 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIKNO: Infinite-order Kernel Neural Operators
May 21, 2026Neural operators have achieved significant success in modern scientific computing due to their flexibility and strong generalization capabilities. Existing models, however, primarily rely on first-order kernel integral approximations, which severely limit their expressivity. To address this, we propose the Infinite-order Kernel Neural Operator (IKNO), which constructs neural operators via infinite-order kernel integrals and admits an elegant closed-form finite approximation. We develop two complementary infinite-order neural operator constructions: IKNO-Vanilla, which applies the full-kernel resolvent on the product grid via Kronecker eigendecomposition, and IKNO-TP, an alternative tensor-product operator that composes per-axis resolvents. Furthermore, we develop fast computation schemes for both variants of IKNO, which achieve outstanding global information aggregation while maintaining high computational efficiency. Empirically, we evaluate our IKNO on both time-dependent and time-independent benchmarks with arbitrary input shapes, including large-scale industrial datasets. Extensive experiments demonstrate that the IKNO method consistently achieves the SOTA accuracy with significant improvements on nearly all benchmark datasets while maintaining scalability to very large point clouds.
RADAR: Defending RAG Dynamically against Retrieval Corruption
May 21, 2026While RAG systems are increasingly deployed in dynamic web search, temporal volatility amplifies their vulnerability to adversarial attacks. Existing static-oriented defenses struggle to handle evolving threats and incur prohibitive storage costs in dynamic settings. We propose RADAR, a framework that models reliable context selection as a graph-based energy minimization problem, solved exactly via Max-Flow Min-Cut. By incorporating a Bayesian memory node, RADAR recursively updates a belief state instead of archiving raw historical documents, effectively balancing stability against attacks with adaptability to genuine knowledge shifts. Experiments on a novel dynamic dataset show that RADAR achieves superior robustness and response quality with minimal storage overhead compared to the baselines.
Uncertainty-Aware Concept and Motion Segmentation for Semi-Supervised Angiography Videos
Mar 01, 2026Segmentation of the main coronary artery from X-ray coronary angiography (XCA) sequences is crucial for the diagnosis of coronary artery diseases. However, this task is challenging due to issues such as blurred boundaries, inconsistent radiation contrast, complex motion patterns, and a lack of annotated images for training. Although Semi-Supervised Learning (SSL) can alleviate the annotation burden, conventional methods struggle with complicated temporal dynamics and unreliable uncertainty quantification. To address these challenges, we propose SAM3-based Teacher-student framework with Motion-Aware consistency and Progressive Confidence Regularization (SMART), a semi-supervised vessel segmentation approach for X-ray angiography videos. First, our method utilizes SAM3's unique promptable concept segmentation design and innovates a SAM3-based teacher-student framework to maximize the performance potential of both the teacher and the student. Second, we enhance segmentation by integrating the vessel mask warping technique and motion consistency loss to model complex vessel dynamics. To address the issue of unreliable teacher predictions caused by blurred boundaries and minimal contrast, we further propose a progressive confidence-aware consistency regularization to mitigate the risk of unreliable outputs. Extensive experiments on three datasets of XCA sequences from different institutions demonstrate that SMART achieves state-of-the-art performance while requiring significantly fewer annotations, making it particularly valuable for real-world clinical applications where labeled data is scarce. Our code is available at: https://github.com/qimingfan10/SMART.
Confundo: Learning to Generate Robust Poison for Practical RAG Systems
Feb 06, 2026Retrieval-augmented generation (RAG) is increasingly deployed in real-world applications, where its reference-grounded design makes outputs appear trustworthy. This trust has spurred research on poisoning attacks that craft malicious content, inject it into knowledge sources, and manipulate RAG responses. However, when evaluated in practical RAG systems, existing attacks suffer from severely degraded effectiveness. This gap stems from two overlooked realities: (i) content is often processed before use, which can fragment the poison and weaken its effect, and (ii) users often do not issue the exact queries anticipated during attack design. These factors can lead practitioners to underestimate risks and develop a false sense of security. To better characterize the threat to practical systems, we present Confundo, a learning-to-poison framework that fine-tunes a large language model as a poison generator to achieve high effectiveness, robustness, and stealthiness. Confundo provides a unified framework supporting multiple attack objectives, demonstrated by manipulating factual correctness, inducing biased opinions, and triggering hallucinations. By addressing these overlooked challenges, Confundo consistently outperforms a wide range of purpose-built attacks across datasets and RAG configurations by large margins, even in the presence of defenses. Beyond exposing vulnerabilities, we also present a defensive use case that protects web content from unauthorized incorporation into RAG systems via scraping, with no impact on user experience.
Exposing and Defending the Achilles' Heel of Video Mixture-of-Experts
Feb 01, 2026Mixture-of-Experts (MoE) has demonstrated strong performance in video understanding tasks, yet its adversarial robustness remains underexplored. Existing attack methods often treat MoE as a unified architecture, overlooking the independent and collaborative weaknesses of key components such as routers and expert modules. To fill this gap, we propose Temporal Lipschitz-Guided Attacks (TLGA) to thoroughly investigate component-level vulnerabilities in video MoE models. We first design attacks on the router, revealing its independent weaknesses. Building on this, we introduce Joint Temporal Lipschitz-Guided Attacks (J-TLGA), which collaboratively perturb both routers and experts. This joint attack significantly amplifies adversarial effects and exposes the Achilles' Heel (collaborative weaknesses) of the MoE architecture. Based on these insights, we further propose Joint Temporal Lipschitz Adversarial Training (J-TLAT). J-TLAT performs joint training to further defend against collaborative weaknesses, enhancing component-wise robustness. Our framework is plug-and-play and reduces inference cost by more than 60% compared with dense models. It consistently enhances adversarial robustness across diverse datasets and architectures, effectively mitigating both the independent and collaborative weaknesses of MoE.
SafeRBench: A Comprehensive Benchmark for Safety Assessment in Large Reasoning Models
Nov 19, 2025Large Reasoning Models (LRMs) improve answer quality through explicit chain-of-thought, yet this very capability introduces new safety risks: harmful content can be subtly injected, surface gradually, or be justified by misleading rationales within the reasoning trace. Existing safety evaluations, however, primarily focus on output-level judgments and rarely capture these dynamic risks along the reasoning process. In this paper, we present SafeRBench, the first benchmark that assesses LRM safety end-to-end -- from inputs and intermediate reasoning to final outputs. (1) Input Characterization: We pioneer the incorporation of risk categories and levels into input design, explicitly accounting for affected groups and severity, and thereby establish a balanced prompt suite reflecting diverse harm gradients. (2) Fine-Grained Output Analysis: We introduce a micro-thought chunking mechanism to segment long reasoning traces into semantically coherent units, enabling fine-grained evaluation across ten safety dimensions. (3) Human Safety Alignment: We validate LLM-based evaluations against human annotations specifically designed to capture safety judgments. Evaluations on 19 LRMs demonstrate that SafeRBench enables detailed, multidimensional safety assessment, offering insights into risks and protective mechanisms from multiple perspectives.
Distributional Multi-objective Black-box Optimization for Diffusion-model Inference-time Multi-Target Generation
Oct 30, 2025Diffusion models have been successful in learning complex data distributions. This capability has driven their application to high-dimensional multi-objective black-box optimization problem. Existing approaches often employ an external optimization loop, such as an evolutionary algorithm, to the diffusion model. However, these approaches treat the diffusion model as a black-box refiner, which overlooks the internal distribution transition of the diffusion generation process, limiting their efficiency. To address these challenges, we propose the Inference-time Multi-target Generation (IMG) algorithm, which optimizes the diffusion process at inference-time to generate samples that simultaneously satisfy multiple objectives. Specifically, our IMG performs weighted resampling during the diffusion generation process according to the expected aggregated multi-objective values. This weighted resampling strategy ensures the diffusion-generated samples are distributed according to our desired multi-target Boltzmann distribution. We further derive that the multi-target Boltzmann distribution has an interesting log-likelihood interpretation, where it is the optimal solution to the distributional multi-objective optimization problem. We implemented IMG for a multi-objective molecule generation task. Experiments show that IMG, requiring only a single generation pass, achieves a significantly higher hypervolume than baseline optimization algorithms that often require hundreds of diffusion generations. Notably, our algorithm can be viewed as an optimized diffusion process and can be integrated into existing methods to further improve their performance.
Instant Preference Alignment for Text-to-Image Diffusion Models
Aug 25, 2025Text-to-image (T2I) generation has greatly enhanced creative expression, yet achieving preference-aligned generation in a real-time and training-free manner remains challenging. Previous methods often rely on static, pre-collected preferences or fine-tuning, limiting adaptability to evolving and nuanced user intents. In this paper, we highlight the need for instant preference-aligned T2I generation and propose a training-free framework grounded in multimodal large language model (MLLM) priors. Our framework decouples the task into two components: preference understanding and preference-guided generation. For preference understanding, we leverage MLLMs to automatically extract global preference signals from a reference image and enrich a given prompt using structured instruction design. Our approach supports broader and more fine-grained coverage of user preferences than existing methods. For preference-guided generation, we integrate global keyword-based control and local region-aware cross-attention modulation to steer the diffusion model without additional training, enabling precise alignment across both global attributes and local elements. The entire framework supports multi-round interactive refinement, facilitating real-time and context-aware image generation. Extensive experiments on the Viper dataset and our collected benchmark demonstrate that our method outperforms prior approaches in both quantitative metrics and human evaluations, and opens up new possibilities for dialog-based generation and MLLM-diffusion integration.
LLM-to-Phy3D: Physically Conform Online 3D Object Generation with LLMs
Jun 11, 2025
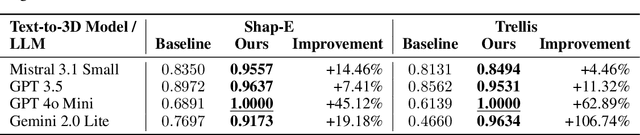
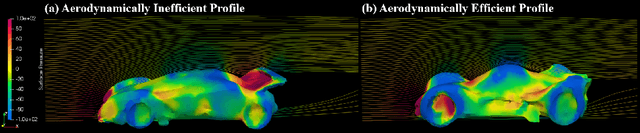
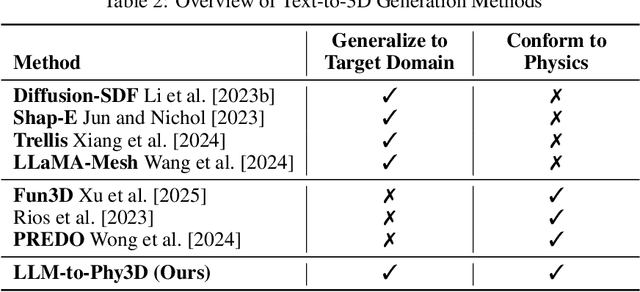
The emergence of generative artificial intelligence (GenAI) and large language models (LLMs) has revolutionized the landscape of digital content creation in different modalities. However, its potential use in Physical AI for engineering design, where the production of physically viable artifacts is paramount, remains vastly underexplored. The absence of physical knowledge in existing LLM-to-3D models often results in outputs detached from real-world physical constraints. To address this gap, we introduce LLM-to-Phy3D, a physically conform online 3D object generation that enables existing LLM-to-3D models to produce physically conforming 3D objects on the fly. LLM-to-Phy3D introduces a novel online black-box refinement loop that empowers large language models (LLMs) through synergistic visual and physics-based evaluations. By delivering directional feedback in an iterative refinement process, LLM-to-Phy3D actively drives the discovery of prompts that yield 3D artifacts with enhanced physical performance and greater geometric novelty relative to reference objects, marking a substantial contribution to AI-driven generative design. Systematic evaluations of LLM-to-Phy3D, supported by ablation studies in vehicle design optimization, reveal various LLM improvements gained by 4.5% to 106.7% in producing physically conform target domain 3D designs over conventional LLM-to-3D models. The encouraging results suggest the potential general use of LLM-to-Phy3D in Physical AI for scientific and engineering applications.
An Effective End-to-End Solution for Multimodal Action Recognition
Jun 11, 2025Recently, multimodal tasks have strongly advanced the field of action recognition with their rich multimodal information. However, due to the scarcity of tri-modal data, research on tri-modal action recognition tasks faces many challenges. To this end, we have proposed a comprehensive multimodal action recognition solution that effectively utilizes multimodal information. First, the existing data are transformed and expanded by optimizing data enhancement techniques to enlarge the training scale. At the same time, more RGB datasets are used to pre-train the backbone network, which is better adapted to the new task by means of transfer learning. Secondly, multimodal spatial features are extracted with the help of 2D CNNs and combined with the Temporal Shift Module (TSM) to achieve multimodal spatial-temporal feature extraction comparable to 3D CNNs and improve the computational efficiency. In addition, common prediction enhancement methods, such as Stochastic Weight Averaging (SWA), Ensemble and Test-Time augmentation (TTA), are used to integrate the knowledge of models from different training periods of the same architecture and different architectures, so as to predict the actions from different perspectives and fully exploit the target information. Ultimately, we achieved the Top-1 accuracy of 99% and the Top-5 accuracy of 100% on the competition leaderboard, demonstrating the superiority of our solution.