 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Test: Learning Semantic-Domain Constraints for Unsupervised Error Detection in Tables
Apr 14, 2025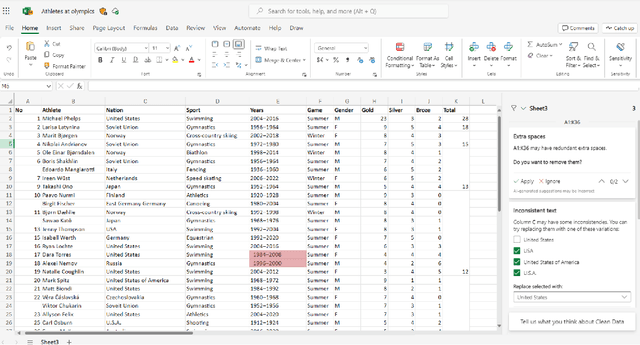
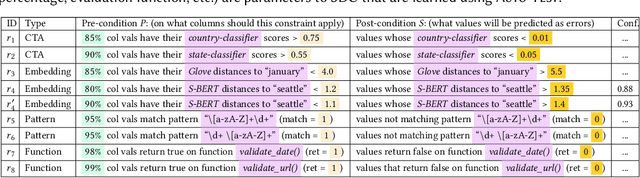


Data cleaning is a long-standing challenge in data management. While powerful logic and statistical algorithms have been developed to detect and repair data errors in tables, existing algorithms predominantly rely on domain-experts to first manually specify data-quality constraints specific to a given table, before data cleaning algorithms can be applied. In this work, we propose a new class of data-quality constraints that we call Semantic-Domain Constraints, which can be reliably inferred and automatically applied to any tables, without requiring domain-experts to manually specify on a per-table basis. We develop a principled framework to systematically learn such constraints from table corpora using large-scale statistical tests, which can further be distilled into a core set of constraints using our optimization framework, with provable quality guarantees. Extensive evaluations show that this new class of constraints can be used to both (1) directly detect errors on real tables in the wild, and (2) augment existing expert-driven data-cleaning techniques as a new class of complementary constraints. Our extensively labeled benchmark dataset with 2400 real data columns, as well as our code are available at https://github.com/qixuchen/AutoTest to facilitate future research.
Auto-Formula: Recommend Formulas in Spreadsheets using Contrastive Learning for Table Representations
Apr 19, 2024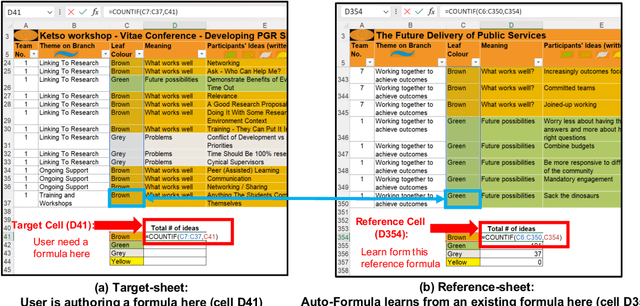
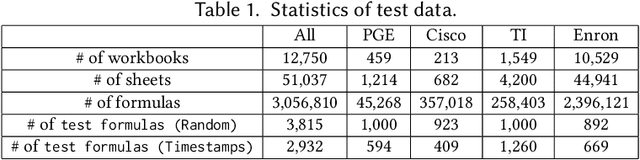
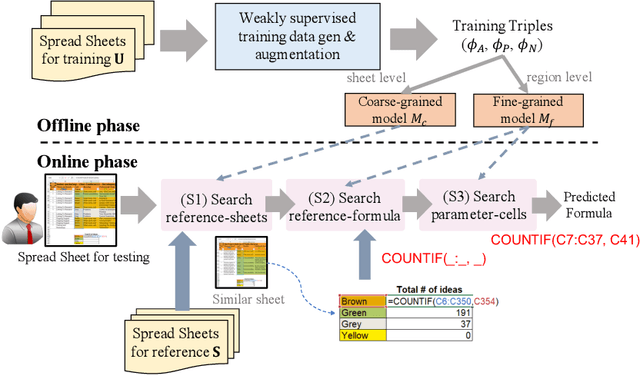

Spreadsheets are widely recognized as the most popular end-user programming tools, which blend the power of formula-based computation, with an intuitive table-based interface. Today, spreadsheets are used by billions of users to manipulate tables, most of whom are neither database experts nor professional programmers. Despite the success of spreadsheets, authoring complex formulas remains challenging, as non-technical users need to look up and understand non-trivial formula syntax. To address this pain point, we leverage the observation that there is often an abundance of similar-looking spreadsheets in the same organization, which not only have similar data, but also share similar computation logic encoded as formulas. We develop an Auto-Formula system that can accurately predict formulas that users want to author in a target spreadsheet cell, by learning and adapting formulas that already exist in similar spreadsheets, using contrastive-learning techniques inspired by "similar-face recognition" from compute vision. Extensive evaluations on over 2K test formulas extracted from real enterprise spreadsheets show the effectiveness of Auto-Formula over alternatives. Our benchmark data is available at https://github.com/microsoft/Auto-Formula to facilitate future research.
Table-GPT: Table-tuned GPT for Diverse Table Tasks
Oct 13, 2023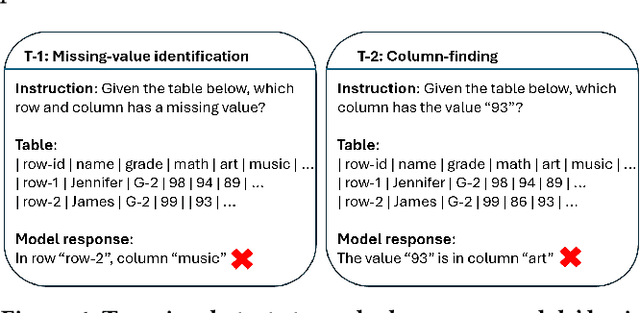
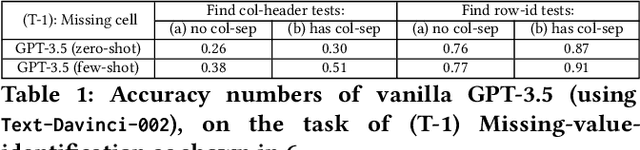

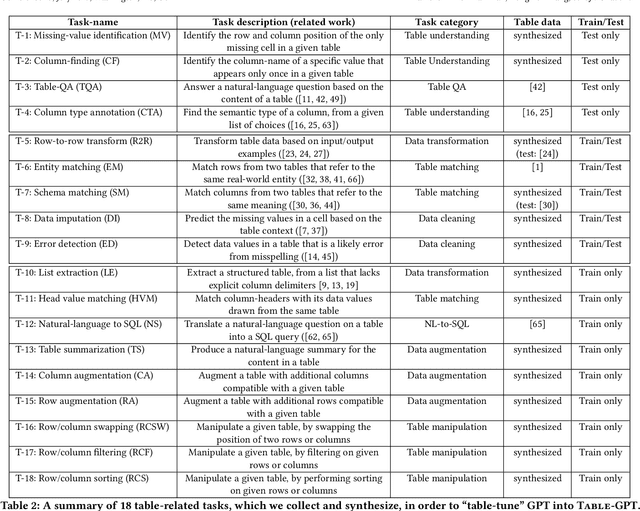
Language models, such as GPT-3.5 and ChatGPT, demonstrate remarkable abilities to follow diverse human instructions and perform a wide range of tasks. However, when probing language models using a range of basic table-understanding tasks, we observe that today's language models are still sub-optimal in many table-related tasks, likely because they are pre-trained predominantly on \emph{one-dimensional} natural-language texts, whereas relational tables are \emph{two-dimensional} objects. In this work, we propose a new "\emph{table-tuning}" paradigm, where we continue to train/fine-tune language models like GPT-3.5 and ChatGPT, using diverse table-tasks synthesized from real tables as training data, with the goal of enhancing language models' ability to understand tables and perform table tasks. We show that our resulting Table-GPT models demonstrate (1) better \emph{table-understanding} capabilities, by consistently outperforming the vanilla GPT-3.5 and ChatGPT, on a wide-range of table tasks, including holdout unseen tasks, and (2) strong \emph{generalizability}, in its ability to respond to diverse human instructions to perform new table-tasks, in a manner similar to GPT-3.5 and ChatGPT.
Auto-Validate by-History: Auto-Program Data Quality Constraints to Validate Recurring Data Pipelines
Jun 04, 2023



Data pipelines are widely employed in modern enterprises to power a variety of Machine-Learning (ML) and Business-Intelligence (BI) applications. Crucially, these pipelines are \emph{recurring} (e.g., daily or hourly) in production settings to keep data updated so that ML models can be re-trained regularly, and BI dashboards refreshed frequently. However, data quality (DQ) issues can often creep into recurring pipelines because of upstream schema and data drift over time. As modern enterprises operate thousands of recurring pipelines, today data engineers have to spend substantial efforts to \emph{manually} monitor and resolve DQ issues, as part of their DataOps and MLOps practices. Given the high human cost of managing large-scale pipeline operations, it is imperative that we can \emph{automate} as much as possible. In this work, we propose Auto-Validate-by-History (AVH) that can automatically detect DQ issues in recurring pipelines, leveraging rich statistics from historical executions. We formalize this as an optimization problem, and develop constant-factor approximation algorithms with provable precision guarantees. Extensive evaluations using 2000 production data pipelines at Microsoft demonstrate the effectiveness and efficiency of AVH.
A Federated Learning Framework for Healthcare IoT devices
May 07, 2020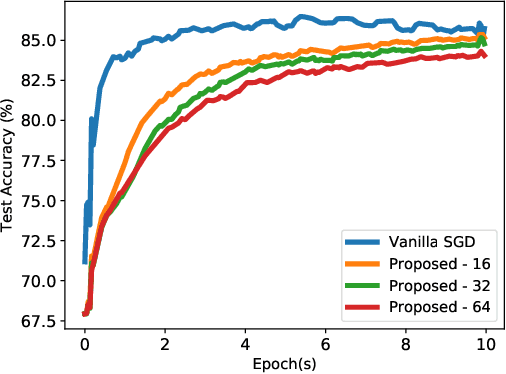

The Internet of Things (IoT) revolution has shown potential to give rise to many medical applications with access to large volumes of healthcare data collected by IoT devices. However, the increasing demand for healthcare data privacy and security makes each IoT device an isolated island of data. Further, the limited computation and communication capacity of wearable healthcare devices restrict the application of vanilla federated learning. To this end, we propose an advanced federated learning framework to train deep neural networks, where the network is partitioned and allocated to IoT devices and a centralized server. Then most of the training computation is handled by the powerful server. The sparsification of activations and gradients significantly reduces the communication overhead. Empirical study have suggested that the proposed framework guarantees a low accuracy loss, while only requiring 0.2% of the synchronization traffic in vanilla federated learning.