 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTU: A Massive Multi-Task Table Understanding and Reasoning Benchmark
Jun 05, 2025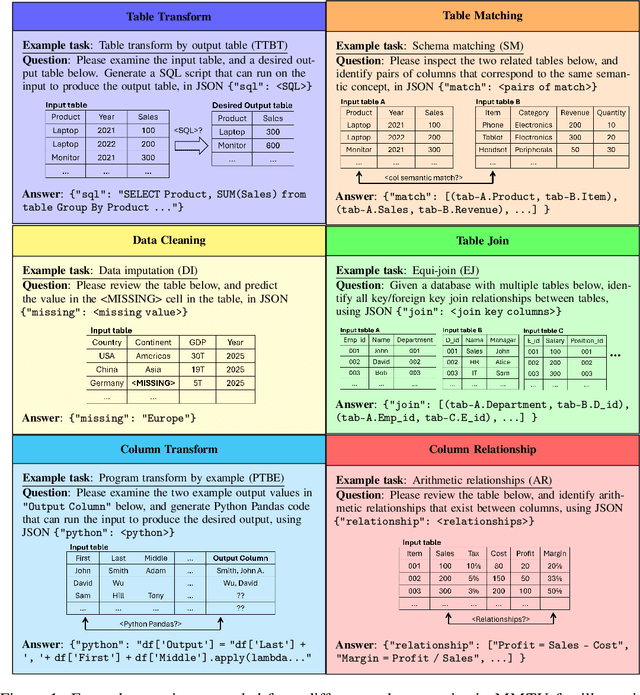
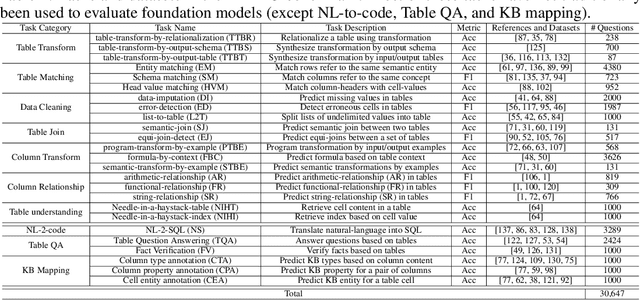

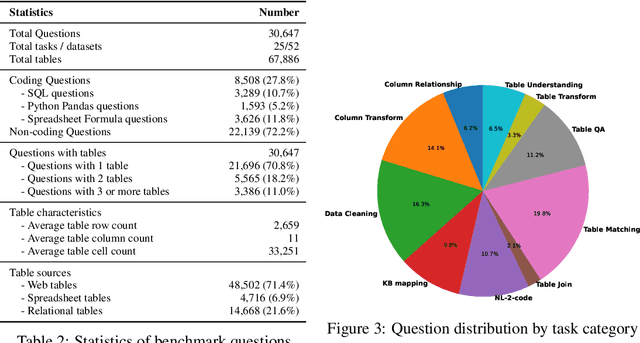
Tables and table-based use cases play a crucial role in many important real-world applications, such as spreadsheets, databases, and computational notebooks, which traditionally require expert-level users like data engineers, data analysts, and database administrators to operate. Although LLMs have shown remarkable progress in working with tables (e.g., in spreadsheet and database copilot scenarios), comprehensive benchmarking of such capabilities remains limited. In contrast to an extensive and growing list of NLP benchmarks, evaluations of table-related tasks are scarce, and narrowly focus on tasks like NL-to-SQL and Table-QA, overlooking the broader spectrum of real-world tasks that professional users face. This gap limits our understanding and model progress in this important area. In this work, we introduce MMTU, a large-scale benchmark with over 30K questions across 25 real-world table tasks, designed to comprehensively evaluate models ability to understand, reason, and manipulate real tables at the expert-level. These tasks are drawn from decades' worth of computer science research on tabular data, with a focus on complex table tasks faced by professional users. We show that MMTU require a combination of skills -- including table understanding, reasoning, and coding -- that remain challenging for today's frontier models, where even frontier reasoning models like OpenAI o4-mini and DeepSeek R1 score only around 60%, suggesting significant room for improvement. We highlight key findings in our evaluation using MMTU and hope that this benchmark drives further advances in understanding and developing foundation models for structured data processing and analysis. Our code and data are available at https://github.com/MMTU-Benchmark/MMTU and https://huggingface.co/datasets/MMTU-benchmark/MMTU.
MINT: Multi-Vector Search Index Tuning
Apr 28, 2025Vector search plays a crucial role in many real-world applications. In addition to single-vector search, multi-vector search becomes important for multi-modal and multi-feature scenarios today. In a multi-vector database, each row is an item, each column represents a feature of items, and each cell is a high-dimensional vector. In multi-vector databases, the choice of indexes can have a significant impact on performance. Although index tuning for relational databases has been extensively studied, index tuning for multi-vector search remains unclear and challenging. In this paper, we define multi-vector search index tuning and propose a framework to solve it. Specifically, given a multi-vector search workload, we develop algorithms to find indexes that minimize latency and meet storage and recall constraints. Compared to the baseline, our latency achieves 2.1X to 8.3X speedup.
Auto-Test: Learning Semantic-Domain Constraints for Unsupervised Error Detection in Tables
Apr 14, 2025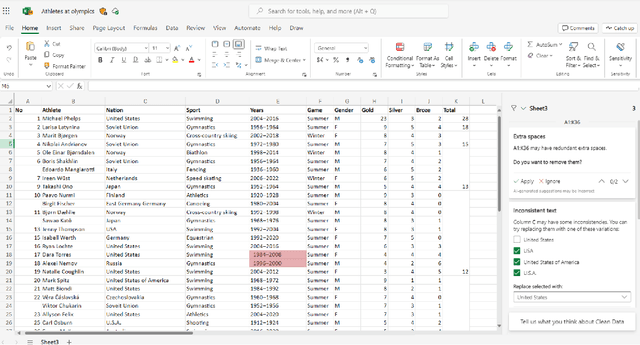
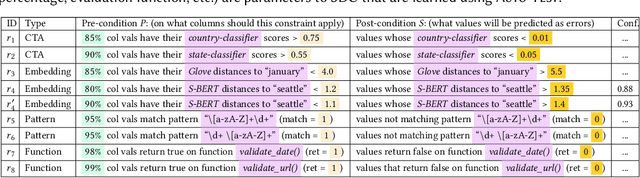


Data cleaning is a long-standing challenge in data management. While powerful logic and statistical algorithms have been developed to detect and repair data errors in tables, existing algorithms predominantly rely on domain-experts to first manually specify data-quality constraints specific to a given table, before data cleaning algorithms can be applied. In this work, we propose a new class of data-quality constraints that we call Semantic-Domain Constraints, which can be reliably inferred and automatically applied to any tables, without requiring domain-experts to manually specify on a per-table basis. We develop a principled framework to systematically learn such constraints from table corpora using large-scale statistical tests, which can further be distilled into a core set of constraints using our optimization framework, with provable quality guarantees. Extensive evaluations show that this new class of constraints can be used to both (1) directly detect errors on real tables in the wild, and (2) augment existing expert-driven data-cleaning techniques as a new class of complementary constraints. Our extensively labeled benchmark dataset with 2400 real data columns, as well as our code are available at https://github.com/qixuchen/AutoTest to facilitate future research.
Table-LLM-Specialist: Language Model Specialists for Tables using Iterative Generator-Validator Fine-tuning
Oct 16, 2024



In this work, we propose Table-LLM-Specialist, or Table-Specialist for short, as a new self-trained fine-tuning paradigm specifically designed for table tasks. Our insight is that for each table task, there often exist two dual versions of the same task, one generative and one classification in nature. Leveraging their duality, we propose a Generator-Validator paradigm, to iteratively generate-then-validate training data from language-models, to fine-tune stronger \sys models that can specialize in a given task, without requiring manually-labeled data. Our extensive evaluations suggest that our Table-Specialist has (1) \textit{strong performance} on diverse table tasks over vanilla language-models -- for example, Table-Specialist fine-tuned on GPT-3.5 not only outperforms vanilla GPT-3.5, but can often match or surpass GPT-4 level quality, (2) \textit{lower cost} to deploy, because when Table-Specialist fine-tuned on GPT-3.5 achieve GPT-4 level quality, it becomes possible to deploy smaller models with lower latency and inference cost, with comparable quality, and (3) \textit{better generalizability} when evaluated across multiple benchmarks, since \sys is fine-tuned on a broad range of training data systematically generated from diverse real tables. Our code and data will be available at https://github.com/microsoft/Table-LLM-Specialist.
Auto-Formula: Recommend Formulas in Spreadsheets using Contrastive Learning for Table Representations
Apr 19, 2024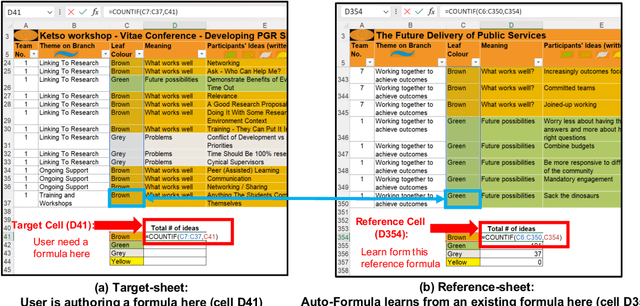
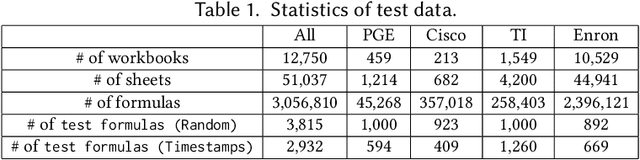
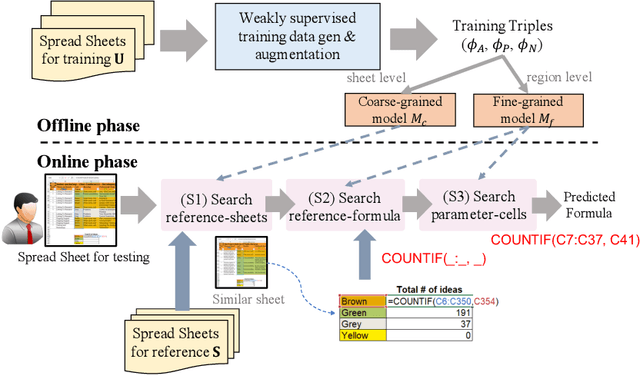

Spreadsheets are widely recognized as the most popular end-user programming tools, which blend the power of formula-based computation, with an intuitive table-based interface. Today, spreadsheets are used by billions of users to manipulate tables, most of whom are neither database experts nor professional programmers. Despite the success of spreadsheets, authoring complex formulas remains challenging, as non-technical users need to look up and understand non-trivial formula syntax. To address this pain point, we leverage the observation that there is often an abundance of similar-looking spreadsheets in the same organization, which not only have similar data, but also share similar computation logic encoded as formulas. We develop an Auto-Formula system that can accurately predict formulas that users want to author in a target spreadsheet cell, by learning and adapting formulas that already exist in similar spreadsheets, using contrastive-learning techniques inspired by "similar-face recognition" from compute vision. Extensive evaluations on over 2K test formulas extracted from real enterprise spreadsheets show the effectiveness of Auto-Formula over alternatives. Our benchmark data is available at https://github.com/microsoft/Auto-Formula to facilitate future research.
Table-GPT: Table-tuned GPT for Diverse Table Tasks
Oct 13, 2023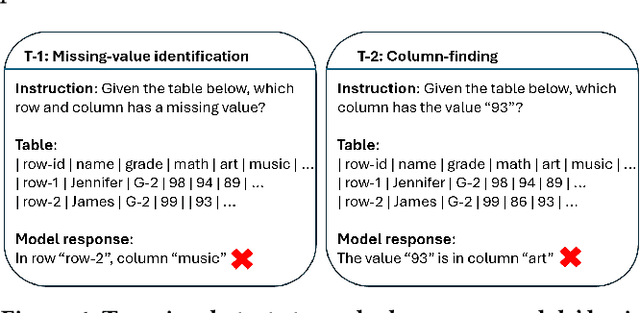
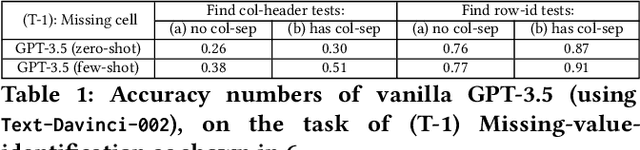

Language models, such as GPT-3.5 and ChatGPT, demonstrate remarkable abilities to follow diverse human instructions and perform a wide range of tasks. However, when probing language models using a range of basic table-understanding tasks, we observe that today's language models are still sub-optimal in many table-related tasks, likely because they are pre-trained predominantly on \emph{one-dimensional} natural-language texts, whereas relational tables are \emph{two-dimensional} objects. In this work, we propose a new "\emph{table-tuning}" paradigm, where we continue to train/fine-tune language models like GPT-3.5 and ChatGPT, using diverse table-tasks synthesized from real tables as training data, with the goal of enhancing language models' ability to understand tables and perform table tasks. We show that our resulting Table-GPT models demonstrate (1) better \emph{table-understanding} capabilities, by consistently outperforming the vanilla GPT-3.5 and ChatGPT, on a wide-range of table tasks, including holdout unseen tasks, and (2) strong \emph{generalizability}, in its ability to respond to diverse human instructions to perform new table-tasks, in a manner similar to GPT-3.5 and ChatGPT.
Auto-Tables: Synthesizing Multi-Step Transformations to Relationalize Tables without Using Examples
Aug 09, 2023Relational tables, where each row corresponds to an entity and each column corresponds to an attribute, have been the standard for tables in relational databases. However, such a standard cannot be taken for granted when dealing with tables "in the wild". Our survey of real spreadsheet-tables and web-tables shows that over 30% of such tables do not conform to the relational standard, for which complex table-restructuring transformations are needed before these tables can be queried easily using SQL-based analytics tools. Unfortunately, the required transformations are non-trivial to program, which has become a substantial pain point for technical and non-technical users alike, as evidenced by large numbers of forum questions in places like StackOverflow and Excel/Power-BI/Tableau forums. We develop an Auto-Tables system that can automatically synthesize pipelines with multi-step transformations (in Python or other languages), to transform non-relational tables into standard relational forms for downstream analytics, obviating the need for users to manually program transformations. We compile an extensive benchmark for this new task, by collecting 244 real test cases from user spreadsheets and online forums. Our evaluation suggests that Auto-Tables can successfully synthesize transformations for over 70% of test cases at interactive speeds, without requiring any input from users, making this an effective tool for both technical and non-technical users to prepare data for analytics.
Auto-Validate by-History: Auto-Program Data Quality Constraints to Validate Recurring Data Pipelines
Jun 04, 2023



Data pipelines are widely employed in modern enterprises to power a variety of Machine-Learning (ML) and Business-Intelligence (BI) applications. Crucially, these pipelines are \emph{recurring} (e.g., daily or hourly) in production settings to keep data updated so that ML models can be re-trained regularly, and BI dashboards refreshed frequently. However, data quality (DQ) issues can often creep into recurring pipelines because of upstream schema and data drift over time. As modern enterprises operate thousands of recurring pipelines, today data engineers have to spend substantial efforts to \emph{manually} monitor and resolve DQ issues, as part of their DataOps and MLOps practices. Given the high human cost of managing large-scale pipeline operations, it is imperative that we can \emph{automate} as much as possible. In this work, we propose Auto-Validate-by-History (AVH) that can automatically detect DQ issues in recurring pipelines, leveraging rich statistics from historical executions. We formalize this as an optimization problem, and develop constant-factor approximation algorithms with provable precision guarantees. Extensive evaluations using 2000 production data pipelines at Microsoft demonstrate the effectiveness and efficiency of AVH.
Auto-Tag: Tagging-Data-By-Example in Data Lakes
Dec 11, 2021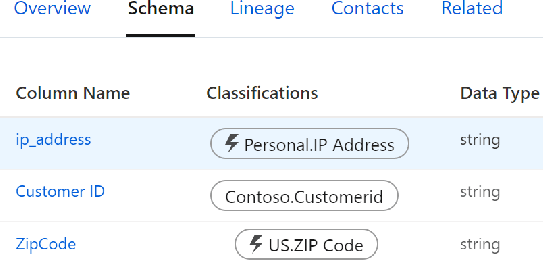


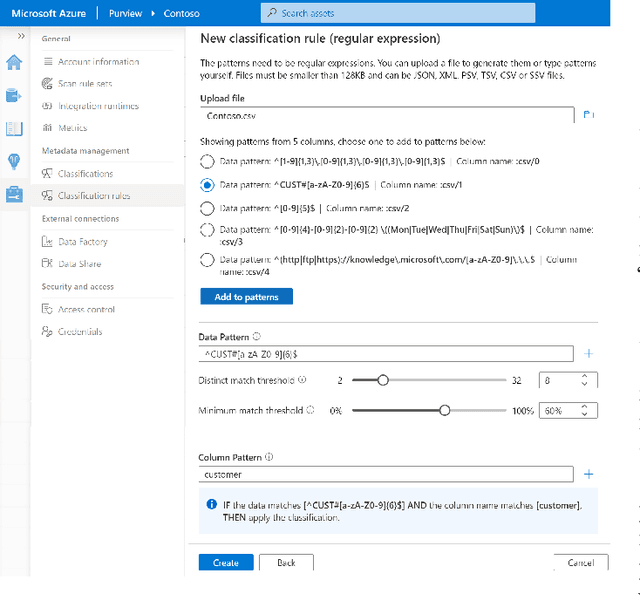
As data lakes become increasingly popular in large enterprises today, there is a growing need to tag or classify data assets (e.g., files and databases) in data lakes with additional metadata (e.g., semantic column-types), as the inferred metadata can enable a range of downstream applications like data governance (e.g., GDPR compliance), and dataset search. Given the sheer size of today's enterprise data lakes with petabytes of data and millions of data assets, it is imperative that data assets can be ``auto-tagged'', using lightweight inference algorithms and minimal user input. In this work, we develop Auto-Tag, a corpus-driven approach that automates data-tagging of \textit{custom} data types in enterprise data lakes. Using Auto-Tag, users only need to provide \textit{one} example column to demonstrate the desired data-type to tag. Leveraging an index structure built offline using a lightweight scan of the data lake, which is analogous to pre-training in machine learning, Auto-Tag can infer suitable data patterns to best ``describe'' the underlying ``domain'' of the given column at an interactive speed, which can then be used to tag additional data of the same ``type'' in data lakes. The Auto-Tag approach can adapt to custom data-types, and is shown to be both accurate and efficient. Part of Auto-Tag ships as a ``custom-classification'' feature in a cloud-based data governance and catalog solution \textit{Azure Purview}.
AutoPipeline: Synthesize Data Pipelines By-Target Using Reinforcement Learning and Search
Jun 25, 2021

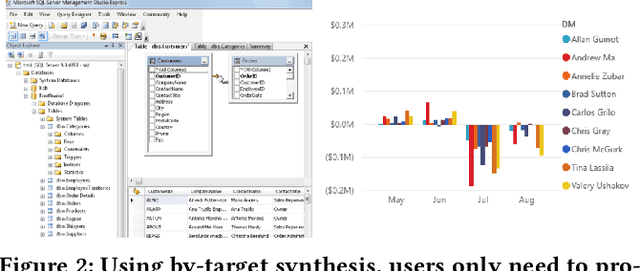

Recent work has made significant progress in helping users to automate single data preparation steps, such as string-transformations and table-manipulation operators (e.g., Join, GroupBy, Pivot, etc.). We in this work propose to automate multiple such steps end-to-end, by synthesizing complex data pipelines with both string transformations and table-manipulation operators. We propose a novel "by-target" paradigm that allows users to easily specify the desired pipeline, which is a significant departure from the traditional by-example paradigm. Using by-target, users would provide input tables (e.g., csv or json files), and point us to a "target table" (e.g., an existing database table or BI dashboard) to demonstrate how the output from the desired pipeline would schematically "look like". While the problem is seemingly underspecified, our unique insight is that implicit table constraints such as FDs and keys can be exploited to significantly constrain the space to make the problem tractable. We develop an Auto-Pipeline system that learns to synthesize pipelines using reinforcement learning and search. Experiments on large numbers of real pipelines crawled from GitHub suggest that Auto-Pipeline can successfully synthesize 60-70% of these complex pipelines (up to 10 steps) in 10-20 seconds on average.