 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA H.265/HEVC Fine-Grained ROI Video Encryption Algorithm Based on Coding Unit and Prompt Segmentation
Apr 09, 2026ROI (Region of Interest) video selective encryption based on H.265/HEVC is a technology that protects the sensitive regions of videos by perturbing the syntax elements associated with target areas. However, existing methods typically adopt Tile (with a relatively large size) as the minimum encryption unit, which suffers from problems such as inaccurate encryption regions and low encryption precision. This low-precision encryption makes them difficult to apply in sensitive fields such as medicine, military, and remote sensing. In order to address the aforementioned problem, this paper proposes a fine-grained ROI video selective encryption algorithm based on Coding Units (CUs) and prompt segmentation. First, to achieve a more precise ROI acquisition, we present a novel ROI mapping approach based on prompt segmentation. This approach enables precise mapping of ROIs to small $8\times8$ CU levels, significantly enhancing the precision of encrypted regions. Second, we propose a selective encryption scheme based on multiple syntax elements, which distorts syntax elements within high-precision ROI to effectively safeguard ROI security. Finally, we design a diffusion isolation based on Pulse Code Modulation (PCM) mode and MV restriction, applying PCM mode and MV restriction strategy to the affected CU to address encryption diffusion during prediction. The above three strategies break the inherent mechanism of using Tiles in existing ROI encryption and push the fine-grained level of ROI video encryption to the minimum $8\times8$ CU precision. The experimental results demonstrate that the proposed algorithm can accurately segment ROI regions, effectively perturb pixels within these regions, and eliminate the diffusion artifacts introduced by encryption. The method exhibits great potential for application in medical imaging, military surveillance, and remote areas.
H.265/HEVC Video Steganalysis Based on CU Block Structure Gradients and IPM Mapping
Feb 12, 2026Existing H.265/HEVC video steganalysis research mainly focuses on statistical feature modeling at the levels of motion vectors (MV), intra prediction modes (IPM), or transform coefficients. In contrast, studies targeting the coding-structure level - especially the analysis of block-level steganographic behaviors in Coding Units (CUs) - remain at an early stage. As a core component of H.265/HEVC coding decisions, the CU partition structure often exhibits steganographic perturbations in the form of structural changes and reorganization of prediction relationships, which are difficult to characterize effectively using traditional pixel-domain features or mode statistics. To address this issue, this paper, for the first time from the perspective of CU block-level steganalysis, proposes an H.265/HEVC video steganalysis method based on CU block-structure gradients and intra prediction mode mapping. The proposed method constructs a CU block-structure gradient map to explicitly describe changes in coding-unit partitioning, and combines it with a block-level mapping representation of IPM to jointly model the structural perturbations introduced by CU-level steganographic embedding. On this basis, we design a Transformer network, GradIPMFormer, tailored for CU-block steganalysis, thereby effectively enhancing the capability to perceive CU-level steganographic behaviors. Experimental results show that under different quantization parameters and resolution settings, the proposed method consistently achieves superior detection performance across multiple H.265/HEVC steganographic algorithms, validating the feasibility and effectiveness of conducting video steganalysis from the coding-structure perspective. This study provides a new CU block-level analysis paradigm for H.265/HEVC video steganalysis and has significant research value for covert communication security detection.
Exposing and Defending the Achilles' Heel of Video Mixture-of-Experts
Feb 01, 2026Mixture-of-Experts (MoE) has demonstrated strong performance in video understanding tasks, yet its adversarial robustness remains underexplored. Existing attack methods often treat MoE as a unified architecture, overlooking the independent and collaborative weaknesses of key components such as routers and expert modules. To fill this gap, we propose Temporal Lipschitz-Guided Attacks (TLGA) to thoroughly investigate component-level vulnerabilities in video MoE models. We first design attacks on the router, revealing its independent weaknesses. Building on this, we introduce Joint Temporal Lipschitz-Guided Attacks (J-TLGA), which collaboratively perturb both routers and experts. This joint attack significantly amplifies adversarial effects and exposes the Achilles' Heel (collaborative weaknesses) of the MoE architecture. Based on these insights, we further propose Joint Temporal Lipschitz Adversarial Training (J-TLAT). J-TLAT performs joint training to further defend against collaborative weaknesses, enhancing component-wise robustness. Our framework is plug-and-play and reduces inference cost by more than 60% compared with dense models. It consistently enhances adversarial robustness across diverse datasets and architectures, effectively mitigating both the independent and collaborative weaknesses of MoE.
From Spurious to Causal: Low-rank Orthogonal Subspace Intervention for Generalizable Face Forgery Detection
Jan 17, 2026The generalization problem remains a critical challenge in face forgery detection. Some researches have discovered that ``a backdoor path" in the representations from forgery-irrelevant information to labels induces biased learning, thereby hindering the generalization. In this paper, these forgery-irrelevant information are collectively termed spurious correlations factors. Previous methods predominantly focused on identifying concrete, specific spurious correlation and designing corresponding solutions to address them. However, spurious correlations arise from unobservable confounding factors, making it impractical to identify and address each one individually. To address this, we propose an intervention paradigm for representation space. Instead of tracking and blocking various instance-level spurious correlation one by one, we uniformly model them as a low-rank subspace and intervene in them. Specifically, we decompose spurious correlation features into a low-rank subspace via orthogonal low-rank projection, subsequently removing this subspace from the original representation and training its orthogonal complement to capture forgery-related features. This low-rank projection removal effectively eliminates spurious correlation factors, ensuring that classification decision is based on authentic forgery cues. With only 0.43M trainable parameters, our method achieves state-of-the-art performance across several benchmarks, demonstrating excellent robustness and generalization.
Decoding RobKiNet: Insights into Efficient Training of Robotic Kinematics Informed Neural Network
Sep 09, 2025In robots task and motion planning (TAMP), it is crucial to sample within the robot's configuration space to meet task-level global constraints and enhance the efficiency of subsequent motion planning. Due to the complexity of joint configuration sampling under multi-level constraints, traditional methods often lack efficiency. This paper introduces the principle of RobKiNet, a kinematics-informed neural network, for end-to-end sampling within the Continuous Feasible Set (CFS) under multiple constraints in configuration space, establishing its Optimization Expectation Model. Comparisons with traditional sampling and learning-based approaches reveal that RobKiNet's kinematic knowledge infusion enhances training efficiency by ensuring stable and accurate gradient optimization.Visualizations and quantitative analyses in a 2-DOF space validate its theoretical efficiency, while its application on a 9-DOF autonomous mobile manipulator robot(AMMR) demonstrates superior whole-body and decoupled control, excelling in battery disassembly tasks. RobKiNet outperforms deep reinforcement learning with a training speed 74.29 times faster and a sampling accuracy of up to 99.25%, achieving a 97.33% task completion rate in real-world scenarios.
Is Artificial Intelligence Generated Image Detection a Solved Problem?
May 18, 2025



The rapid advancement of generative models, such as GANs and Diffusion models, has enabled the creation of highly realistic synthetic images, raising serious concerns about misinformation, deepfakes, and copyright infringement. Although numerous Artificial Intelligence Generated Image (AIGI) detectors have been proposed, often reporting high accuracy, their effectiveness in real-world scenarios remains questionable. To bridge this gap, we introduce AIGIBench, a comprehensive benchmark designed to rigorously evaluate the robustness and generalization capabilities of state-of-the-art AIGI detectors. AIGIBench simulates real-world challenges through four core tasks: multi-source generalization, robustness to image degradation, sensitivity to data augmentation, and impact of test-time pre-processing. It includes 23 diverse fake image subsets that span both advanced and widely adopted image generation techniques, along with real-world samples collected from social media and AI art platforms. Extensive experiments on 11 advanced detectors demonstrate that, despite their high reported accuracy in controlled settings, these detectors suffer significant performance drops on real-world data, limited benefits from common augmentations, and nuanced effects of pre-processing, highlighting the need for more robust detection strategies. By providing a unified and realistic evaluation framework, AIGIBench offers valuable insights to guide future research toward dependable and generalizable AIGI detection.
Fast Adversarial Training with Weak-to-Strong Spatial-Temporal Consistency in the Frequency Domain on Videos
Apr 21, 2025Adversarial Training (AT) has been shown to significantly enhance adversarial robustness via a min-max optimization approach. However, its effectiveness in video recognition tasks is hampered by two main challenges. First, fast adversarial training for video models remains largely unexplored, which severely impedes its practical applications. Specifically, most video adversarial training methods are computationally costly, with long training times and high expenses. Second, existing methods struggle with the trade-off between clean accuracy and adversarial robustness. To address these challenges, we introduce Video Fast Adversarial Training with Weak-to-Strong consistency (VFAT-WS), the first fast adversarial training method for video data. Specifically, VFAT-WS incorporates the following key designs: First, it integrates a straightforward yet effective temporal frequency augmentation (TF-AUG), and its spatial-temporal enhanced form STF-AUG, along with a single-step PGD attack to boost training efficiency and robustness. Second, it devises a weak-to-strong spatial-temporal consistency regularization, which seamlessly integrates the simpler TF-AUG and the more complex STF-AUG. Leveraging the consistency regularization, it steers the learning process from simple to complex augmentations. Both of them work together to achieve a better trade-off between clean accuracy and robustness. Extensive experiments on UCF-101 and HMDB-51 with both CNN and Transformer-based models demonstrate that VFAT-WS achieves great improvements in adversarial robustness and corruption robustness, while accelerating training by nearly 490%.
Generalizable Deepfake Detection via Effective Local-Global Feature Extraction
Jan 25, 2025



The rapid advancement of GANs and diffusion models has led to the generation of increasingly realistic fake images, posing significant hidden dangers and threats to society. Consequently, deepfake detection has become a pressing issue in today's world. While some existing methods focus on forgery features from either a local or global perspective, they often overlook the complementary nature of these features. Other approaches attempt to incorporate both local and global features but rely on simplistic strategies, such as cropping, which fail to capture the intricate relationships between local features. To address these limitations, we propose a novel method that effectively combines local spatial-frequency domain features with global frequency domain information, capturing detailed and holistic forgery traces. Specifically, our method uses Discrete Wavelet Transform (DWT) and sliding windows to tile forged features and leverages attention mechanisms to extract local spatial-frequency domain information. Simultaneously, the phase component of the Fast Fourier Transform (FFT) is integrated with attention mechanisms to extract global frequency domain information, complementing the local features and ensuring the integrity of forgery detection. Comprehensive evaluations on open-world datasets generated by 34 distinct generative models demonstrate a significant improvement of 2.9% over existing state-of-the-art methods.
Counterfactual Explanations for Face Forgery Detection via Adversarial Removal of Artifacts
Apr 12, 2024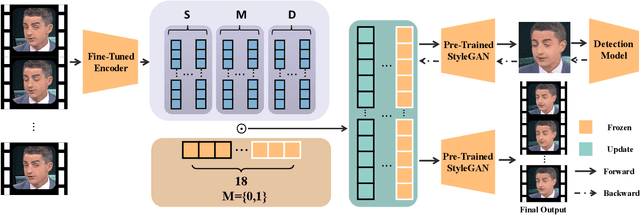
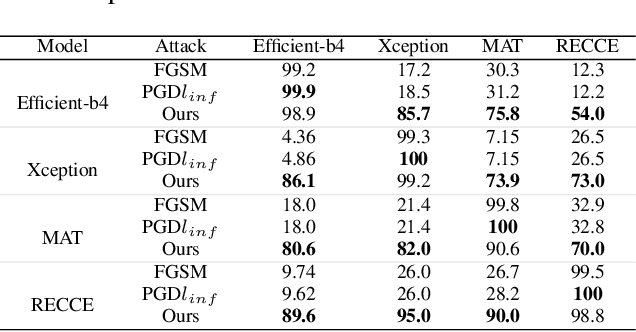
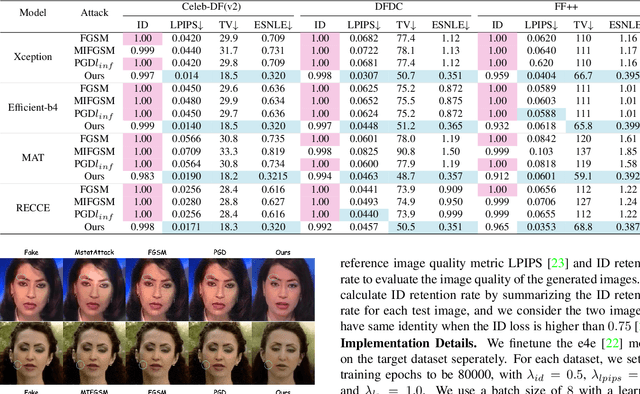
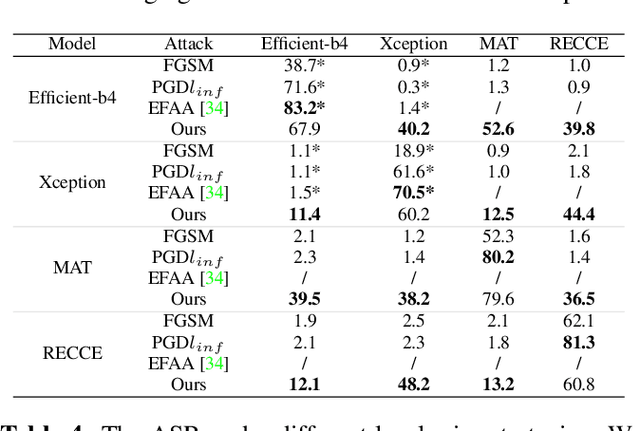
Highly realistic AI generated face forgeries known as deepfakes have raised serious social concerns. Although DNN-based face forgery detection models have achieved good performance, they are vulnerable to latest generative methods that have less forgery traces and adversarial attacks. This limitation of generalization and robustness hinders the credibility of detection results and requires more explanations. In this work, we provide counterfactual explanations for face forgery detection from an artifact removal perspective. Specifically, we first invert the forgery images into the StyleGAN latent space, and then adversarially optimize their latent representations with the discrimination supervision from the target detection model. We verify the effectiveness of the proposed explanations from two aspects: (1) Counterfactual Trace Visualization: the enhanced forgery images are useful to reveal artifacts by visually contrasting the original images and two different visualization methods; (2) Transferable Adversarial Attacks: the adversarial forgery images generated by attacking the detection model are able to mislead other detection models, implying the removed artifacts are general. Extensive experiments demonstrate that our method achieves over 90% attack success rate and superior attack transferability. Compared with naive adversarial noise methods, our method adopts both generative and discriminative model priors, and optimize the latent representations in a synthesis-by-analysis way, which forces the search of counterfactual explanations on the natural face manifold. Thus, more general counterfactual traces can be found and better adversarial attack transferability can be achieved.
Is It Possible to Backdoor Face Forgery Detection with Natural Triggers?
Dec 31, 2023Deep neural networks have significantly improved the performance of face forgery detection models in discriminating Artificial Intelligent Generated Content (AIGC). However, their security is significantly threatened by the injection of triggers during model training (i.e., backdoor attacks). Although existing backdoor defenses and manual data selection can mitigate those using human-eye-sensitive triggers, such as patches or adversarial noises, the more challenging natural backdoor triggers remain insufficiently researched. To further investigate natural triggers, we propose a novel analysis-by-synthesis backdoor attack against face forgery detection models, which embeds natural triggers in the latent space. We thoroughly study such backdoor vulnerability from two perspectives: (1) Model Discrimination (Optimization-Based Trigger): we adopt a substitute detection model and find the trigger by minimizing the cross-entropy loss; (2) Data Distribution (Custom Trigger): we manipulate the uncommon facial attributes in the long-tailed distribution to generate poisoned samples without the supervision from detection models. Furthermore, to completely evaluate the detection models towards the latest AIGC, we utilize both state-of-the-art StyleGAN and Stable Diffusion for trigger generation. Finally, these backdoor triggers introduce specific semantic features to the generated poisoned samples (e.g., skin textures and smile), which are more natural and robust. Extensive experiments show that our method is superior from three levels: (1) Attack Success Rate: ours achieves a high attack success rate (over 99%) and incurs a small model accuracy drop (below 0.2%) with a low poisoning rate (less than 3%); (2) Backdoor Defense: ours shows better robust performance when faced with existing backdoor defense methods; (3) Human Inspection: ours is less human-eye-sensitive from a comprehensive user study.