 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Multi-objective Black-box Optimization for Diffusion-model Inference-time Multi-Target Generation
Oct 30, 2025Diffusion models have been successful in learning complex data distributions. This capability has driven their application to high-dimensional multi-objective black-box optimization problem. Existing approaches often employ an external optimization loop, such as an evolutionary algorithm, to the diffusion model. However, these approaches treat the diffusion model as a black-box refiner, which overlooks the internal distribution transition of the diffusion generation process, limiting their efficiency. To address these challenges, we propose the Inference-time Multi-target Generation (IMG) algorithm, which optimizes the diffusion process at inference-time to generate samples that simultaneously satisfy multiple objectives. Specifically, our IMG performs weighted resampling during the diffusion generation process according to the expected aggregated multi-objective values. This weighted resampling strategy ensures the diffusion-generated samples are distributed according to our desired multi-target Boltzmann distribution. We further derive that the multi-target Boltzmann distribution has an interesting log-likelihood interpretation, where it is the optimal solution to the distributional multi-objective optimization problem. We implemented IMG for a multi-objective molecule generation task. Experiments show that IMG, requiring only a single generation pass, achieves a significantly higher hypervolume than baseline optimization algorithms that often require hundreds of diffusion generations. Notably, our algorithm can be viewed as an optimized diffusion process and can be integrated into existing methods to further improve their performance.
Fast Direct: Query-Efficient Online Black-box Guidance for Diffusion-model Target Generation
Feb 02, 2025Guided diffusion-model generation is a promising direction for customizing the generation process of a pre-trained diffusion-model to address the specific downstream tasks. Existing guided diffusion models either rely on training of the guidance model with pre-collected datasets or require the objective functions to be differentiable. However, for most real-world tasks, the offline datasets are often unavailable, and their objective functions are often not differentiable, such as image generation with human preferences, molecular generation for drug discovery, and material design. Thus, we need an \textbf{online} algorithm capable of collecting data during runtime and supporting a \textbf{black-box} objective function. Moreover, the \textbf{query efficiency} of the algorithm is also critical because the objective evaluation of the query is often expensive in the real-world scenarios. In this work, we propose a novel and simple algorithm, \textbf{Fast Direct}, for query-efficient online black-box target generation. Our Fast Direct builds a pseudo-target on the data manifold to update the noise sequence of the diffusion model with a universal direction, which is promising to perform query-efficient guided generation. Extensive experiments on twelve high-resolution ($\small {1024 \times 1024}$) image target generation tasks and six 3D-molecule target generation tasks show $\textbf{6}\times$ up to $\textbf{10}\times$ query efficiency improvement and $\textbf{11}\times$ up to $\textbf{44}\times$ query efficiency improvement, respectively. Our implementation is publicly available at: https://github.com/kimyong95/guide-stable-diffusion/tree/fast-direct
Covariance-Adaptive Sequential Black-box Optimization for Diffusion Targeted Generation
Jun 02, 2024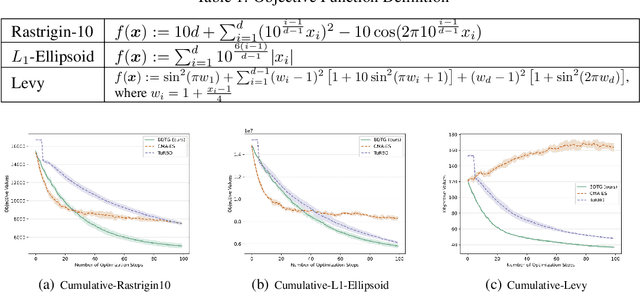
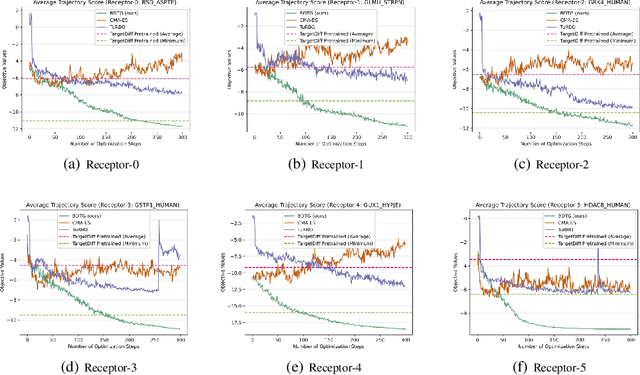
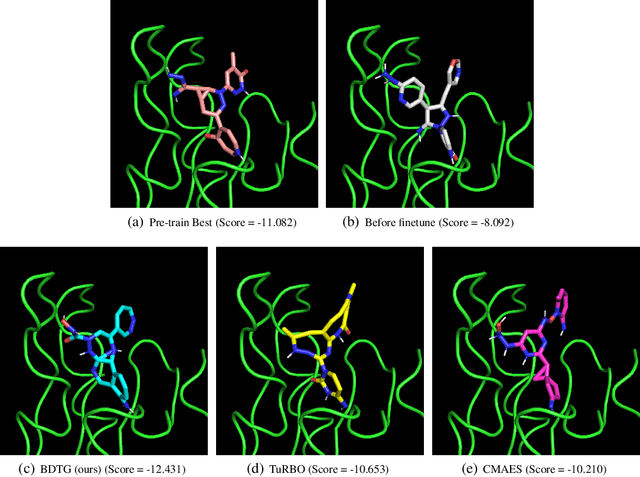
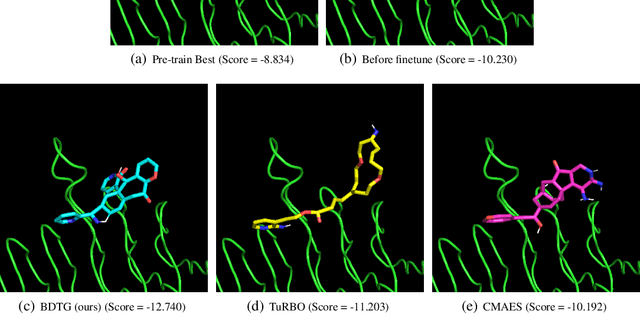
Diffusion models have demonstrated great potential in generating high-quality content for images, natural language, protein domains, etc. However, how to perform user-preferred targeted generation via diffusion models with only black-box target scores of users remains challenging. To address this issue, we first formulate the fine-tuning of the targeted reserve-time stochastic differential equation (SDE) associated with a pre-trained diffusion model as a sequential black-box optimization problem. Furthermore, we propose a novel covariance-adaptive sequential optimization algorithm to optimize cumulative black-box scores under unknown transition dynamics. Theoretically, we prove a $O(\frac{d^2}{\sqrt{T}})$ convergence rate for cumulative convex functions without smooth and strongly convex assumptions. Empirically, experiments on both numerical test problems and target-guided 3D-molecule generation tasks show the superior performance of our method in achieving better target scores.
Unfolded Self-Reconstruction LSH: Towards Machine Unlearning in Approximate Nearest Neighbour Search
Apr 06, 2023Approximate nearest neighbour (ANN) search is an essential component of search engines, recommendation systems, etc. Many recent works focus on learning-based data-distribution-dependent hashing and achieve good retrieval performance. However, due to increasing demand for users' privacy and security, we often need to remove users' data information from Machine Learning (ML) models to satisfy specific privacy and security requirements. This need requires the ANN search algorithm to support fast online data deletion and insertion. Current learning-based hashing methods need retraining the hash function, which is prohibitable due to the vast time-cost of large-scale data. To address this problem, we propose a novel data-dependent hashing method named unfolded self-reconstruction locality-sensitive hashing (USR-LSH). Our USR-LSH unfolded the optimization update for instance-wise data reconstruction, which is better for preserving data information than data-independent LSH. Moreover, our USR-LSH supports fast online data deletion and insertion without retraining. To the best of our knowledge, we are the first to address the machine unlearning of retrieval problems. Empirically, we demonstrate that USR-LSH outperforms the state-of-the-art data-distribution-independent LSH in ANN tasks in terms of precision and recall. We also show that USR-LSH has significantly faster data deletion and insertion time than learning-based data-dependent hashing.