generalisation
Apr 05, 2022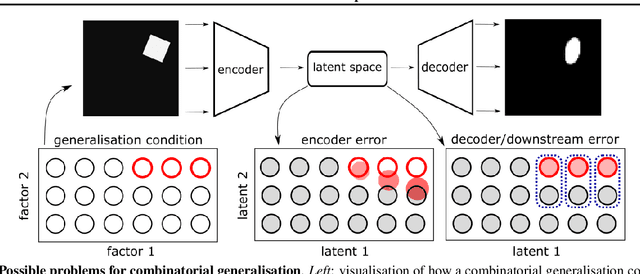
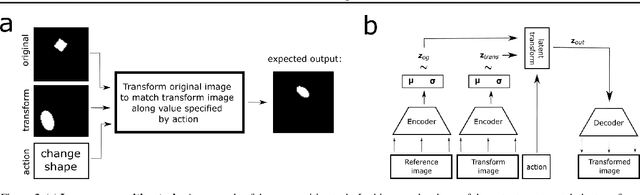
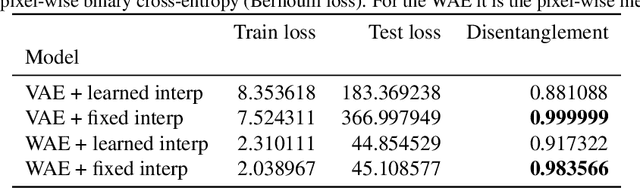
Recent research has shown that generative models with highly disentangled representations fail to generalise to unseen combination of generative factor values. These findings contradict earlier research which showed improved performance in out-of-training distribution settings when compared to entangled representations. Additionally, it is not clear if the reported failures are due to (a) encoders failing to map novel combinations to the proper regions of the latent space or (b) novel combinations being mapped correctly but the decoder/downstream process is unable to render the correct output for the unseen combinations. We investigate these alternatives by testing several models on a range of datasets and training settings. We find that (i) when models fail, their encoders also fail to map unseen combinations to correct regions of the latent space and (ii) when models succeed, it is either because the test conditions do not exclude enough examples, or because excluded generative factors determine independent parts of the output image. Based on these results, we argue that to generalise properly, models not only need to capture factors of variation, but also understand how to invert the generative process that was used to generate the data.
Auto-Tag: Tagging-Data-By-Example in Data Lakes
Dec 11, 2021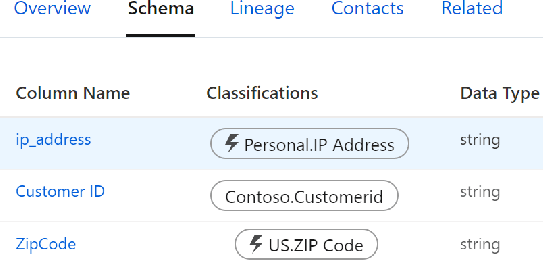


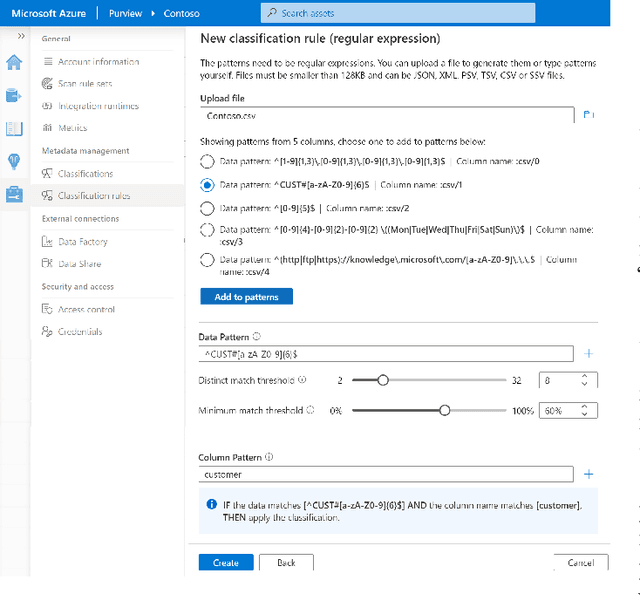
As data lakes become increasingly popular in large enterprises today, there is a growing need to tag or classify data assets (e.g., files and databases) in data lakes with additional metadata (e.g., semantic column-types), as the inferred metadata can enable a range of downstream applications like data governance (e.g., GDPR compliance), and dataset search. Given the sheer size of today's enterprise data lakes with petabytes of data and millions of data assets, it is imperative that data assets can be ``auto-tagged'', using lightweight inference algorithms and minimal user input. In this work, we develop Auto-Tag, a corpus-driven approach that automates data-tagging of \textit{custom} data types in enterprise data lakes. Using Auto-Tag, users only need to provide \textit{one} example column to demonstrate the desired data-type to tag. Leveraging an index structure built offline using a lightweight scan of the data lake, which is analogous to pre-training in machine learning, Auto-Tag can infer suitable data patterns to best ``describe'' the underlying ``domain'' of the given column at an interactive speed, which can then be used to tag additional data of the same ``type'' in data lakes. The Auto-Tag approach can adapt to custom data-types, and is shown to be both accurate and efficient. Part of Auto-Tag ships as a ``custom-classification'' feature in a cloud-based data governance and catalog solution \textit{Azure Purview}.