 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Test: Learning Semantic-Domain Constraints for Unsupervised Error Detection in Tables
Apr 14, 2025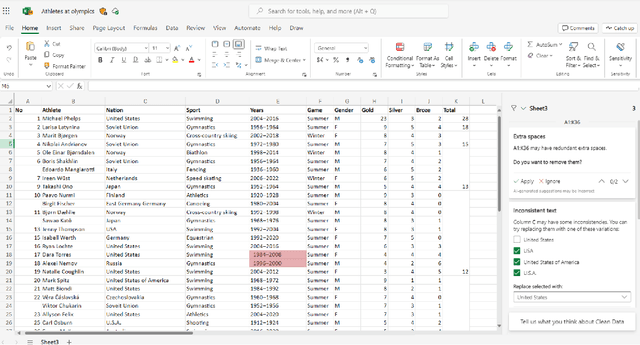
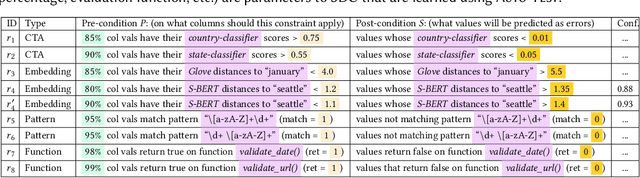


Data cleaning is a long-standing challenge in data management. While powerful logic and statistical algorithms have been developed to detect and repair data errors in tables, existing algorithms predominantly rely on domain-experts to first manually specify data-quality constraints specific to a given table, before data cleaning algorithms can be applied. In this work, we propose a new class of data-quality constraints that we call Semantic-Domain Constraints, which can be reliably inferred and automatically applied to any tables, without requiring domain-experts to manually specify on a per-table basis. We develop a principled framework to systematically learn such constraints from table corpora using large-scale statistical tests, which can further be distilled into a core set of constraints using our optimization framework, with provable quality guarantees. Extensive evaluations show that this new class of constraints can be used to both (1) directly detect errors on real tables in the wild, and (2) augment existing expert-driven data-cleaning techniques as a new class of complementary constraints. Our extensively labeled benchmark dataset with 2400 real data columns, as well as our code are available at https://github.com/qixuchen/AutoTest to facilitate future research.
ReSpark: Leveraging Previous Data Reports as References to Generate New Reports with LLMs
Feb 04, 2025Creating data reports is time-consuming, as it requires iterative exploration and understanding of data, followed by summarizing the insights. While large language models (LLMs) are powerful tools for data processing and text generation, they often struggle to produce complete data reports that fully meet user expectations. One significant challenge is effectively communicating the entire analysis logic to LLMs. Moreover, determining a comprehensive analysis logic can be mentally taxing for users. To address these challenges, we propose ReSpark, an LLM-based method that leverages existing data reports as references for creating new ones. Given a data table, ReSpark searches for similar-topic reports, parses them into interdependent segments corresponding to analytical objectives, and executes them with new data. It identifies inconsistencies and customizes the objectives, data transformations, and textual descriptions. ReSpark allows users to review real-time outputs, insert new objectives, and modify report content. Its effectiveness was evaluated through comparative and user studies.
Modeling the Heterogeneous Duration of User Interest in Time-Dependent Recommendation: A Hidden Semi-Markov Approach
Dec 15, 2024



Recommender systems are widely used for suggesting books, education materials, and products to users by exploring their behaviors. In reality, users' preferences often change over time, leading to studies on time-dependent recommender systems. However, most existing approaches that deal with time information remain primitive. In this paper, we extend existing methods and propose a hidden semi-Markov model to track the change of users' interests. Particularly, this model allows for capturing the different durations of user stays in a (latent) interest state, which can better model the heterogeneity of user interests and focuses. We derive an expectation maximization algorithm to estimate the parameters of the framework and predict users' actions. Experiments on three real-world datasets show that our model significantly outperforms the state-of-the-art time-dependent and static benchmark methods. Further analyses of the experiment results indicate that the performance improvement is related to the heterogeneity of state durations and the drift of user interests in the dataset.
Auto-Formula: Recommend Formulas in Spreadsheets using Contrastive Learning for Table Representations
Apr 19, 2024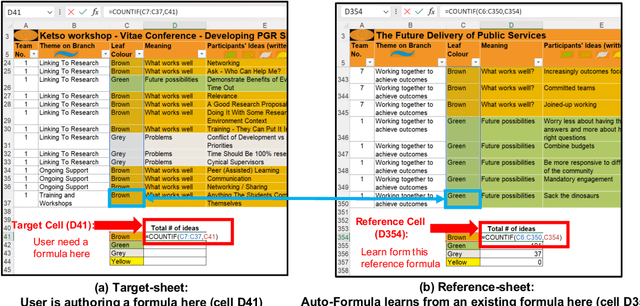
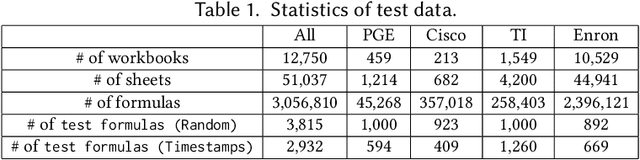
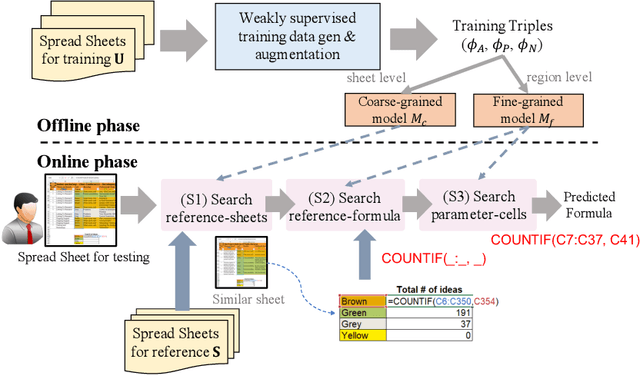

Spreadsheets are widely recognized as the most popular end-user programming tools, which blend the power of formula-based computation, with an intuitive table-based interface. Today, spreadsheets are used by billions of users to manipulate tables, most of whom are neither database experts nor professional programmers. Despite the success of spreadsheets, authoring complex formulas remains challenging, as non-technical users need to look up and understand non-trivial formula syntax. To address this pain point, we leverage the observation that there is often an abundance of similar-looking spreadsheets in the same organization, which not only have similar data, but also share similar computation logic encoded as formulas. We develop an Auto-Formula system that can accurately predict formulas that users want to author in a target spreadsheet cell, by learning and adapting formulas that already exist in similar spreadsheets, using contrastive-learning techniques inspired by "similar-face recognition" from compute vision. Extensive evaluations on over 2K test formulas extracted from real enterprise spreadsheets show the effectiveness of Auto-Formula over alternatives. Our benchmark data is available at https://github.com/microsoft/Auto-Formula to facilitate future research.
NL2Formula: Generating Spreadsheet Formulas from Natural Language Queries
Feb 20, 2024
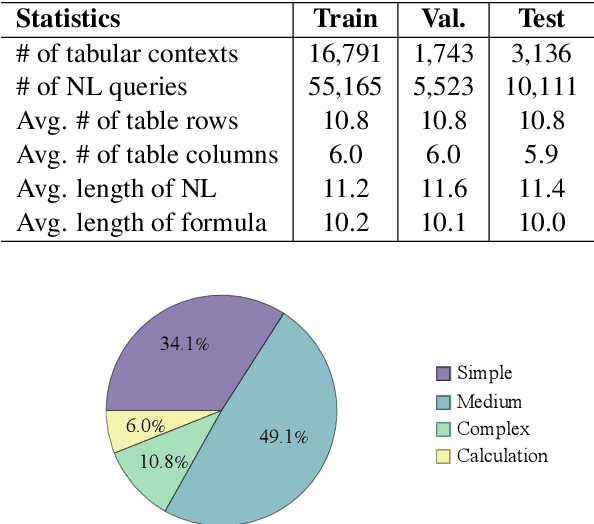
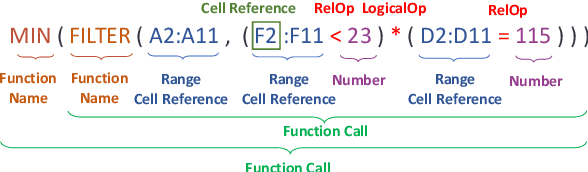
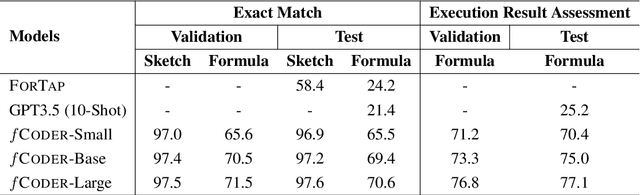
Writing formulas on spreadsheets, such as Microsoft Excel and Google Sheets, is a widespread practice among users performing data analysis. However, crafting formulas on spreadsheets remains a tedious and error-prone task for many end-users, particularly when dealing with complex operations. To alleviate the burden associated with writing spreadsheet formulas, this paper introduces a novel benchmark task called NL2Formula, with the aim to generate executable formulas that are grounded on a spreadsheet table, given a Natural Language (NL) query as input. To accomplish this, we construct a comprehensive dataset consisting of 70,799 paired NL queries and corresponding spreadsheet formulas, covering 21,670 tables and 37 types of formula functions. We realize the NL2Formula task by providing a sequence-to-sequence baseline implementation called fCoder. Experimental results validate the effectiveness of fCoder, demonstrating its superior performance compared to the baseline models. Furthermore, we also compare fCoder with an initial GPT-3.5 model (i.e., text-davinci-003). Lastly, through in-depth error analysis, we identify potential challenges in the NL2Formula task and advocate for further investigation.
Table-GPT: Table-tuned GPT for Diverse Table Tasks
Oct 13, 2023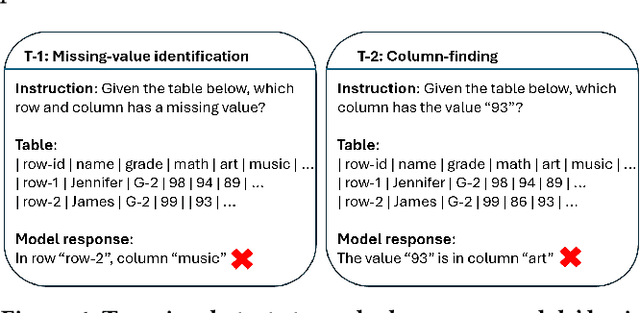
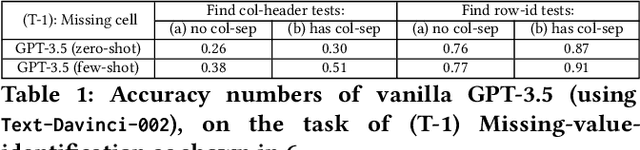

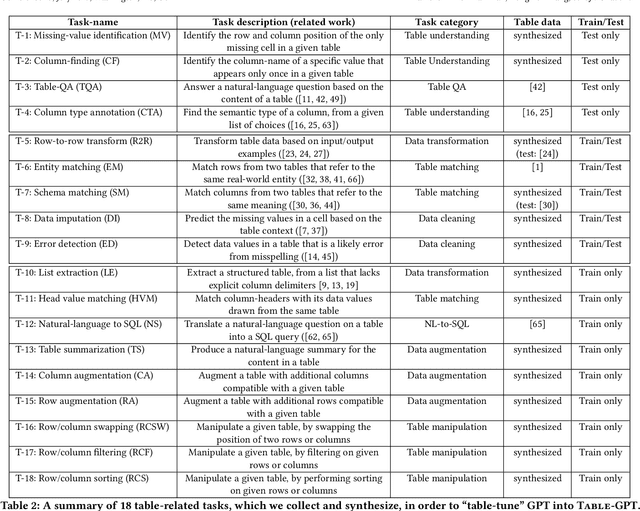
Language models, such as GPT-3.5 and ChatGPT, demonstrate remarkable abilities to follow diverse human instructions and perform a wide range of tasks. However, when probing language models using a range of basic table-understanding tasks, we observe that today's language models are still sub-optimal in many table-related tasks, likely because they are pre-trained predominantly on \emph{one-dimensional} natural-language texts, whereas relational tables are \emph{two-dimensional} objects. In this work, we propose a new "\emph{table-tuning}" paradigm, where we continue to train/fine-tune language models like GPT-3.5 and ChatGPT, using diverse table-tasks synthesized from real tables as training data, with the goal of enhancing language models' ability to understand tables and perform table tasks. We show that our resulting Table-GPT models demonstrate (1) better \emph{table-understanding} capabilities, by consistently outperforming the vanilla GPT-3.5 and ChatGPT, on a wide-range of table tasks, including holdout unseen tasks, and (2) strong \emph{generalizability}, in its ability to respond to diverse human instructions to perform new table-tasks, in a manner similar to GPT-3.5 and ChatGPT.
Auto-Validate by-History: Auto-Program Data Quality Constraints to Validate Recurring Data Pipelines
Jun 04, 2023



Data pipelines are widely employed in modern enterprises to power a variety of Machine-Learning (ML) and Business-Intelligence (BI) applications. Crucially, these pipelines are \emph{recurring} (e.g., daily or hourly) in production settings to keep data updated so that ML models can be re-trained regularly, and BI dashboards refreshed frequently. However, data quality (DQ) issues can often creep into recurring pipelines because of upstream schema and data drift over time. As modern enterprises operate thousands of recurring pipelines, today data engineers have to spend substantial efforts to \emph{manually} monitor and resolve DQ issues, as part of their DataOps and MLOps practices. Given the high human cost of managing large-scale pipeline operations, it is imperative that we can \emph{automate} as much as possible. In this work, we propose Auto-Validate-by-History (AVH) that can automatically detect DQ issues in recurring pipelines, leveraging rich statistics from historical executions. We formalize this as an optimization problem, and develop constant-factor approximation algorithms with provable precision guarantees. Extensive evaluations using 2000 production data pipelines at Microsoft demonstrate the effectiveness and efficiency of AVH.
OneLabeler: A Flexible System for Building Data Labeling Tools
Mar 27, 2022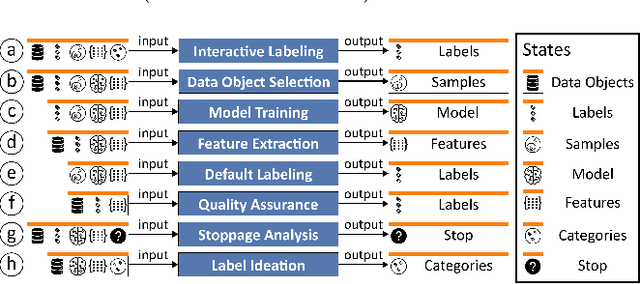

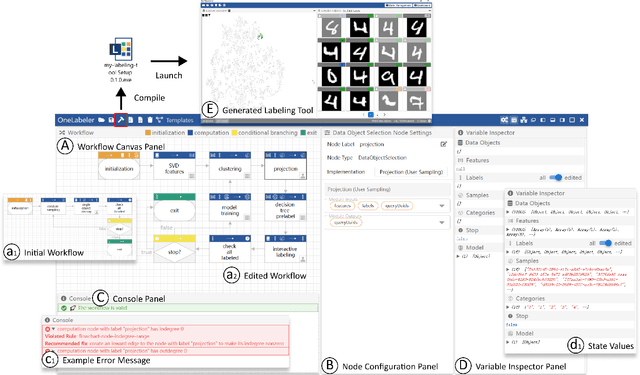
Labeled datasets are essential for supervised machine learning. Various data labeling tools have been built to collect labels in different usage scenarios. However, developing labeling tools is time-consuming, costly, and expertise-demanding on software development. In this paper, we propose a conceptual framework for data labeling and OneLabeler based on the conceptual framework to support easy building of labeling tools for diverse usage scenarios. The framework consists of common modules and states in labeling tools summarized through coding of existing tools. OneLabeler supports configuration and composition of common software modules through visual programming to build data labeling tools. A module can be a human, machine, or mixed computation procedure in data labeling. We demonstrate the expressiveness and utility of the system through ten example labeling tools built with OneLabeler. A user study with developers provides evidence that OneLabeler supports efficient building of diverse data labeling tools.
Neural Text Classification by Jointly Learning to Cluster and Align
Nov 24, 2020
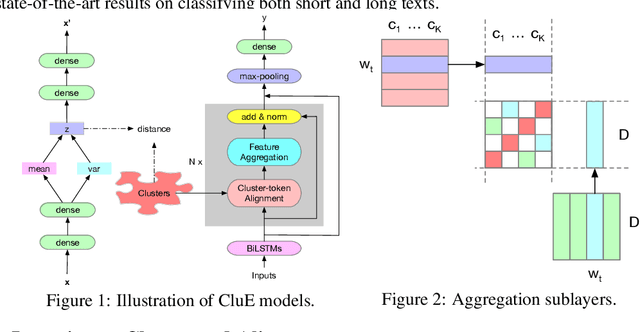
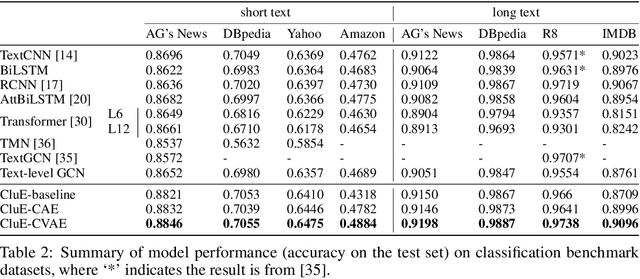

Distributional text clustering delivers semantically informative representations and captures the relevance between each word and semantic clustering centroids. We extend the neural text clustering approach to text classification tasks by inducing cluster centers via a latent variable model and interacting with distributional word embeddings, to enrich the representation of tokens and measure the relatedness between tokens and each learnable cluster centroid. The proposed method jointly learns word clustering centroids and clustering-token alignments, achieving the state of the art results on multiple benchmark datasets and proving that the proposed cluster-token alignment mechanism is indeed favorable to text classification. Notably, our qualitative analysis has conspicuously illustrated that text representations learned by the proposed model are in accord well with our intuition.