 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Priors for Identity-Disentangled Open-Set Privacy-Preserving Video FER
Mar 22, 2026Facial expression recognition relies on facial data that inherently expose identity and thus raise significant privacy concerns. Current privacy-preserving methods typically fail in realistic open-set video settings where identities are unknown, and identity labels are unavailable. We propose a two-stage framework for video-based privacy-preserving FER in challenging open-set settings that requires no identity labels at any stage. To decouple privacy and utility, we first train an identity-suppression network using intra- and inter-video knowledge priors derived from real-world videos without identity labels. This network anonymizes identity while preserving expressive cues. A subsequent denoising module restores expression-related information and helps recover FER performance. Furthermore, we introduce a falsification-based validation method that uses recognition priors to rigorously evaluate privacy robustness without requiring annotated identity labels. Experiments on three video datasets demonstrate that our method effectively protects privacy while maintaining FER accuracy comparable to identity-supervised baselines.
DeMark: A Query-Free Black-Box Attack on Deepfake Watermarking Defenses
Jan 23, 2026The rapid proliferation of realistic deepfakes has raised urgent concerns over their misuse, motivating the use of defensive watermarks in synthetic images for reliable detection and provenance tracking. However, this defense paradigm assumes such watermarks are inherently resistant to removal. We challenge this assumption with DeMark, a query-free black-box attack framework that targets defensive image watermarking schemes for deepfakes. DeMark exploits latent-space vulnerabilities in encoder-decoder watermarking models through a compressive sensing based sparsification process, suppressing watermark signals while preserving perceptual and structural realism appropriate for deepfakes. Across eight state-of-the-art watermarking schemes, DeMark reduces watermark detection accuracy from 100% to 32.9% on average while maintaining natural visual quality, outperforming existing attacks. We further evaluate three defense strategies, including image super resolution, sparse watermarking, and adversarial training, and find them largely ineffective. These results demonstrate that current encoder decoder watermarking schemes remain vulnerable to latent-space manipulations, underscoring the need for more robust watermarking methods to safeguard against deepfakes.
MetaLogic: Robustness Evaluation of Text-to-Image Models via Logically Equivalent Prompts
Oct 01, 2025Recent advances in text-to-image (T2I) models, especially diffusion-based architectures, have significantly improved the visual quality of generated images. However, these models continue to struggle with a critical limitation: maintaining semantic consistency when input prompts undergo minor linguistic variations. Despite being logically equivalent, such prompt pairs often yield misaligned or semantically inconsistent images, exposing a lack of robustness in reasoning and generalisation. To address this, we propose MetaLogic, a novel evaluation framework that detects T2I misalignment without relying on ground truth images. MetaLogic leverages metamorphic testing, generating image pairs from prompts that differ grammatically but are semantically identical. By directly comparing these image pairs, the framework identifies inconsistencies that signal failures in preserving the intended meaning, effectively diagnosing robustness issues in the model's logic understanding. Unlike existing evaluation methods that compare a generated image to a single prompt, MetaLogic evaluates semantic equivalence between paired images, offering a scalable, ground-truth-free approach to identifying alignment failures. It categorises these alignment errors (e.g., entity omission, duplication, positional misalignment) and surfaces counterexamples that can be used for model debugging and refinement. We evaluate MetaLogic across multiple state-of-the-art T2I models and reveal consistent robustness failures across a range of logical constructs. We find that even the SOTA text-to-image models like Flux.dev and DALLE-3 demonstrate a 59 percent and 71 percent misalignment rate, respectively. Our results show that MetaLogic is not only efficient and scalable, but also effective in uncovering fine-grained logical inconsistencies that are overlooked by existing evaluation metrics.
Efficient Neural Network Verification via Order Leading Exploration of Branch-and-Bound Trees
Jul 23, 2025The vulnerability of neural networks to adversarial perturbations has necessitated formal verification techniques that can rigorously certify the quality of neural networks. As the state-of-the-art, branch and bound (BaB) is a "divide-and-conquer" strategy that applies off-the-shelf verifiers to sub-problems for which they perform better. While BaB can identify the sub-problems that are necessary to be split, it explores the space of these sub-problems in a naive "first-come-first-serve" manner, thereby suffering from an issue of inefficiency to reach a verification conclusion. To bridge this gap, we introduce an order over different sub-problems produced by BaB, concerning with their different likelihoods of containing counterexamples. Based on this order, we propose a novel verification framework Oliva that explores the sub-problem space by prioritizing those sub-problems that are more likely to find counterexamples, in order to efficiently reach the conclusion of the verification. Even if no counterexample can be found in any sub-problem, it only changes the order of visiting different sub-problem and so will not lead to a performance degradation. Specifically, Oliva has two variants, including $Oliva^{GR}$, a greedy strategy that always prioritizes the sub-problems that are more likely to find counterexamples, and $Oliva^{SA}$, a balanced strategy inspired by simulated annealing that gradually shifts from exploration to exploitation to locate the globally optimal sub-problems. We experimentally evaluate the performance of Oliva on 690 verification problems spanning over 5 models with datasets MNIST and CIFAR10. Compared to the state-of-the-art approaches, we demonstrate the speedup of Oliva for up to 25X in MNIST, and up to 80X in CIFAR10.
Adaptive Branch-and-Bound Tree Exploration for Neural Network Verification
May 02, 2025Formal verification is a rigorous approach that can provably ensure the quality of neural networks, and to date, Branch and Bound (BaB) is the state-of-the-art that performs verification by splitting the problem as needed and applying off-the-shelf verifiers to sub-problems for improved performance. However, existing BaB may not be efficient, due to its naive way of exploring the space of sub-problems that ignores the \emph{importance} of different sub-problems. To bridge this gap, we first introduce a notion of ``importance'' that reflects how likely a counterexample can be found with a sub-problem, and then we devise a novel verification approach, called ABONN, that explores the sub-problem space of BaB adaptively, in a Monte-Carlo tree search (MCTS) style. The exploration is guided by the ``importance'' of different sub-problems, so it favors the sub-problems that are more likely to find counterexamples. As soon as it finds a counterexample, it can immediately terminate; even though it cannot find, after visiting all the sub-problems, it can still manage to verify the problem. We evaluate ABONN with 552 verification problems from commonly-used datasets and neural network models, and compare it with the state-of-the-art verifiers as baseline approaches. Experimental evaluation shows that ABONN demonstrates speedups of up to $15.2\times$ on MNIST and $24.7\times$ on CIFAR-10. We further study the influences of hyperparameters to the performance of ABONN, and the effectiveness of our adaptive tree exploration.
CGP-Tuning: Structure-Aware Soft Prompt Tuning for Code Vulnerability Detection
Jan 08, 2025Large language models (LLMs) have been proposed as powerful tools for detecting software vulnerabilities, where task-specific fine-tuning is typically employed to provide vulnerability-specific knowledge to the LLMs for this purpose. However, traditional full-parameter fine-tuning is inefficient for modern, complex LLMs, which contain billions of parameters. Soft prompt tuning has been suggested as a more efficient alternative for fine-tuning LLMs in general cases. However, pure soft prompt tuning treats source code as plain text, losing structural information inherent in source code. Meanwhile, graph-enhanced soft prompt tuning methods, which aim to address this issue, are unable to preserve the rich semantic information within code graphs, as they are primarily designed for general graph-related tasks and focus more on adjacency information. They also fail to ensure computational efficiency while accounting for graph-text interactions. This paper, therefore, introduces a new code graph-enhanced, structure-aware soft prompt tuning method for vulnerability detection, referred to as CGP-Tuning. It employs innovative type-aware embeddings to capture the rich semantic information within code graphs, along with a novel and efficient cross-modal alignment module that achieves linear computational cost while incorporating graph-text interactions. The proposed CGP-Tuning is evaluated on the latest DiverseVul dataset and the most recent open-source code LLMs, CodeLlama and CodeGemma. Experimental results demonstrate that CGP-Tuning outperforms the best state-of-the-art method by an average of 3.5 percentage points in accuracy, without compromising its vulnerability detection capabilities for long source code.
Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study
Apr 26, 2024The Natural Language to Visualization (NL2Vis) task aims to transform natural-language descriptions into visual representations for a grounded table, enabling users to gain insights from vast amounts of data. Recently, many deep learning-based approaches have been developed for NL2Vis. Despite the considerable efforts made by these approaches, challenges persist in visualizing data sourced from unseen databases or spanning multiple tables. Taking inspiration from the remarkable generation capabilities of Large Language Models (LLMs), this paper conducts an empirical study to evaluate their potential in generating visualizations, and explore the effectiveness of in-context learning prompts for enhancing this task. In particular, we first explore the ways of transforming structured tabular data into sequential text prompts, as to feed them into LLMs and analyze which table content contributes most to the NL2Vis. Our findings suggest that transforming structured tabular data into programs is effective, and it is essential to consider the table schema when formulating prompts. Furthermore, we evaluate two types of LLMs: finetuned models (e.g., T5-Small) and inference-only models (e.g., GPT-3.5), against state-of-the-art methods, using the NL2Vis benchmarks (i.e., nvBench). The experimental results reveal that LLMs outperform baselines, with inference-only models consistently exhibiting performance improvements, at times even surpassing fine-tuned models when provided with certain few-shot demonstrations through in-context learning. Finally, we analyze when the LLMs fail in NL2Vis, and propose to iteratively update the results using strategies such as chain-of-thought, role-playing, and code-interpreter. The experimental results confirm the efficacy of iterative updates and hold great potential for future study.
CodeIP: A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code
Apr 24, 2024



As Large Language Models (LLMs) are increasingly used to automate code generation, it is often desired to know if the code is AI-generated and by which model, especially for purposes like protecting intellectual property (IP) in industry and preventing academic misconduct in education. Incorporating watermarks into machine-generated content is one way to provide code provenance, but existing solutions are restricted to a single bit or lack flexibility. We present CodeIP, a new watermarking technique for LLM-based code generation. CodeIP enables the insertion of multi-bit information while preserving the semantics of the generated code, improving the strength and diversity of the inerseted watermark. This is achieved by training a type predictor to predict the subsequent grammar type of the next token to enhance the syntactical and semantic correctness of the generated code. Experiments on a real-world dataset across five programming languages showcase the effectiveness of CodeIP.
Graph Neural Networks for Vulnerability Detection: A Counterfactual Explanation
Apr 24, 2024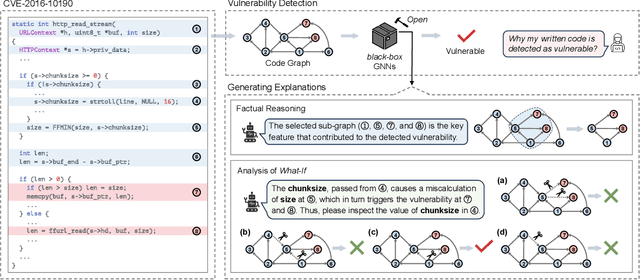
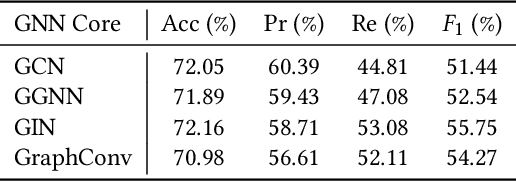
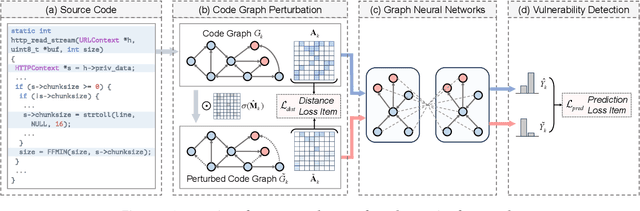
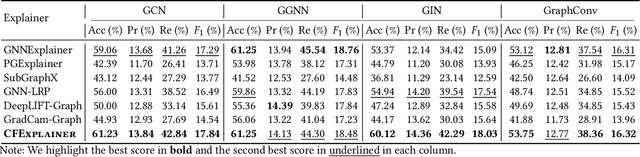
Vulnerability detection is crucial for ensuring the security and reliability of software systems. Recently, Graph Neural Networks (GNNs) have emerged as a prominent code embedding approach for vulnerability detection, owing to their ability to capture the underlying semantic structure of source code. However, GNNs face significant challenges in explainability due to their inherently black-box nature. To this end, several factual reasoning-based explainers have been proposed. These explainers provide explanations for the predictions made by GNNs by analyzing the key features that contribute to the outcomes. We argue that these factual reasoning-based explanations cannot answer critical what-if questions: What would happen to the GNN's decision if we were to alter the code graph into alternative structures? Inspired by advancements of counterfactual reasoning in artificial intelligence, we propose CFExplainer, a novel counterfactual explainer for GNN-based vulnerability detection. Unlike factual reasoning-based explainers, CFExplainer seeks the minimal perturbation to the input code graph that leads to a change in the prediction, thereby addressing the what-if questions for vulnerability detection. We term this perturbation a counterfactual explanation, which can pinpoint the root causes of the detected vulnerability and furnish valuable insights for developers to undertake appropriate actions for fixing the vulnerability. Extensive experiments on four GNN-based vulnerability detection models demonstrate the effectiveness of CFExplainer over existing state-of-the-art factual reasoning-based explainers.
Does Your Neural Code Completion Model Use My Code? A Membership Inference Approach
Apr 22, 2024



Recent years have witnessed significant progress in developing deep learning-based models for automated code completion. Although using source code in GitHub has been a common practice for training deep-learning-based models for code completion, it may induce some legal and ethical issues such as copyright infringement. In this paper, we investigate the legal and ethical issues of current neural code completion models by answering the following question: Is my code used to train your neural code completion model? To this end, we tailor a membership inference approach (termed CodeMI) that was originally crafted for classification tasks to a more challenging task of code completion. In particular, since the target code completion models perform as opaque black boxes, preventing access to their training data and parameters, we opt to train multiple shadow models to mimic their behavior. The acquired posteriors from these shadow models are subsequently employed to train a membership classifier. Subsequently, the membership classifier can be effectively employed to deduce the membership status of a given code sample based on the output of a target code completion model. We comprehensively evaluate the effectiveness of this adapted approach across a diverse array of neural code completion models, (i.e., LSTM-based, CodeGPT, CodeGen, and StarCoder). Experimental results reveal that the LSTM-based and CodeGPT models suffer the membership leakage issue, which can be easily detected by our proposed membership inference approach with an accuracy of 0.842, and 0.730, respectively. Interestingly, our experiments also show that the data membership of current large language models of code, e.g., CodeGen and StarCoder, is difficult to detect, leaving amper space for further improvement. Finally, we also try to explain the findings from the perspective of model memorization.