 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Ensemble Method for Concessively Targeted Multi-model Attack
Paper and Code
Dec 19, 2019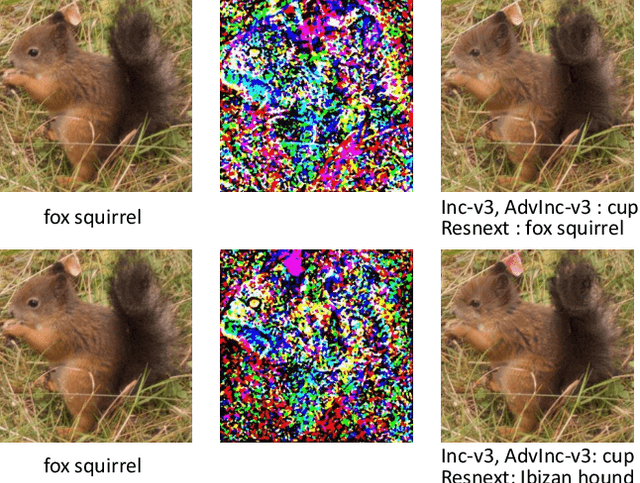



It is well known that deep learning models are vulnerable to adversarial examples crafted by maliciously adding perturbations to original inputs. There are two types of attacks: targeted attack and non-targeted attack, and most researchers often pay more attention to the targeted adversarial examples. However, targeted attack has a low success rate, especially when aiming at a robust model or under a black-box attack protocol. In this case, non-targeted attack is the last chance to disable AI systems. Thus, in this paper, we propose a new attack mechanism which performs the non-targeted attack when the targeted attack fails. Besides, we aim to generate a single adversarial sample for different deployed models of the same task, e.g. image classification models. Hence, for this practical application, we focus on attacking ensemble models by dividing them into two groups: easy-to-attack and robust models. We alternately attack these two groups of models in the non-targeted or targeted manner. We name it a bagging and stacking ensemble (BAST) attack. The BAST attack can generate an adversarial sample that fails multiple models simultaneously. Some of the models classify the adversarial sample as a target label, and other models which are not attacked successfully may give wrong labels at least. The experimental results show that the proposed BAST attack outperforms the state-of-the-art attack methods on the new defined criterion that considers both targeted and non-targeted attack performance.