 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokeGym: A Visually-Driven Long-Horizon Benchmark for Vision-Language Models
Apr 09, 2026While Vision-Language Models (VLMs) have achieved remarkable progress in static visual understanding, their deployment in complex 3D embodied environments remains severely limited. Existing benchmarks suffer from four critical deficiencies: (1) passive perception tasks circumvent interactive dynamics; (2) simplified 2D environments fail to assess depth perception; (3) privileged state leakage bypasses genuine visual processing; and (4) human evaluation is prohibitively expensive and unscalable. We introduce PokeGym, a visually-driven long-horizon benchmark instantiated within Pokemon Legends: Z-A, a visually complex 3D open-world Role-Playing Game. PokeGym enforces strict code-level isolation: agents operate solely on raw RGB observations while an independent evaluator verifies success via memory scanning, ensuring pure vision-based decision-making and automated, scalable assessment. The benchmark comprises 30 tasks (30-220 steps) spanning navigation, interaction, and mixed scenarios, with three instruction granularities (Visual-Guided, Step-Guided, Goal-Only) to systematically deconstruct visual grounding, semantic reasoning, and autonomous exploration capabilities. Our evaluation reveals a key limitation of current VLMs: physical deadlock recovery, rather than high-level planning, constitutes the primary bottleneck, with deadlocks showing a strong negative correlation with task success. Furthermore, we uncover a metacognitive divergence: weaker models predominantly suffer from Unaware Deadlocks (oblivious to entrapment), whereas advanced models exhibit Aware Deadlocks (recognizing entrapment yet failing to recover). These findings highlight the need to integrate explicit spatial intuition into VLM architectures. The code and benchmark will be available on GitHub.
The Reward Model Selection Crisis in Personalized Alignment
Dec 28, 2025Personalized alignment from preference data has focused primarily on improving reward model (RM) accuracy, with the implicit assumption that better preference ranking translates to better personalized behavior. However, in deployment, computational constraints necessitate inference-time adaptation via reward-guided decoding (RGD) rather than per-user policy fine-tuning. This creates a critical but overlooked requirement: reward models must not only rank preferences accurately but also effectively guide token-level generation decisions. We demonstrate that standard RM accuracy fails catastrophically as a selection criterion for deployment-ready personalized alignment. Through systematic evaluation across three datasets, we introduce policy accuracy, a metric quantifying whether RGD scoring functions correctly discriminate between preferred and dispreferred responses. We show that RM accuracy correlates only weakly with this policy-level discrimination ability (Kendall's tau = 0.08--0.31). More critically, we introduce Pref-LaMP, the first personalized alignment benchmark with ground-truth user completions, enabling direct behavioral evaluation without circular reward-based metrics. On Pref-LaMP, we expose a complete decoupling between discrimination and generation: methods with 20-point RM accuracy differences produce almost identical output quality, and even methods achieving high discrimination fail to generate behaviorally aligned responses. Finally, simple in-context learning (ICL) dominates all reward-guided methods for models > 3B parameters, achieving 3-5 point ROUGE-1 gains over the best reward method at 7B scale. These findings show that the field optimizes proxy metrics that fail to predict deployment performance and do not translate preferences into real behavioral adaptation under deployment constraints.
Branches, Assemble! Multi-Branch Cooperation Network for Large-Scale Click-Through Rate Prediction at Taobao
Nov 20, 2024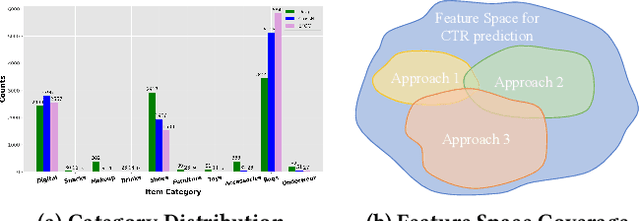
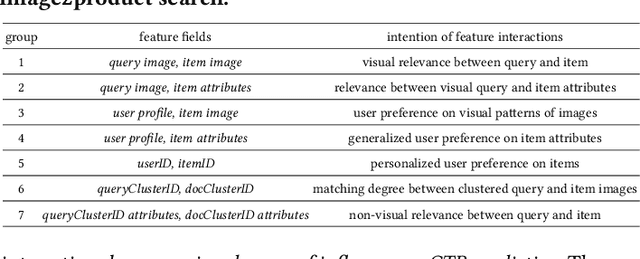
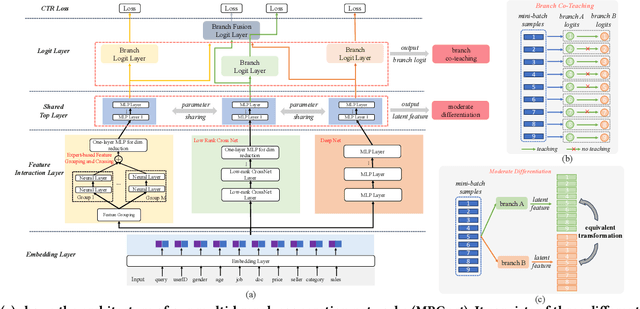

Existing click-through rate (CTR) prediction works have studied the role of feature interaction through a variety of techniques. Each interaction technique exhibits its own strength, and solely using one type could constrain the model's capability to capture the complex feature relationships, especially for industrial large-scale data with enormous users and items. Recent research shows that effective CTR models often combine an MLP network with a dedicated feature interaction network in a two-parallel structure. However, the interplay and cooperative dynamics between different streams or branches remain under-researched. In this work, we introduce a novel Multi-Branch Cooperation Network (MBCnet) which enables multiple branch networks to collaborate with each other for better complex feature interaction modeling. Specifically, MBCnet consists of three branches: the Expert-based Feature Grouping and Crossing (EFGC) branch that promotes the model's memorization ability of specific feature fields, the low rank Cross Net branch and Deep branch to enhance both explicit and implicit feature crossing for improved generalization. Among branches, a novel cooperation scheme is proposed based on two principles: branch co-teaching and moderate differentiation. Branch co-teaching encourages well-learned branches to support poorly-learned ones on specific training samples. Moderate differentiation advocates branches to maintain a reasonable level of difference in their feature representations. The cooperation strategy improves learning through mutual knowledge sharing via co-teaching and boosts the discovery of diverse feature interactions across branches. Extensive experiments on large-scale industrial datasets and online A/B test demonstrate MBCnet's superior performance, delivering a 0.09 point increase in CTR, 1.49% growth in deals, and 1.62% rise in GMV. Core codes will be released soon.
Alpha and Prejudice: Improving $α$-sized Worst-case Fairness via Intrinsic Reweighting
Nov 05, 2024Worst-case fairness with off-the-shelf demographics achieves group parity by maximizing the model utility of the worst-off group. Nevertheless, demographic information is often unavailable in practical scenarios, which impedes the use of such a direct max-min formulation. Recent advances have reframed this learning problem by introducing the lower bound of minimal partition ratio, denoted as $\alpha$, as side information, referred to as ``$\alpha$-sized worst-case fairness'' in this paper. We first justify the practical significance of this setting by presenting noteworthy evidence from the data privacy perspective, which has been overlooked by existing research. Without imposing specific requirements on loss functions, we propose reweighting the training samples based on their intrinsic importance to fairness. Given the global nature of the worst-case formulation, we further develop a stochastic learning scheme to simplify the training process without compromising model performance. Additionally, we address the issue of outliers and provide a robust variant to handle potential outliers during model training. Our theoretical analysis and experimental observations reveal the connections between the proposed approaches and existing ``fairness-through-reweighting'' studies, with extensive experimental results on fairness benchmarks demonstrating the superiority of our methods.
PROUD: PaRetO-gUided Diffusion Model for Multi-objective Generation
Jul 05, 2024Recent advancements in the realm of deep generative models focus on generating samples that satisfy multiple desired properties. However, prevalent approaches optimize these property functions independently, thus omitting the trade-offs among them. In addition, the property optimization is often improperly integrated into the generative models, resulting in an unnecessary compromise on generation quality (i.e., the quality of generated samples). To address these issues, we formulate a constrained optimization problem. It seeks to optimize generation quality while ensuring that generated samples reside at the Pareto front of multiple property objectives. Such a formulation enables the generation of samples that cannot be further improved simultaneously on the conflicting property functions and preserves good quality of generated samples. Building upon this formulation, we introduce the PaRetO-gUided Diffusion model (PROUD), wherein the gradients in the denoising process are dynamically adjusted to enhance generation quality while the generated samples adhere to Pareto optimality. Experimental evaluations on image generation and protein generation tasks demonstrate that our PROUD consistently maintains superior generation quality while approaching Pareto optimality across multiple property functions compared to various baselines.
Sanitized Clustering against Confounding Bias
Nov 02, 2023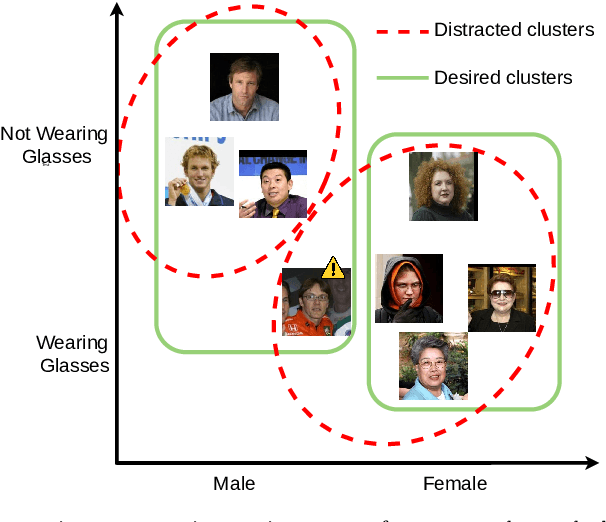
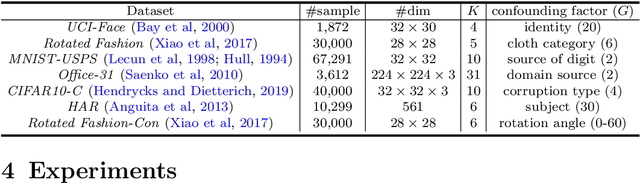
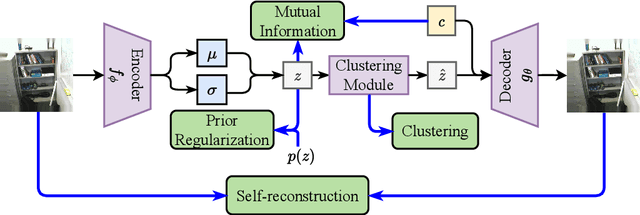
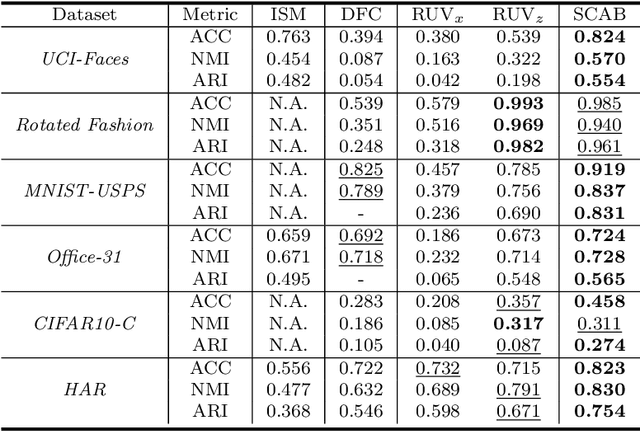
Real-world datasets inevitably contain biases that arise from different sources or conditions during data collection. Consequently, such inconsistency itself acts as a confounding factor that disturbs the cluster analysis. Existing methods eliminate the biases by projecting data onto the orthogonal complement of the subspace expanded by the confounding factor before clustering. Therein, the interested clustering factor and the confounding factor are coarsely considered in the raw feature space, where the correlation between the data and the confounding factor is ideally assumed to be linear for convenient solutions. These approaches are thus limited in scope as the data in real applications is usually complex and non-linearly correlated with the confounding factor. This paper presents a new clustering framework named Sanitized Clustering Against confounding Bias (SCAB), which removes the confounding factor in the semantic latent space of complex data through a non-linear dependence measure. To be specific, we eliminate the bias information in the latent space by minimizing the mutual information between the confounding factor and the latent representation delivered by Variational Auto-Encoder (VAE). Meanwhile, a clustering module is introduced to cluster over the purified latent representations. Extensive experiments on complex datasets demonstrate that our SCAB achieves a significant gain in clustering performance by removing the confounding bias. The code is available at \url{https://github.com/EvaFlower/SCAB}.
Earning Extra Performance from Restrictive Feedbacks
Apr 28, 2023Many machine learning applications encounter a situation where model providers are required to further refine the previously trained model so as to gratify the specific need of local users. This problem is reduced to the standard model tuning paradigm if the target data is permissibly fed to the model. However, it is rather difficult in a wide range of practical cases where target data is not shared with model providers but commonly some evaluations about the model are accessible. In this paper, we formally set up a challenge named \emph{Earning eXtra PerformancE from restriCTive feEDdbacks} (EXPECTED) to describe this form of model tuning problems. Concretely, EXPECTED admits a model provider to access the operational performance of the candidate model multiple times via feedback from a local user (or a group of users). The goal of the model provider is to eventually deliver a satisfactory model to the local user(s) by utilizing the feedbacks. Unlike existing model tuning methods where the target data is always ready for calculating model gradients, the model providers in EXPECTED only see some feedbacks which could be as simple as scalars, such as inference accuracy or usage rate. To enable tuning in this restrictive circumstance, we propose to characterize the geometry of the model performance with regard to model parameters through exploring the parameters' distribution. In particular, for the deep models whose parameters distribute across multiple layers, a more query-efficient algorithm is further tailor-designed that conducts layerwise tuning with more attention to those layers which pay off better. Our theoretical analyses justify the proposed algorithms from the aspects of both efficacy and efficiency. Extensive experiments on different applications demonstrate that our work forges a sound solution to the EXPECTED problem.
Coarse-to-Fine Contrastive Learning on Graphs
Dec 13, 2022



Inspired by the impressive success of contrastive learning (CL), a variety of graph augmentation strategies have been employed to learn node representations in a self-supervised manner. Existing methods construct the contrastive samples by adding perturbations to the graph structure or node attributes. Although impressive results are achieved, it is rather blind to the wealth of prior information assumed: with the increase of the perturbation degree applied on the original graph, 1) the similarity between the original graph and the generated augmented graph gradually decreases; 2) the discrimination between all nodes within each augmented view gradually increases. In this paper, we argue that both such prior information can be incorporated (differently) into the contrastive learning paradigm following our general ranking framework. In particular, we first interpret CL as a special case of learning to rank (L2R), which inspires us to leverage the ranking order among positive augmented views. Meanwhile, we introduce a self-ranking paradigm to ensure that the discriminative information among different nodes can be maintained and also be less altered to the perturbations of different degrees. Experiment results on various benchmark datasets verify the effectiveness of our algorithm compared with the supervised and unsupervised models.
Taming Overconfident Prediction on Unlabeled Data from Hindsight
Dec 15, 2021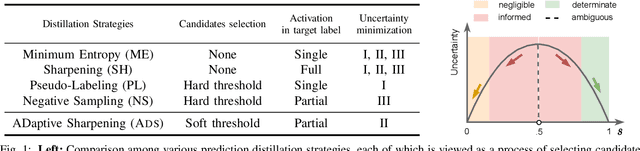
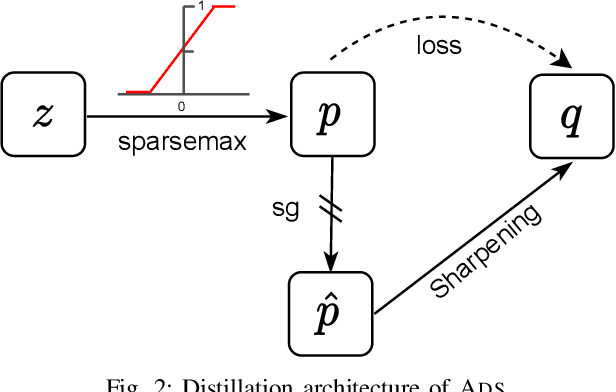
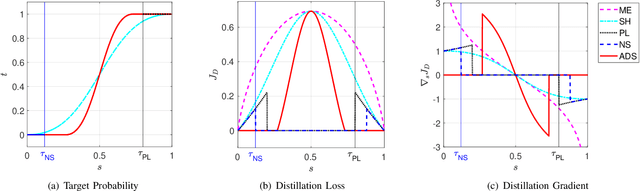
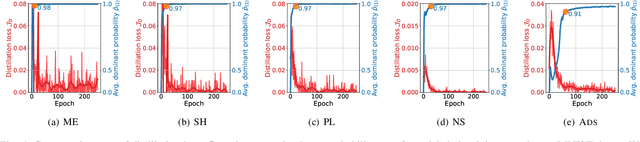
Minimizing prediction uncertainty on unlabeled data is a key factor to achieve good performance in semi-supervised learning (SSL). The prediction uncertainty is typically expressed as the \emph{entropy} computed by the transformed probabilities in output space. Most existing works distill low-entropy prediction by either accepting the determining class (with the largest probability) as the true label or suppressing subtle predictions (with the smaller probabilities). Unarguably, these distillation strategies are usually heuristic and less informative for model training. From this discernment, this paper proposes a dual mechanism, named ADaptive Sharpening (\ADS), which first applies a soft-threshold to adaptively mask out determinate and negligible predictions, and then seamlessly sharpens the informed predictions, distilling certain predictions with the informed ones only. More importantly, we theoretically analyze the traits of \ADS by comparing with various distillation strategies. Numerous experiments verify that \ADS significantly improves the state-of-the-art SSL methods by making it a plug-in. Our proposed \ADS forges a cornerstone for future distillation-based SSL research.
TRIP: Refining Image-to-Image Translation via Rival Preferences
Nov 26, 2021

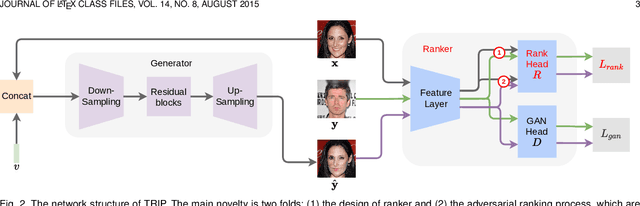
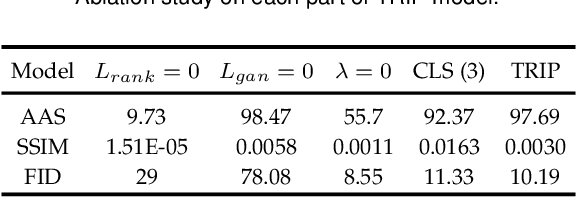
Relative attribute (RA), referring to the preference over two images on the strength of a specific attribute, can enable fine-grained image-to-image translation due to its rich semantic information. Existing work based on RAs however failed to reconcile the goal for fine-grained translation and the goal for high-quality generation. We propose a new model TRIP to coordinate these two goals for high-quality fine-grained translation. In particular, we simultaneously train two modules: a generator that translates an input image to the desired image with smooth subtle changes with respect to the interested attributes; and a ranker that ranks rival preferences consisting of the input image and the desired image. Rival preferences refer to the adversarial ranking process: (1) the ranker thinks no difference between the desired image and the input image in terms of the desired attributes; (2) the generator fools the ranker to believe that the desired image changes the attributes over the input image as desired. RAs over pairs of real images are introduced to guide the ranker to rank image pairs regarding the interested attributes only. With an effective ranker, the generator would "win" the adversarial game by producing high-quality images that present desired changes over the attributes compared to the input image. The experiments on two face image datasets and one shoe image dataset demonstrate that our TRIP achieves state-of-art results in generating high-fidelity images which exhibit smooth changes over the interested attributes.